微信小游戏网络优化器免费
1、在 express 项目根目录下新增 Dockerfile 文件,内容如下:
创建服务容器的方法,可以根据自己的情况选择:
1、以下示例为宿主机没有安装node环境的写法;
2、先在本地构建包含node和express的基础镜像,再将构建好的镜像传到服务器直接基于构建好的镜像创建容器;
3、在宿主机安装node环境,将express工程源码上传到服务器,通过sh脚本在服务器构建镜像,再基于构建好的镜像创建容器。
Dockerfile
# 基础镜像为 Alpine Linux 版本 3.13, 使用 Alpine Linux 作为容器的基础操作系统
FROM alpine:3.13# 容器默认时区为UTC,如需使用上海时间请启用以下时区设置命令
# RUN apk add tzdata && cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && echo Asia/Shanghai > /etc/timezone# 安装依赖包,如需其他依赖包,请到alpine依赖包管理(https://pkgs.alpinelinux.org/packages?name=php8*imagick*&branch=v3.13)查找。
RUN apk add --update --no-cache nodejs npm# 指定工作目录
WORKDIR /app# 拷贝包管理文件
COPY package*.json /app# npm 源,选用国内镜像源以提高下载速度
RUN npm config set registry https://registry.npm.taobao.org/# npm 安装依赖
RUN npm install# 将当前目录(dockerfile所在目录)下所有文件都拷贝到工作目录下(.gitignore中的文件除外)
COPY . /app# 执行启动命令.
# 写多行独立的CMD命令是错误写法!只有最后一行CMD命令会被执行,之前的都会被忽略,导致业务报错。
# 请参考[Docker官方文档之CMD命令](https://docs.docker.com/engine/reference/builder/#cmd)
# 执行 package.json 的 scripts 中约定的自定义命令时,格式必须为 CMD ["npm", "run", "命令"]
CMD ["npm", "run", "pro"]2、在 express 项目根目录下新增 deploy.sh 部署脚本,内容如下:
# 停止正在运行的容器
docker stop container_name# 删除正在运行的容器
docker rm -f container_name# 删除已存在的镜像
docker rmi image_name:latest # 构建镜像
docker build -t image_name:latest . # 基于构建的镜像创建容器,并将服务的日志目录挂载到宿主机,没有日志可以不挂,视自己情况挂载
docker run -d -p 3000:3000 -v /path/logs:/app/logs --name container_name image_name3、在 express 项目根目录下新增 .dockerignore 文件,用于指定在构建 Docker 镜像时需要被忽略的文件和目录,内容如下:
Dockerfile
.dockerignore
node_modules
npm-debug.log
4、将 express 项目文件上传至服务器任意目录,进入项目根目录,执行如下命令,成功后会显示容器的标识符(长字符串)
sh ./deploy.sh
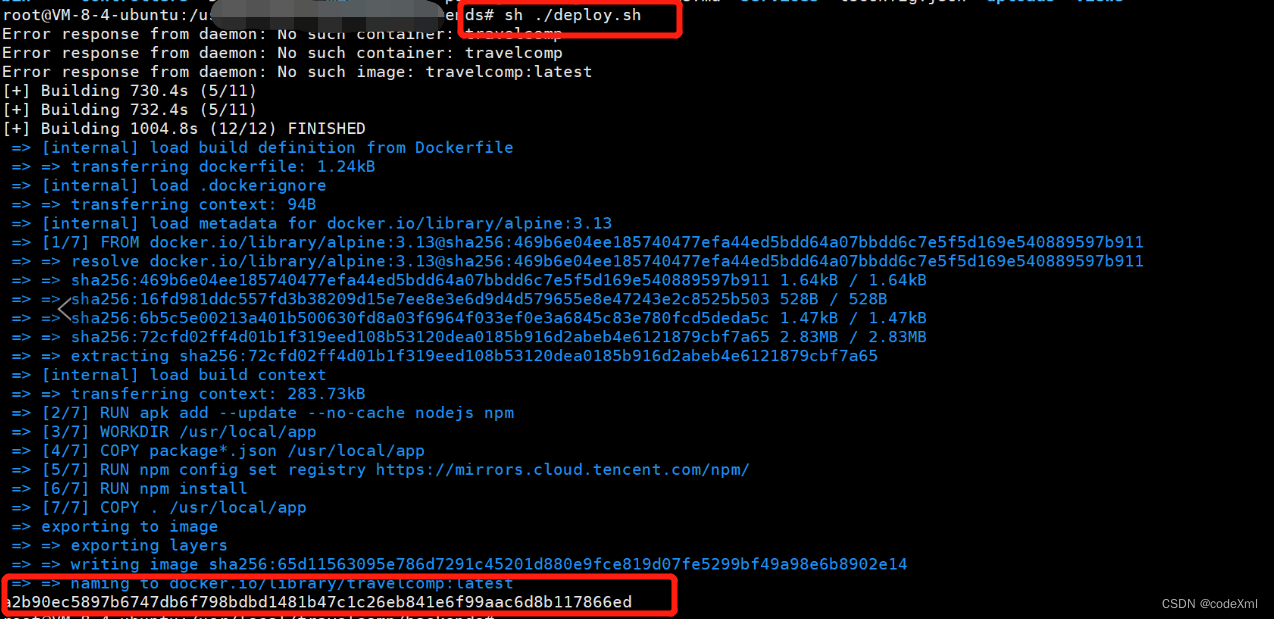
docker images // 查看生成的镜像

docker ps -a // 列出所有本地运行的容器,包括正在运行的容器和已停止的容器
如果 STATUS 为 UP 则表示成功,如果失败可以执行 docker logs container_name 查看原因

5、配置 nginx 代理,主要内容如下:
没有
ssl证书则可以不配ssl_开头的参数,
server {listen 80;# 使用 https 则需要监听 443 端口listen 443 ssl;server_name demo.com;# 导入 ssl 证书密钥ssl_certificate /etc/nginx/ssl/fullchain.pem;ssl_certificate_key /etc/nginx/ssl/privkey.key;# SSL 会话的超时时间ssl_session_timeout 5m;# 启用的 SSL 协议版本为 TLSv1、TLSv1.1 和 TLSv1.2ssl_protocols TLSv1 TLSv1.1 TLSv1.2;# 启用的密码套件为 ECDHE-RSA-AES128-GCM-SHA256 和高强度的非空、非弱密码的套件,同时禁用了含有 MD5、RC4 和 DHE 的套件ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:HIGH:!aNULL:!MD5:!RC4:!DHE;# 优先选择服务器端提供的密码套件ssl_prefer_server_ciphers on;# 设置请求体的最大大小为 10 MB。如果接收到的请求体超过这个大小,Nginx 将返回 413 Request Entity Too Large 错误client_max_body_size 10m;# access_log /var/log/nginx/host.access.log main;location /api/ {proxy_set_header HOST $host;proxy_set_header X-Forwarded-Proto $scheme;proxy_set_header X-Real-IP $remote_addr;proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;# 如果是腾讯云服务器,xxx只能是内网 ip,被卡(keng)了很久proxy_pass http://xxx:3000/; }location / {root /usr/share/nginx/html;index index.html index.htm;}# ...
}6、重启 nginx 服务
如果是容器部署的
nginx,则直接重启容器就能正常访问了
# 检查 nginx 配置是否正确
nginx -t# 重启 nginx 容器
docker restart nginx_container // nginx_container 可以是容器名也可以是容器id