教做粥的网站淘宝seo搜索优化工具
在现代工业和科研中,图像处理技术被广泛应用于质量检测、自动化控制、机器人导航等领域。然而,随着图像数据量的增加,传统的CPU处理方式可能难以满足实时性和高效处理的需求。LabVIEW通过结合NI Vision模块和FPGA硬件平台,可以显著提高图像处理任务的执行效率,尤其适用于大数据量的图像处理任务。本文将从多个角度深入探讨如何利用LabVIEW进行图像处理加速,并结合具体的应用场景和案例进行说明。
1. LabVIEW结合NI Vision模块
NI Vision Development Module是NI推出的专业图像处理库,支持各类常见的图像处理算法,如图像过滤、形态学操作、边缘检测、模板匹配等。它可以直接在LabVIEW环境中调用,提供了图形化的编程接口,方便工程师快速构建图像处理应用。NI Vision模块的特点包括:
-
丰富的图像处理函数库:支持2D、3D图像处理,涵盖从基本的滤波、增强到高级的机器视觉算法。
-
与硬件无缝集成:支持与NI硬件如相机、数据采集卡和FPGA无缝连接,极大简化了图像采集和处理的流程。
然而,随着图像分辨率和处理复杂度的提高,基于CPU的图像处理可能遇到瓶颈,尤其在需要实时处理的场景下,如高速运动目标的跟踪和检测。
2. FPGA硬件加速
FPGA(Field-Programmable Gate Array)作为一种可编程硬件,擅长并行处理任务,特别适用于实时性要求高、数据吞吐量大的任务。利用FPGA进行图像处理加速可以有效缓解CPU的负载。其优势包括:
-
硬件级并行处理:FPGA支持同时对多帧图像或多个像素进行并行处理,极大提升了图像处理速度。
-
实时响应:FPGA的低延迟特性确保了在高频采样下实时处理图像数据,适合工业检测、自动控制等对延迟敏感的应用。
-
可编程性:FPGA通过LabVIEW FPGA模块进行编程,用户可以根据实际需求灵活调整硬件处理逻辑,避免传统硬件处理器的固定架构限制。
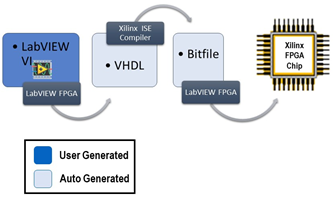
3. LabVIEW与FPGA结合的图像处理流程
在LabVIEW中,利用LabVIEW FPGA模块可以将部分耗时的图像处理任务下放到FPGA执行,从而加速整个系统的处理能力。典型的工作流程如下:
-
图像采集:通过NI的视觉硬件(如工业相机或Frame Grabber卡),采集原始图像。
-
预处理:在LabVIEW中使用NI Vision模块对图像进行初步处理(如去噪、增强等)。
-
数据下放到FPGA:利用FPGA处理图像中的关键任务,如卷积操作、快速傅里叶变换(FFT)、图像滤波等。LabVIEW FPGA模块允许用户以图形化方式配置FPGA上的逻辑电路。
-
数据回传与显示:处理后的图像或数据回传给LabVIEW,进行进一步的分析或显示。
4. 实际应用案例
为了更好地说明FPGA图像处理的优势,我们可以参考以下应用案例:
案例1:机器视觉中的高速检测在生产流水线中,需要对高速通过的产品进行实时检测。如果依靠传统的CPU进行处理,由于图像分辨率高、帧率大,可能无法满足实时性的要求。此时,利用FPGA并行处理多个像素点的优势,可以实时进行缺陷检测、边缘识别等任务。通过LabVIEW的Vision模块进行图像预处理,再将关键算法如边缘检测、形态学操作下放到FPGA,可以确保系统在高速运行的同时保持高精度的检测效果。
案例2:自动驾驶中的实时环境感知在自动驾驶系统中,环境感知模块需要处理大量摄像头、激光雷达的数据。图像数据的实时性直接影响了车辆的安全性和决策效率。通过FPGA加速处理图像中的物体检测、障碍物识别等任务,可以大幅提升自动驾驶系统的响应速度。此外,LabVIEW与FPGA的结合还支持多传感器数据融合,进一步提高了环境感知的准确性和实时性。
5. 如何优化开发流程
结合FPGA进行图像处理加速虽然有显著的性能提升,但开发过程中需要注意以下几点:
-
算法设计与FPGA资源平衡:在开发过程中,应将计算密集型、适合并行化的算法下放到FPGA执行,而非全部任务都交给FPGA处理。合理的算法设计可以平衡FPGA资源的使用,避免资源浪费或溢出。
-
硬件调试与验证:FPGA的调试相较于软件而言更为复杂,因此在开发过程中应充分利用LabVIEW FPGA中的仿真工具,提前发现并解决潜在问题。
-
模块化开发:将图像处理任务划分为多个可复用模块,有助于后续的维护和功能扩展。LabVIEW的模块化编程方式非常适合这一需求。
结论
LabVIEW结合NI Vision模块和FPGA硬件平台为图像处理加速提供了高效的解决方案。通过将复杂的图像处理任务下放到FPGA执行,系统可以在保持高精度的同时,满足实时性要求。这一技术在工业自动化、机器视觉、自动驾驶等领域有广泛的应用前景。工程师在开发过程中应合理分配硬件和软件资源,结合实际应用需求,优化开发流程,最终实现高效、稳定的图像处理系统。