兰州做网站 东方商易多合一seo插件破解版
前言
在前面一篇文章 coredump 的生成和使用 中, 我们看到 "测试用例2 - 非法地址访问"
产生了一个 segment fault
我们这里 就来调试一下 这个 segment fault 是怎么回事
测试用例
#include "stdio.h"int main(int argc, char** argv) {int x = 2;
int y = 3;
int z = x + y;char* p = (char*) z;
char pValue = *p;//char divZero = z / 0;//setenv("name", "jerry");
//char* envName = getenv("name");
//printf(" envName = %s, %s \n", envName, z);}
执行报错如下
(initramfs) ./Test07CoreDump
[ 838.608478] Test07CoreDump[288]: segfault at 5 ip 0000000000400507 sp 00007fffab5dd360 error 4 in Test07CoreDump[400000+1000]
Segmentation fault
调试这个 segment fault
根据 address 查找最近的 vma, 根据 5 来找
找到的事程序文件本身加载到内存中的一块 vma [0x400000 - 401000]
但是显然 address 是不属于这块 vma 的, 这块 vma 也不允许向下扩张, 走的 bad_area 的处理
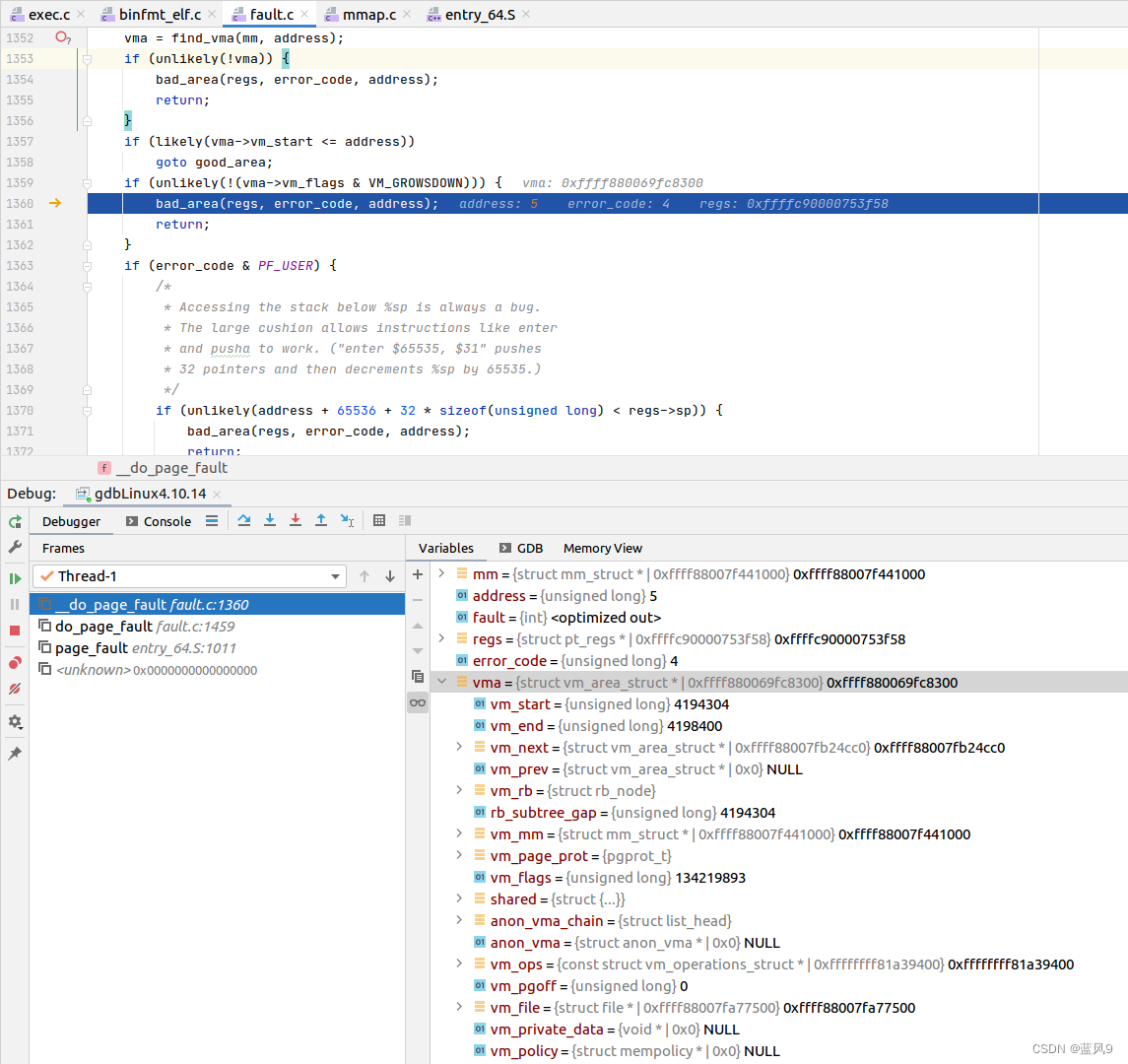
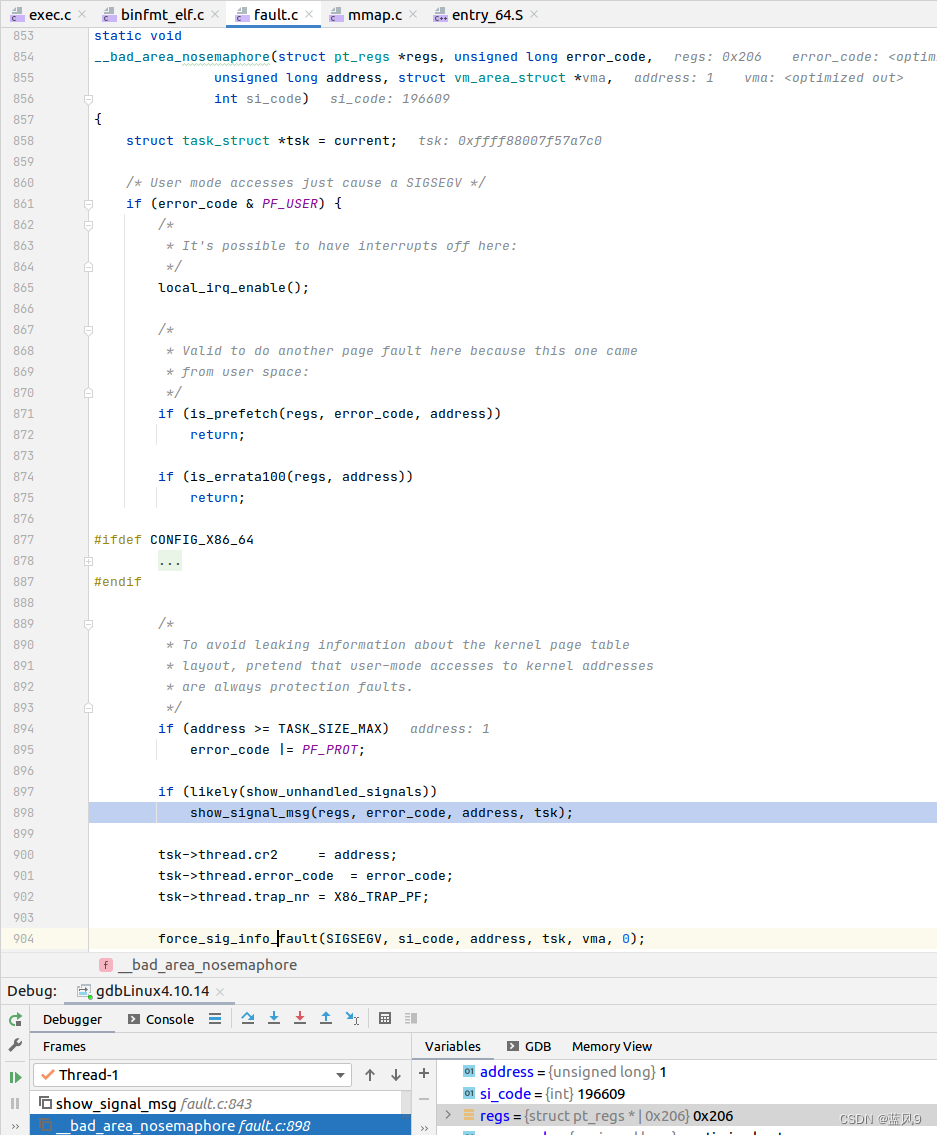
如果是用户 模式产生的 bad_area, 创建一个 SIGSEGV 信号量发送给目标进程
我们这里断点的是 内核日志输出的地方
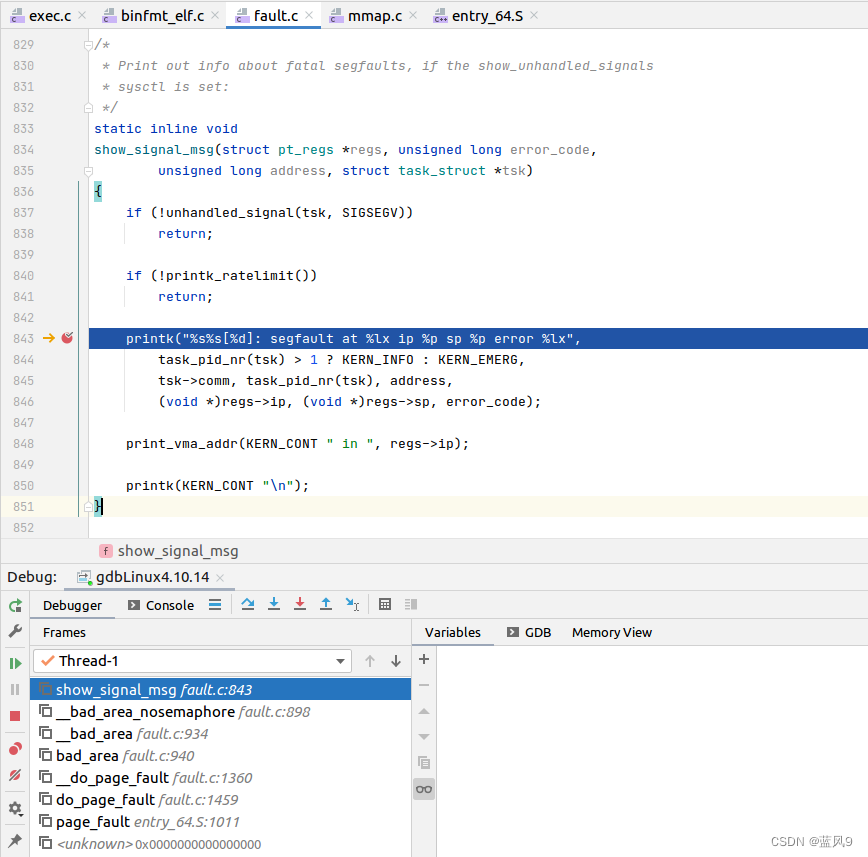
输出异常日志的地方
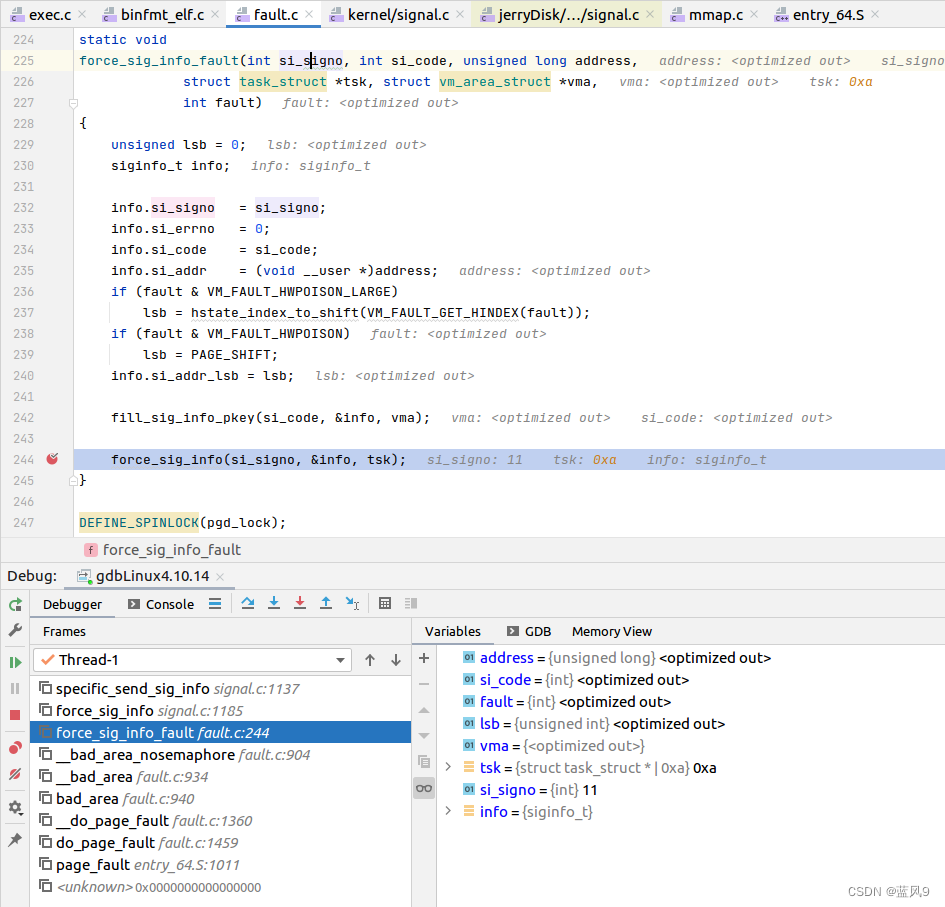
发送 SIGSEGV 信号的地方
完