婚纱摄影的网站怎么做可以搜任何网站的浏览器

1 龙芯架构
PDF下载链接:
https://www.loongson.cn/download/index
1.1 龙芯架构概述
龙芯架构具有 RISC 指令架构的典型特征。 它的指令长度固定且编码格式规整, 绝大多数指令只有两个源操作数和一个目的操作数, 采用 load/store 架构, 即仅有 load/store 访存指令可以访问内存, 其它指令的操作对象均是处理器核内部的寄存器或指令码中的立即数。
龙芯架构分为 32 位和 64 位两个版本, 分别称为 LA32 架构和 LA64 架构。 LA64 架构应用级向下二进制兼容 LA32 架构。 所谓“应用级向下二进制兼容” 一方面是指采用 LA32 架构的应用软件的二进制可以直接运行在兼容 LA64 架构的机器上并获得相同的运行结果,另一方面是指这种向下二进制兼容仅限于应用软件, 架构规范并不保证在兼容 LA32 架构的机器上运行的系统软件(如操作系统内核)的二进制直接在兼容LA64 架构的机器上运行时总是获得相同的运行结果。
龙芯架构采用基础部分(Loongson Base) 加扩展部分的组织形式。 其中扩展部分包括: 二进制翻译扩展(Loongson Binary Translation, 简称 LBT)、 虚拟化扩展(Loongson Virtualization, 简称LVZ)、向量扩展(Loongson SIMD Extension,简称 LSX)和高级向量扩展(Loongson Advanced SIMD Extension,简称 LASX)。
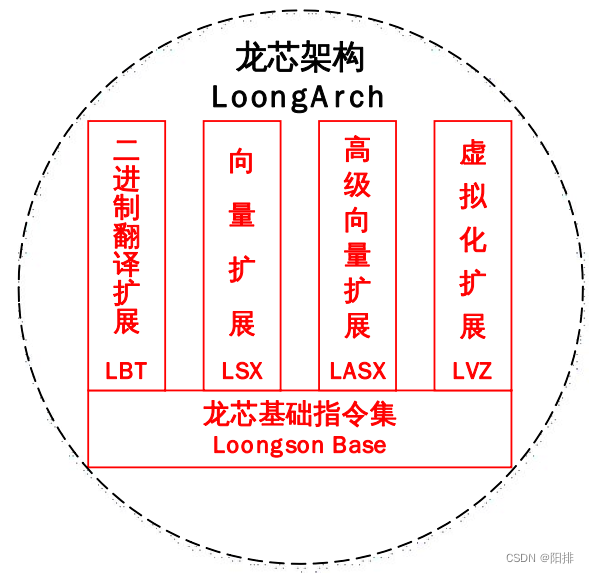
龙芯架构的基础部分包含非特权指令集和特权指令集两个部分, 其中非特权指令集部分定义了常用的整数和浮点数指令, 能够充分支持现有各主流编译系统生成高效的目标代码。 龙芯架构 32 位精简版是对LA32 基础部分的进一步简化, 目的是易于实现, 方便在教学和科研领域推广使用。
1.2 指令编码格式
龙芯架构中的所有指令均采用 32 位固定长度, 且指令的地址都要求 4 字节边界对齐。
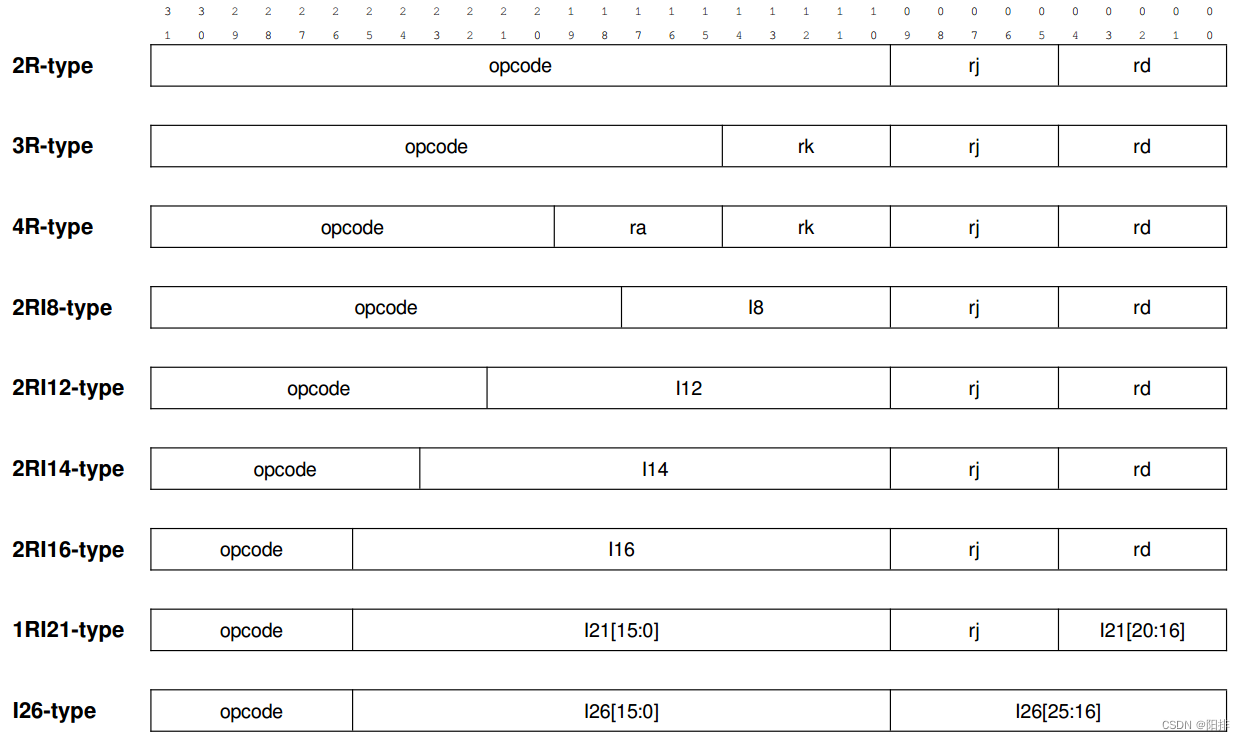
指令编码的风格是所有寄存器操作数域都从第 0 比特开始从低到高依次摆放。 操作码都是从第 31 比特开始从高到低依次摆放。 如果指令中包含有立即数操作数, 那么立即数域位于寄存器域和操作码域之间,根据不同指令类型有不同的长度。 具体来说, 包含 9 种典型的指令编码格式, 即 3 种不含立即数的编码格式 2R、 3R、 4R, 以及 6 种含立即数的编码格式 2RI8、 2RI12、 2RI14、 2RI16、 1RI21、 I26。
1.3 指令汇编助记格式
指令汇编助记格式主要包括指令名和操作数两部分。
通过指令名的前缀字母来区分非向量指令和向量指令、 整数和浮点数指令。 所有 128 位向量指令的指令名以字母“V” 开头; 所有 256 位向量指令的指令名以字母“XV” 开头。 所有非向量浮点数指令的指令名以字母“F” 开头; 所有 128 位向量浮点指令的指令名以“VF” 开头; 所有 256 位向量浮点指令的指令名以“XVF” 开头。
1.4 数据类型
基础整数指令操作的数据类型有 5 种, 分别是: 比特(bit, 简记 b)、 字节(Byte, 简记 B, 长度 8b)、半字(Halfword, 简记 H, 长度 16b)、 字(Word, 简记 W, 长度 32b)、 双字(Doubleword, 简记 D, 长度64b)。
在 LA32 架构下, 没有操作双字的整数指令。
字节、 半字、 字和双字数据类型均采用二进制补码的编码方式。
对于操作对象是整数类型的,指令名后缀为.B、.H、.W、.D、.BU、.HU、.WU、.DU分别表示该指令操作的数据类型是有符号字节、 有符号半字、 有符号字、 有符号双字、 无符号字节、 无符号半字、 无符号字、 无符号双字。
| 指令名后缀 | 操作对象数据类型 |
|---|---|
| .B | 有符号字节 (signed Byte, 8b) |
| .H | 有符号半字 (signed Halfword, 16b) |
| .W | 有符号字 (signed Word, 32b) |
| .D | 有符号双字 (signed Doubleword, 64b) |
| .BU | 无符号字节 (unsigned Byte, 8b) |
| .HU | 无符号半字 (unsigned Halfword, 16b) |
| .WU | 无符号字 (unsigned Word, 32b) |
| .DU | 无符号双字 (unsigned Doubleword, 64b) |
2 基础整数指令
2.1 基础整数指令概述
| 基础整数指令类型 | 指令 |
|---|---|
| 算术运算类指令 | ADD.{W/D}, SUB.{W/D} |
| ADDI.{W/D}, ADDU16I.D | |
| ALSL.{W[U]/D} | |
| LU12I.W, LU32I.D, LU52I.D | |
| SLT[U] | |
| SLT[U]I | |
| PCADDI, PCADDU12I, PCADDU18I, PCALAU12I | |
| AND, OR, NOR, XOR, ANDN, ORN | |
| ANDI, ORI, XORI | |
| NOP | |
| MUL.{W/D}, MULH.{W[U[/D[U]} | |
| MULW.D.W[U] | |
| DIV.{W[U]/D[U]}, MOD.{W[U]/D[U]} | |
| 移位运算类指令 | SLL.W, SRL.W, SRA.W, ROTR.W |
| SLLI.W, SRLI.W, SRAI.W, ROTRI.W | |
| SLL.D, SRL.D, SRA.D, ROTR.D | |
| SLLI.D, SRLI.D, SRAI.D, ROTRI.D | |
| 位操作指令 | EXT.W.{B/H} |
| CL{O/Z}.{W/D}, CT{O/Z}.{W/D} | |
| BYTEPICK.{W/D} | |
| REVB.{2H/4H/2W/D} | |
| REVH.{2W/D} | |
| BITREV.{4B/8B} | |
| BITREV.{W/D} | |
| BSTRINS.{W/D} | |
| BSTRPICK.{W/D} | |
| MASKEQZ, MASKNEZ | |
| 转移指令 | BEQ, BNE, BLT[U], BGE[U] |
| BEQZ, BNEZ | |
| B | |
| BL | |
| JIRL | |
| 访存指令 | LD.{B[U]/H[U]/W[U]/D}, ST.{B/H/W/D} |
| LDX.{B[U]/H[U]/W[U]/D}, STX.{B/H/W/D} | |
| LDPTR.{W/D}, STPTR.{W/D} | |
| PRELD | |
| PRELDX | |
| 边界检查访存指令 | LD{GT/LE}.{B/H/W/D}, ST{GT/LE}.{B/H/W/D} |
| 原子访存指令 | AM{SWAP/ADD/AND/PR/XOR/MAX/MIN}[_DB].{W/D} |
| AM{MAX/MIN}[_DB].{WU/DU} | |
| LL.{W/D}, SC.{W/D} | |
| 栅障指令 | DBAR, IBAR |
| CRC校验指令 | CRC[C].W.{B/H/W/D}.W |
| 其它杂项指令 | SYSCALL, BREAK, ASRT{LE/GT}.D |
| RDTIME{L/H}.W, RDTIME.D, CPUCFG |
3 基础浮点数指令
3.1 基础浮点数指令概述
除了 FLDX.{S/D}、 FSTX.{S/D}、 FLD{GT/LE}.{S/D}和 FST{GT/LE}.{S/D}这 12条浮点访存指令仅属于 LA64 架构, 其余所有浮点数指令同时适用于 LA32 架构和 LA64 架构。
| 基础浮点数指令类型 | 指令 |
|---|---|
| 浮点运算指令 | F{ADD/SUB/MUL/DIV}.{S/D} |
| F{MADD/MSUB/NMADD/NMSUB}.{S/D} | |
| F{MAX/MIN}.{S/D} | |
| F{MAXA/MINA}.{S/D} | |
| F{SQRT/RECIP/RSQRT}.{S/D} | |
| F{SCALEB/LOGB/COPYSIGN}.{S/D} | |
| CLASS.{S/D} | |
| 浮点比较指令 | FCMP.cond.{S/D} |
| 浮点转换指令 | FCVT.S.D, FCVT.D.S |
| FFINT.{S/D}.{W/L}, FTINT.{W/L}.{S/D} | |
| FTINT{RM/RP/RZ/RNE}.{W/L}.{S/D} | |
| FRINT.{S/D} | |
| 浮点搬运指令 | FMOV.{S/D} |
| FSEL | |
| MOVGR2FR.{W/D}, MOVGR2FRH.W | |
| MOVFR2GR.{S/D}, MOVFRH2GR.S | |
| MOVGR2FCSR, MOVFCSR2GR | |
| MOVFR2CF, MOVCF2FR | |
| MOVGR2CF, MOVCF2GR | |
| 浮点分支指令 | BCEQZ, BCNEZ |
| 浮点普通访存指令 | FLD.{S/D}, FST.{S/D} |
| FLDX.{S/D}, FSTX.{S/D} | |
| 浮点边界检查访存指令 | FLD{GT/LE}.{S/D}, FST{GT/LE}.{S/D} |
4 特权指令
4.1 特权指令概述
| 特权指令类型 | 指令 |
|---|---|
| CSR访问指令 | CSRRD, CSRWR, CSRXCHG |
| IOCSR访问指令 | IOCSR{RD/WR}.{B/H/W/D} |
| Cache维护指令 | CACOP |
| TLB维护指令 | TABSRCH, TABRD, TABWR, TABFILL, TABCLR, TABFLUSH, INVTAB |
| 软件页表遍历指令 | LDDIR, LDPTE |
| 其他杂项指令 | ETRN, DBCL, IDLE |
5 指令集功能解析
未完待续…