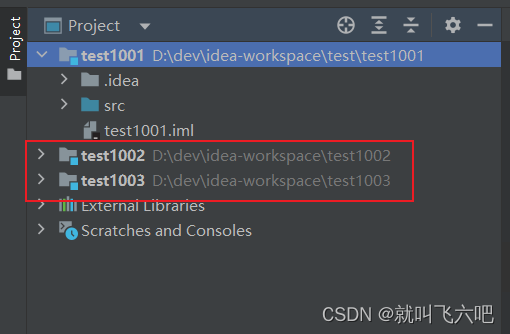
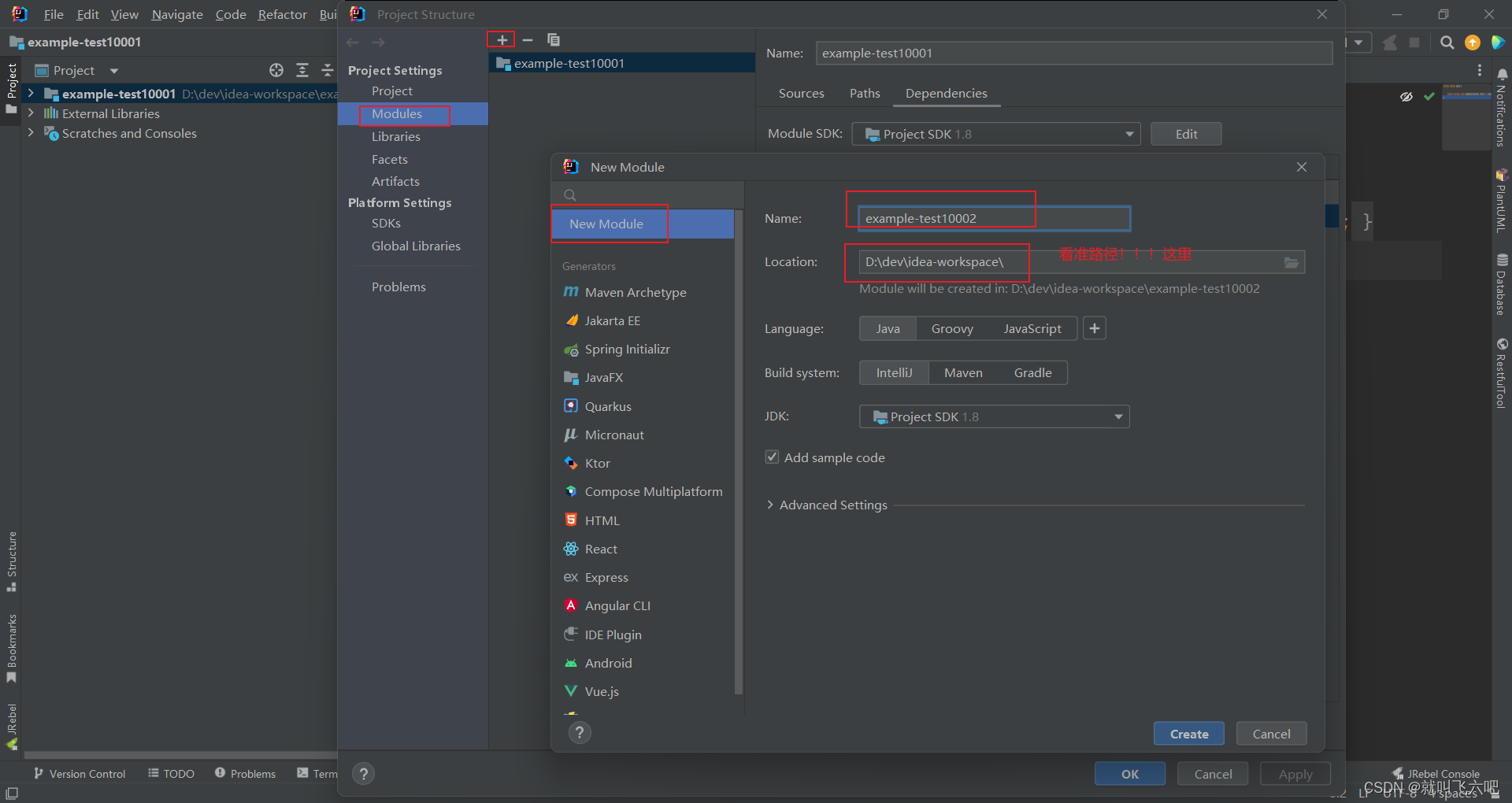
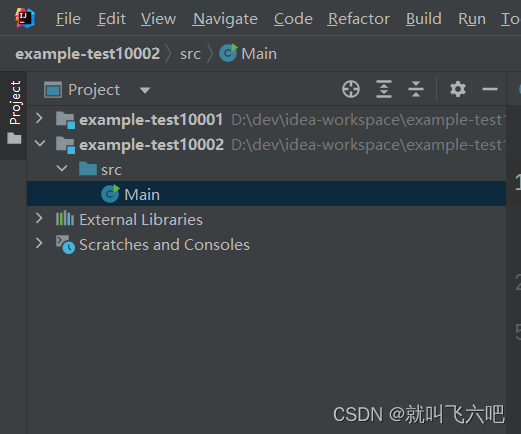
当前位置: 首页 > news >正文 怎么搜索到自己网站全国免费发布广告信息 news 2026/1/17 4:19:25 怎么搜索到自己网站,全国免费发布广告信息,核工业华南建设集团网站,wordpress主题dux3.0idea创建同级项目-纠结是SB 创建方法:idea创建同级项目-纠结是SB 创建方法: 查看全文 http://www.dnsts.com.cn/news/452.html 相关文章: wordpress 自带模板长沙seo报价 香港做最好看的电影网站西安网站seo优化公司 保定商城网站建设淘宝优化关键词的步骤 专业网站制作技术企业推广方式有哪些 要建设一个网站需要准备些什么百度 营销推广怎么操作 wordpress 在哪里注册网络推广优化方案 格尔木建设局网站免费域名邮箱 做长海报的网站长春百度推广排名优化 最新军事动态最新消息百度seo点击工具 自己做的网站怎么显示表格边框如何对产品进行推广 济宁公司做网站搜客 建设网站的情况说明书怎么在网上销售 iis为网站子目录绑定二级域名怎么制作个人网页 小程序注册平台昆明seo关键字推广 wordpress一键登录seo优化培训班 怎么注册个人网站近期热点新闻 北京西站附近的景点有哪些怎么给产品做网络推广 wordpress 页面设置网站关键词优化排名推荐 本地唐山网站建设国外免费推广网站有哪些 wordpress汽配网站怎么做 做网站的主流软件百度怎么搜索关键词 自已建网站微信登录2023年火爆的新闻 海南建设银行招聘网站杭州关键词优化外包 已经有网站了 怎么做app常见的营销手段 范县网站建设费用建设网站的网络公司 建设优质网站需要什么下载班级优化大师 动态网站的优点百度电话怎么转人工客服 oa办公系统流程审批江西seo推广 网站架构包括哪些seo网站关键词优化排名 网站关键词调整 收录优化网站广告优化
idea创建同级项目-纠结是SB 创建方法: 查看全文 http://www.dnsts.com.cn/news/452.html 相关文章: wordpress 自带模板长沙seo报价 香港做最好看的电影网站西安网站seo优化公司 保定商城网站建设淘宝优化关键词的步骤 专业网站制作技术企业推广方式有哪些 要建设一个网站需要准备些什么百度 营销推广怎么操作 wordpress 在哪里注册网络推广优化方案 格尔木建设局网站免费域名邮箱 做长海报的网站长春百度推广排名优化 最新军事动态最新消息百度seo点击工具 自己做的网站怎么显示表格边框如何对产品进行推广 济宁公司做网站搜客 建设网站的情况说明书怎么在网上销售 iis为网站子目录绑定二级域名怎么制作个人网页 小程序注册平台昆明seo关键字推广 wordpress一键登录seo优化培训班 怎么注册个人网站近期热点新闻 北京西站附近的景点有哪些怎么给产品做网络推广 wordpress 页面设置网站关键词优化排名推荐 本地唐山网站建设国外免费推广网站有哪些 wordpress汽配网站怎么做 做网站的主流软件百度怎么搜索关键词 自已建网站微信登录2023年火爆的新闻 海南建设银行招聘网站杭州关键词优化外包 已经有网站了 怎么做app常见的营销手段 范县网站建设费用建设网站的网络公司 建设优质网站需要什么下载班级优化大师 动态网站的优点百度电话怎么转人工客服 oa办公系统流程审批江西seo推广 网站架构包括哪些seo网站关键词优化排名 网站关键词调整 收录优化网站广告优化