阿克苏建设局网站网店seo
PostGIS学习教程九:空间连接
空间连接(spatial joins)是空间数据库的主要组成部分,它们允许你使用空间关系作为连接键(join key)来连接来自不同数据表的信息。我们认为“标准GIS分析”的大部分内容可以表示为空间连接。
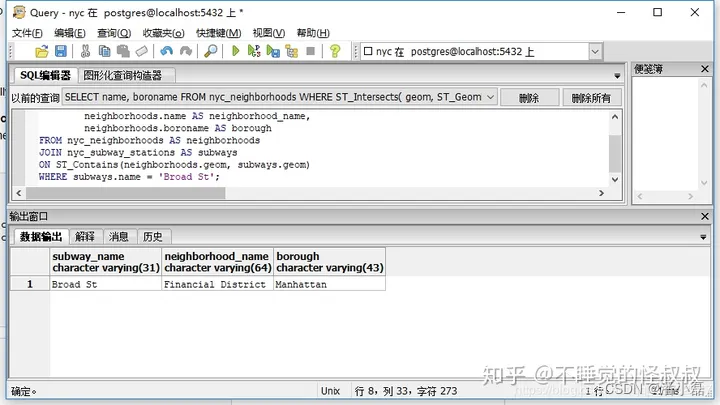
在上一节中,我们通过两个步骤探索了空间关系:首先,我们提取了’Broad St(宽街)'的地铁站点;然后,我们用这个地铁站点来问更多的问题,如"'Broad St’站位于哪个社区?"
使用空间连接,我们可以只通过一个步骤来回答这个问题,检索有关地铁站及其所在社区的信息:
SELECTsubways.name AS subway_name,neighborhoods.name AS neighborhood_name,neighborhoods.boroname AS borough
FROM nyc_neighborhoods AS neighborhoods
JOIN nyc_subway_stations AS subways
ON ST_Contains(neighborhoods.geom, subways.geom)
WHERE subways.name = 'Broad St';
我们本可以把每个地铁站都连接到它所在的社区,但在这种情况下,我们只想知道其中一个地铁站的信息。
任何在两个表之间提供true/false关系的函数都可以用来驱动空间连接,但最常用的函数是:ST_Intersects、ST_Contains和ST_DWithin。
文章目录
- PostGIS学习教程九:空间连接
- 一、连接和汇总
- 二、高级连接
- 三、空间连接练习
一、连接和汇总
JOIN和GROUP BY的组合支持通常在GIS系统中的某些分析。
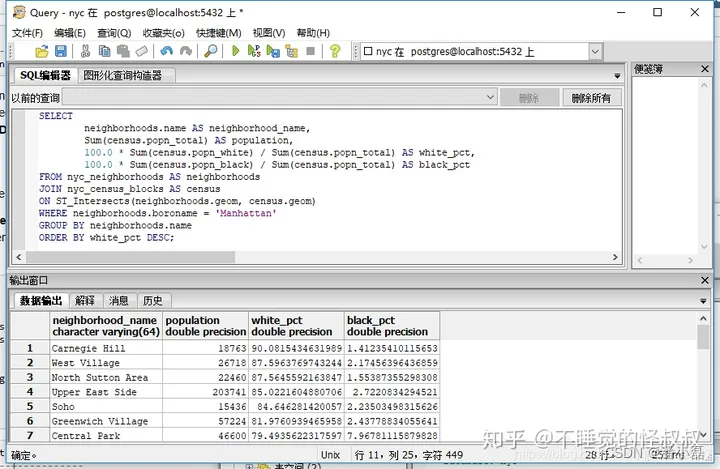
例如:“曼哈顿行政区的各个社区的人口和种族构成是什么?”,这个问题将人口普查中的人口信息与社区的几何信息结合在一起,社区信息只限制在曼哈顿的一个行政区中。
SELECTneighborhoods.name AS neighborhood_name,Sum(census.popn_total) AS population,100.0 * Sum(census.popn_white) / Sum(census.popn_total) AS white_pct,100.0 * Sum(census.popn_black) / Sum(census.popn_total) AS black_pct
FROM nyc_neighborhoods AS neighborhoods
JOIN nyc_census_blocks AS census
ON ST_Intersects(neighborhoods.geom, census.geom)
WHERE neighborhoods.boroname = 'Manhattan'
GROUP BY neighborhoods.name
ORDER BY white_pct DESC;
这里发生了什么?从理论上讲(数据库在内部对实际运行机制进行了优化)发生的情况如下:
1.JOIN子句创建了一个虚拟表,其中包含来自neighborhoods表和census表的列。
2.WHERE子句将我们的虚拟表筛选为仅保留有关曼哈顿行政区的记录。
3.结果记录按neighborhood name分组,并通过聚合函数Sum()计算人口数
4.在对最后的数字进行一些算术和格式化之后,我们的查询就会输出百分比。
注意:JOIN子句组合了两个FROM子句中的数据表,默认情况下,数据库使用的是INNER JOIN连接类型,但还有其他四种连接类型,有关详细信息,请参阅PostgreSQL文档中的join_type的定义。
我们还可以使用距离测试作为连接键,以创建汇总的“半径内所有项”查询。让我们使用距离查询来探索纽约的种族地理。
首先,让我们了解一下这个城市的基本种族构成。
SELECT100.0 * Sum(popn_white) / Sum(popn_total) AS white_pct,100.0 * Sum(popn_black) / Sum(popn_total) AS black_pct,Sum(popn_total) AS popn_total
FROM nyc_census_blocks;
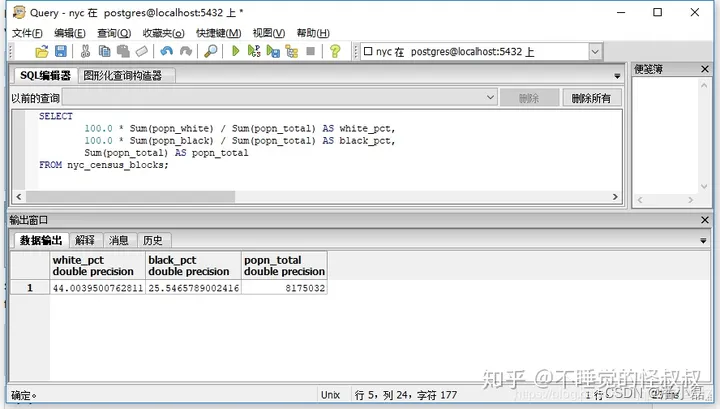
因此,在纽约的800万人口中,大约44%的人被记录为”白人“,26%的人被记录为”黑人“。
艾灵顿公爵曾经唱过这样一首歌:"你/必须乘A-train/去哈莱姆区(Harlem)的糖山(Sugar Hill)。"正如我们早些时候看到的,哈莱姆地区拥有曼哈顿(Manhattan)最多的非裔美国人(80.5%)。杜克(Duke)的A-train也是这样的吗?
首先,请注意,nyc_subway_stations表routes字段的内容是我们感兴趣的用于查找A-train的内容。里面的值有点复杂。
SELECT DISTINCT routes FROM nyc_subway_stations;
注意:DISTINCT关键字从结果中消除重复的行。如果没有DISTINCT关键字,上面的查询将标识491个结果,而不是73个。
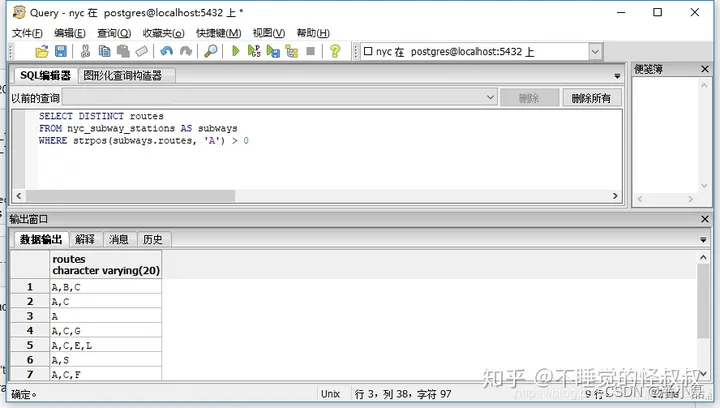
所以,要找到A-train,我们需要在routes列中有’A’的所有行记录。我们可以通过多种方法来实现这一点,但今天我们将使用strpos(routes, ‘A’),它只有当’A’在routes列中才会返回非零数。
SELECT DISTINCT routes
FROM nyc_subway_stations AS subways
WHERE strpos(subways.routes,'A') > 0;
现在让我们计算一下距A-train线200米以内的种族构成:
SELECT100.0 * Sum(popn_white) / Sum(popn_total) AS white_pct,100.0 * Sum(popn_black) / Sum(popn_total) AS black_pct,Sum(popn_total) AS popn_total
FROM nyc_census_blocks AS census
JOIN nyc_subway_stations AS subways
ON ST_DWithin(census.geom, subways.geom, 200)
WHERE strpos(subways.routes,'A') > 0;

因此,可以得出结论:A-train服务的区域的种族构成与城市其他区域的种族构成并没有太大的不同。
二、高级连接
在上面的最后部分,我们看到A-train服务的区域的种族构成与城市其他区域的种族构成并没有太大的不同。有没有哪些地铁的服务区域的种族构成与纽约整个城市的种族构成差异较大?
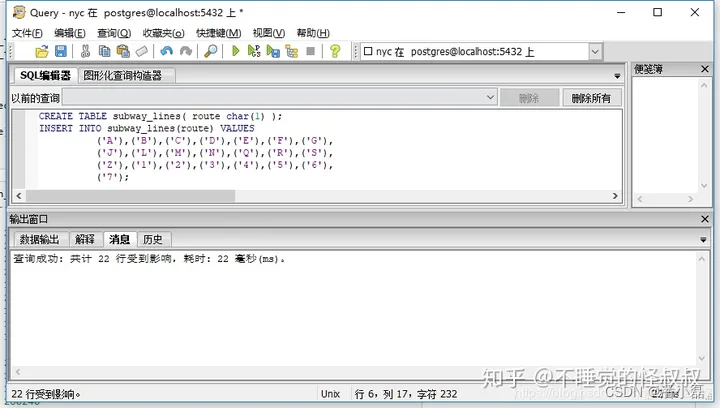
为了回答这个问题,我们将在查询中添加另一个连接,以便可以同时计算多条地铁线路的构成。要做到这一点,我们需要创建一个新的表,遍历我们想要汇总的所有行。
CREATE TABLE subway_lines ( route char(1) );
INSERT INTO subway_lines (route) VALUES('A'),('B'),('C'),('D'),('E'),('F'),('G'),('J'),('L'),('M'),('N'),('Q'),('R'),('S'),('Z'),('1'),('2'),('3'),('4'),('5'),('6'),('7');
现在,我们可以将subway lines连接到原始查询中。
SELECTlines.route,100.0 * Sum(popn_white) / Sum(popn_total) AS white_pct,100.0 * Sum(popn_black) / Sum(popn_total) AS black_pct,Sum(popn_total) AS popn_total
FROM nyc_census_blocks AS census
JOIN nyc_subway_stations AS subways
ON ST_DWithin(census.geom, subways.geom, 200)
JOIN subway_lines AS lines
ON strpos(subways.routes, lines.route) > 0
GROUP BY lines.route
ORDER BY black_pct DESC;
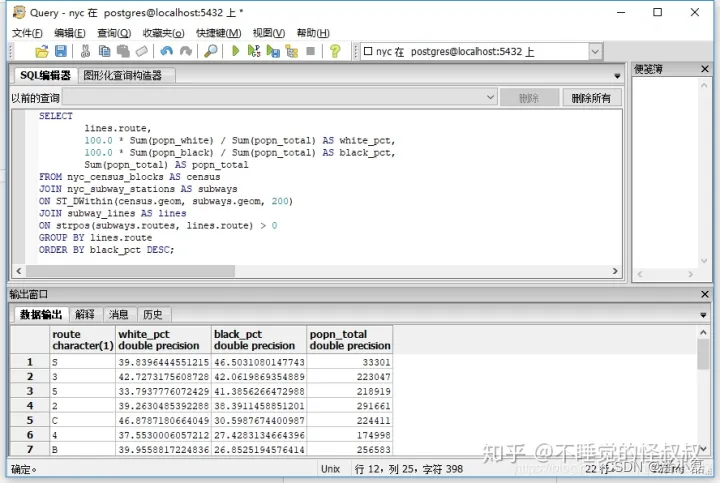
如前所述,连接创建了一个虚拟表,其中包含在JOIN ON约束范围内可用的所有的连接的行记录,然后将这些行记录分组。ST_DWithin可确保计算中仅包括靠近地铁站的人口普查区块。
三、空间连接练习
下面是我们之前所看到的一些函数的汇总,它们应该对练习有用!

同时请记住我们的数据库中现有的数据表:
nyc_census_blocks
name, popn_total, boroname, geom
nyc_streets
name, type, geom
nyc_subway_stations
name, routes, geom
nyc_neighborhoods
name, boroname, geom
练习:
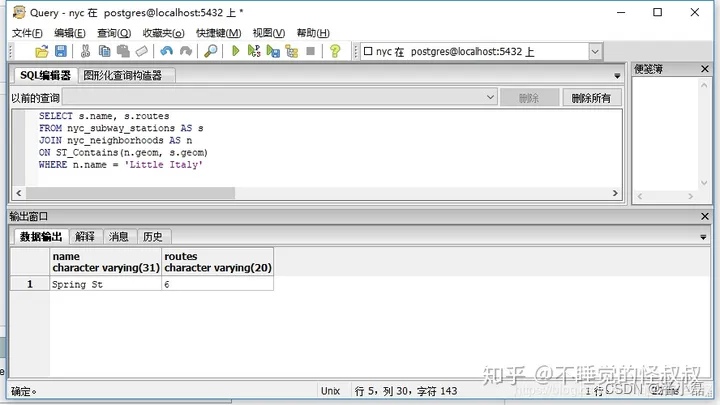
①"小意大利(Little Italy)社区"有什么地铁站?它在哪些地铁线路上?
SELECT s.name, s.routes
FROM nyc_subway_stations AS s
JOIN nyc_neighborhoods AS n
ON ST_Contains(n.geom, s.geom)
WHERE n.name = 'Little Italy';
②"6-train服务哪些社区?"(提示:nyc_subway_stations表中的routes列具有类似"B,D,6,V"和"C,6"的值)
SELECT DISTINCT n.name, n.boroname
FROM nyc_subway_stations AS s
JOIN nyc_neighborhoods AS n
ON ST_Contains(n.geom, s.geom)
WHERE strpos(s.routes,'6') > 0;
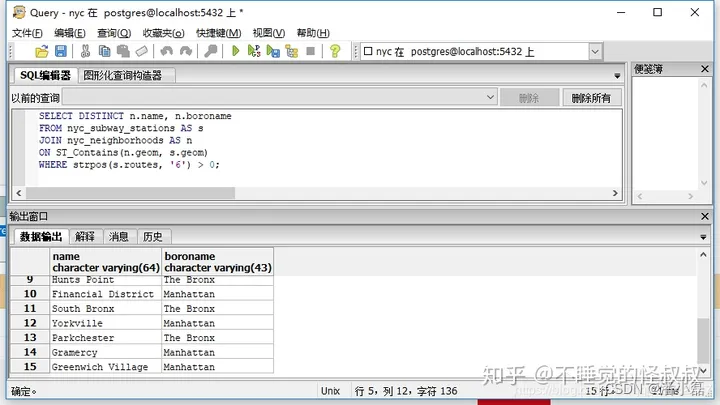
注意:我们使用DISTINCT关键字从结果集中删除在一个社区中的多个地铁站的重复记录。
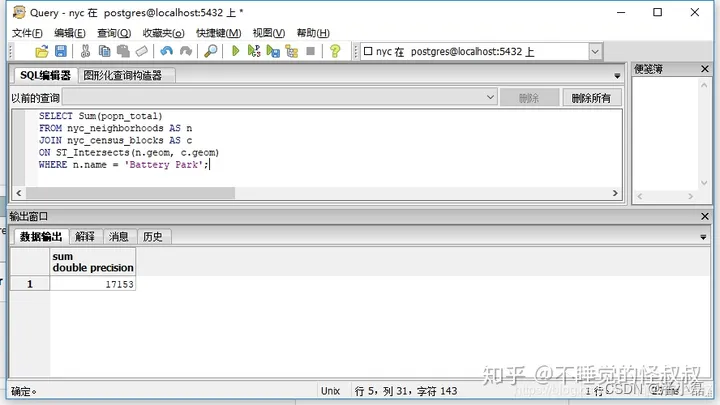
③"9/11事件后,'Battery Park'社区附近将禁止入内几天,那么要疏散多少人呢?"
SELECT Sum(popn_total)
FROM nyc_neighborhoods AS n
JOIN nyc_census_blocks AS c
ON ST_Intersects(n.geom, c.geom)
WHERE n.name = 'Battery Park';
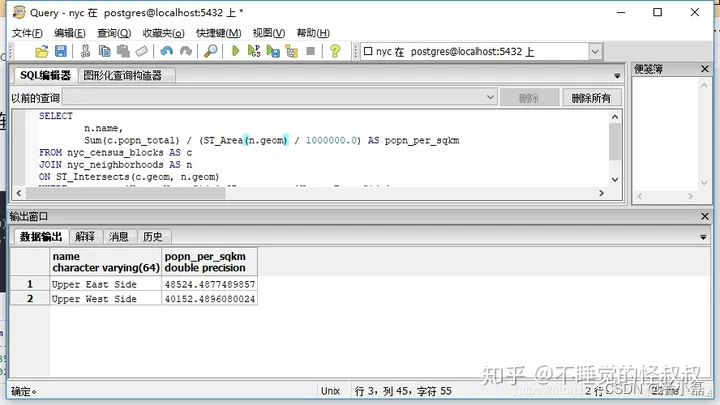
④"'Upper West Side'和'Upper East Side'的人口密度是多少"
SELECTn.name,Sum(c.popn_total) / (ST_Area(n.geom) / 1000000.0) AS popn_per_sqkm
FROM nyc_census_blocks AS c
JOIN nyc_neighborhoods AS n
ON ST_Intersects(c.geom, n.geom)
WHERE n.name = 'Upper West Side'
OR n.name = 'Upper East Side'
GROUP BY n.name, n.geom;