零基础学做网站的书手机优化是什么意思
地毯填补问题
题目描述
相传在一个古老的阿拉伯国家里,有一座宫殿。宫殿里有个四四方方的格子迷宫,国王选择驸马的方法非常特殊,也非常简单:公主就站在其中一个方格子上,只要谁能用地毯将除公主站立的地方外的所有地方盖上,美丽漂亮聪慧的公主就是他的人了。公主这一个方格不能用地毯盖住,毯子的形状有所规定,只能有四种选择(如图):

并且每一方格只能用一层地毯,迷宫的大小为 2 k × 2 k 2^k\times 2^k 2k×2k 的方形。当然,也不能让公主无限制的在那儿等,对吧?由于你使用的是计算机,所以实现时间为 1 1 1 秒。
输入格式
输入文件共 2 2 2 行。
第一行一个整数 k k k,即给定被填补迷宫的大小为 2 k × 2 k 2^k\times 2^k 2k×2k( 0 < k ≤ 10 0\lt k\leq 10 0<k≤10);
第二行两个整数 x , y x,y x,y,即给出公主所在方格的坐标( x x x 为行坐标, y y y 为列坐标), x x x 和 y y y 之间有一个空格隔开。
输出格式
将迷宫填补完整的方案:每一补(行)为 x y c x\ y\ c x y c( x , y x,y x,y 为毯子拐角的行坐标和列坐标, c c c 为使用毯子的形状,具体见上面的图 1 1 1,毯子形状分别用 1 , 2 , 3 , 4 1,2,3,4 1,2,3,4 表示, x , y , c x,y,c x,y,c 之间用一个空格隔开)。
样例 #1
样例输入 #1
3
3 3
样例输出 #1
5 5 1
2 2 4
1 1 4
1 4 3
4 1 2
4 4 1
2 7 3
1 5 4
1 8 3
3 6 3
4 8 1
7 2 2
5 1 4
6 3 2
8 1 2
8 4 1
7 7 1
6 6 1
5 8 3
8 5 2
8 8 1
提示
spj 报错代码解释:
- c c c 越界;
- x , y x,y x,y 越界;
- ( x , y ) (x,y) (x,y) 位置已被覆盖;
- ( x , y ) (x,y) (x,y) 位置从未被覆盖。
upd 2023.8.19 \text{upd 2023.8.19} upd 2023.8.19:增加样例解释。
样例解释
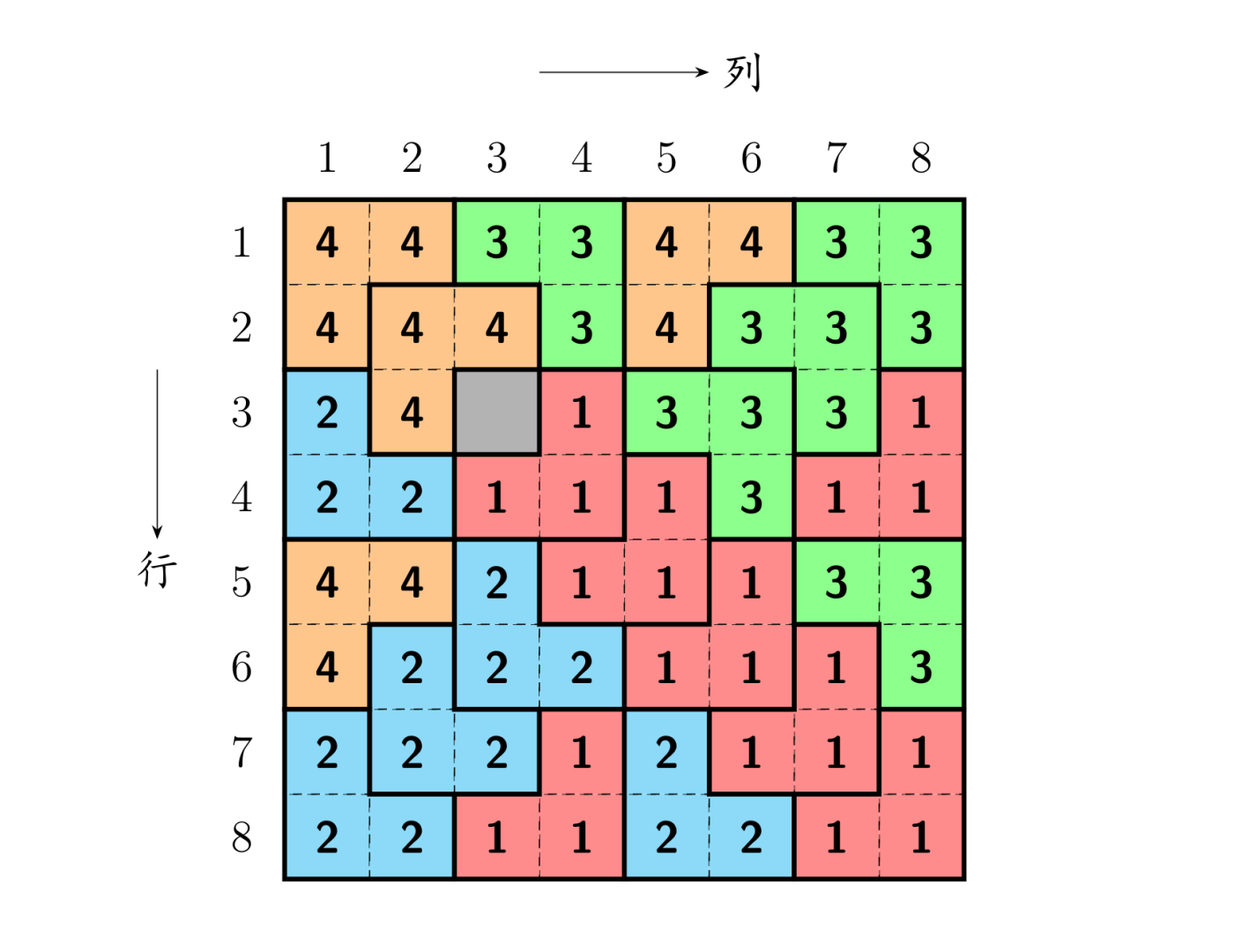
大致思路
当k=1时,我们可以非常容易得到毯子填补的方案。当k=2甚至更大时,我们可以将其划分为四大块,但是公主位只有一个,而对于其他没有公主位的四方格,似乎和原问题形式不一样。但是我们可以对其加以处理,使其四个子问题都具有相同形式——即,我们可以手动为其他三个没有公主位的四方格增加新的“公主位”。例如,当公主位在左上角时,我们可以将剩余三个四方格的交界处用毯子1来补上,这样每个四方格都会被分配到一个公主位,称为特殊的方阵,问题便迎刃而解(如图所示)。因此我们就可以采用分治的方法去不断将正方形划分为4个子正方形,再分别填充,直到小正方形边长为1时,就是公主位了,不用做任何处理。
8x8的方格里,公主在右上角的格子里,然后在左上角的4x4方格中,选右下角,在左下角的方格中,选右上角,在右下角的方格中,选左上角,组成一个L,现在一个8x8的方格被分为四个4x4的方格,每个4x4的方格中,都有一块被挖掉的部分,左上角的4*4方格中被挖掉的部分是它右下角组成L的那一块,右上角的4x4方格中,挖去的是公主的位置,左下角和右下角的方格,挖去的都是L那部分
然后对每个4x4方格,重复以上操作,直到方格划分为2*2的,四个格子中有一个被挖去,另外三个自然组成一个L
AC CODE
#include<bits/stdc++.h>
using namespace std;// 正方形左上角坐标xx和yy,公主坐标x和y,正方形边长k
void work(int xx,int yy,int x,int y,int k){if(k == 1) return;k/=2;// 左上角if(x < xx+k && y < yy+k){printf("%d %d %d\n",xx+k,yy+k,1);// 递归覆盖左上角work(xx,yy,x,y,k);// 覆盖右下角work(xx+k,yy+k,xx+k,yy+k,k);// 覆盖左下角work(xx+k,yy,xx+k,yy+k-1,k);// 覆盖右上角work(xx,yy+k,xx+k-1,yy+k,k);}// 右上角else if(x < xx+k && y >= yy+k){printf("%d %d %d\n",xx+k,yy+k-1,2);// 递归覆盖左上角work(xx,yy,xx+k-1,yy+k-1,k);// 覆盖右下角work(xx+k,yy+k,xx+k,yy+k,k);// 覆盖左下角work(xx+k,yy,xx+k,yy+k-1,k);// 覆盖右上角work(xx,yy+k,x,y,k);}// 左下角else if(x >= xx+k && y < yy+k){printf("%d %d %d\n",xx+k-1,yy+k,3);// 递归覆盖左上角work(xx,yy,xx+k-1,yy+k-1,k);// 覆盖右下角work(xx+k,yy+k,xx+k,yy+k,k);// 覆盖左下角work(xx+k,yy,x,y,k);// 覆盖右上角work(xx,yy+k,xx+k-1,yy+k,k);}// 右下角else{printf("%d %d %d\n",xx+k-1,yy+k-1,4);// 递归覆盖左上角work(xx,yy,xx+k-1,yy+k-1,k);// 覆盖右下角work(xx+k,yy+k,x,y,k);// 覆盖左下角work(xx+k,yy,xx+k,yy+k-1,k);// 覆盖右上角work(xx,yy+k,xx+k-1,yy+k,k);}
}int main()
{int x,y,k;cin >> k >> x >> y;work(1,1,x,y,(1 << k));return 0;
}