wordpress editor英文seo外链

前言
在微服务大量应用的互联网时代,经常能看到docker的身影。作为docker的爱好者(在服务器安装MySQL,Redis。。。我用的都是docker),我也会持续深入学习和认识docker。
本篇博客再次介绍docker的基本概念,拆解docker的结构,介绍常用的相关命令,给出了制作镜像的两种方式,并给出操作案例。
其他相关的docker的博客文章如下
- Docker——认识Docker & 常用命令 & Linux中安装docker & 常见问题及其解决
- SpringBoot项目部署(Docker)——通过Dockerfile将打包好的jar包创建成镜像 & 在IDEA中配置docker,一键启动容器 & 用swagger进行测试
目录
- 前言
- 引出
- 一、认识Docker
- 1、docker的概念
- 2、Linux中安装Docker
- 3、docker相关概念
- 二、Docker相关命令
- 1、进程命令
- 2、镜像容器命令
- 三、Docker镜像结构
- 1、Linux文件系统组成
- 2、Docker镜像原理
- 四、Docker镜像制作
- 1、普通方式
- 案例一:制作centos-java镜像
- 1、首先创建一个centos容器
- 2、安装JDK
- 3、配置/etc/bashrc
- 4、制作镜像
- 2、dockerfile方式
- 案例一:自定义centos7镜像
- 案例二:定义dockerfile文件构建镜像,发布springboot项目
- 总结
引出
1.介绍docker的基本概念,拆解docker的结构;
2.常用的相关命令,进程命令和容器镜像命令;
3.制作镜像的两种方式,并给出操作案例。
一、认识Docker
1、docker的概念
1、Docker 是一个开源的应用容器引擎
2、诞生于 2013 年初,基于 Go 语言实现, dotCloud 公司出品(后改名为Docker Inc)
3、Docker 是一个可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器引擎(好比汽车发动机),然后发布到任何流行的 Linux 机器上。
4、容器是完全使用沙箱机制,相互隔离
5、容器性能开销极低。
6、Docker 从 17.03 版本之后分为 CE(Community Edition: 社区版) 和 EE(Enterprise Edition: 企业版)

docker扮演的是图中鲸鱼的角色,而鲸鱼之上的集装箱就是一个个容器,容器中是我们开发的应用程序(不仅限于web应用),每个容器都有自己独立的环境(环境设置、网络、文件系统…),互不干扰。而每个箱子,又可以打包成一个新的镜像,放到其它服务器的docker环境中直接运行,不再需要重复安装程序运行环境
2、Linux中安装Docker
Docker可以运行在MAC、Windows、CentOS、UBUNTU等操作系统上
官网:https://www.docker.com
可以参考以下博客文章:
Docker——认识Docker & 常用命令 & Linux中安装docker & 常见问题及其解决
#yum 包更新到最新
yum update -y
#安装需要的软件包
yum install -y yum-utils device-mapper-persistent-data lvm2
#设置yum源
yum-config-manager --add-repo https://download.docker.com/linux/centos/dockerce.
repo
# 安装docker
yum install -y docker-ce
#查看docker版本,验证是否验证成功
docker -v
3、docker相关概念
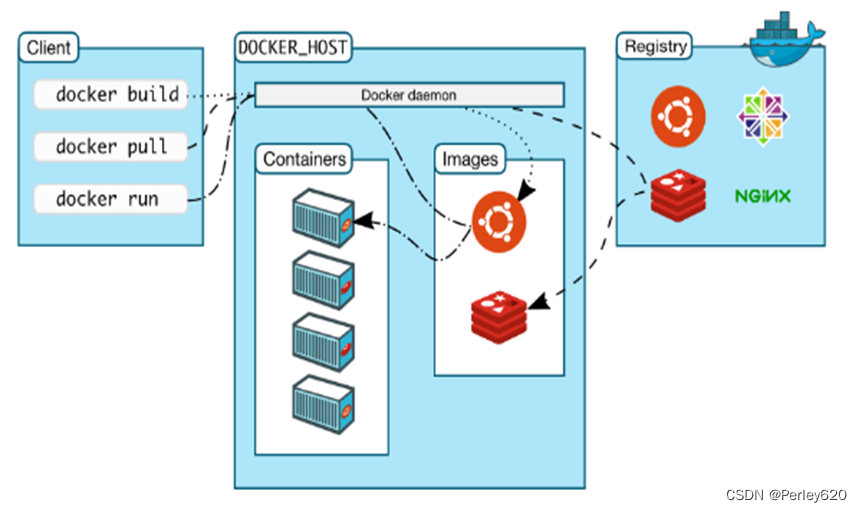
- 镜像(Image):Docker 镜像(Image),就相当于是一个 root 文件系统。比如官方镜像ubuntu:16.04 就包含了完整的一套 Ubuntu16.04 最小系统的 root 文件系统。
- 容器(Container):镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的类和对象一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。
- 仓库(Repository):仓库可看成一个代码控制中心,用来保存镜像。
二、Docker相关命令
1、进程命令
systemctl start docker #启动docker服务
systemctl stop docker #停止docker服务
systemctl restart docker #重启docker服务
systemctl status docker #查看docker服务状态
systemctl enable docker #开机启动docker服务
2、镜像容器命令
(1)docker pull
拉取镜像:从Docker仓库下载镜像到本地,镜像名称格式为 名称:版本号,如果版本号不指定则是最新的版本,如果不知道镜像版本,可以去docker hub 搜索对应镜像查看。
#docker pull 镜像名称:版本号
docker pull redis:5.0
docker pull centos:7
docker pull mysql:5.6 | docker pull mysql:8.0.25
docker pull tomcat:8
docker pull nginx
(2)docker run
docker run
- -i:以交互模式运行容器
- -t:为容器重新分配一个伪输入终端
- —name :容器名称
- —privileged: 设置容器公开权限(默认为true)
- -p :映射端口 linux端口: 容器内置端口(mysql默认端口为3306)
- -v : linux挂载文件夹/文件和容器内路径的映射
- -e: 容器的环境变量(设置mysql默认用户名&密码)
- -d: 后台运行容器,并返回容器ID
修改时区,,日志正常:-v /etc/localtime:/etc/localtime \
docker run -it \
--name redis_6389 \
--privileged \
-p 6389:6379 \
--network pet_docker_net \
--ip 172.18.12.80 \
-v /etc/localtime:/etc/localtime \
-v /usr/local/software/6389/conf/redis.conf:/usr/local/etc/redis/redis.conf \
-v /usr/local/software/6389/data/:/data \
-v /usr/local/software/6389/log/redis.log:/var/log/redis.log \
-d redis \
/usr/local/etc/redis/redis.conf(3)日志查看
# docker logs --tail 行数 -f 容器名 #查看某个容器末尾300行的日志内容
docker logs --tail 300 -f app-jar
(4)文件拷贝
#将主机/root/123.war文件拷贝到容器96f7f14e99ab的/root目录下
docker cp /root/123.war 96f7f14e99ab:/root/
#将容器96f7f14e99ab的/www目录拷贝到主机的/tmp目录中
docker cp 96f7f14e99ab:/root /tmp/
三、Docker镜像结构
1、Linux文件系统组成
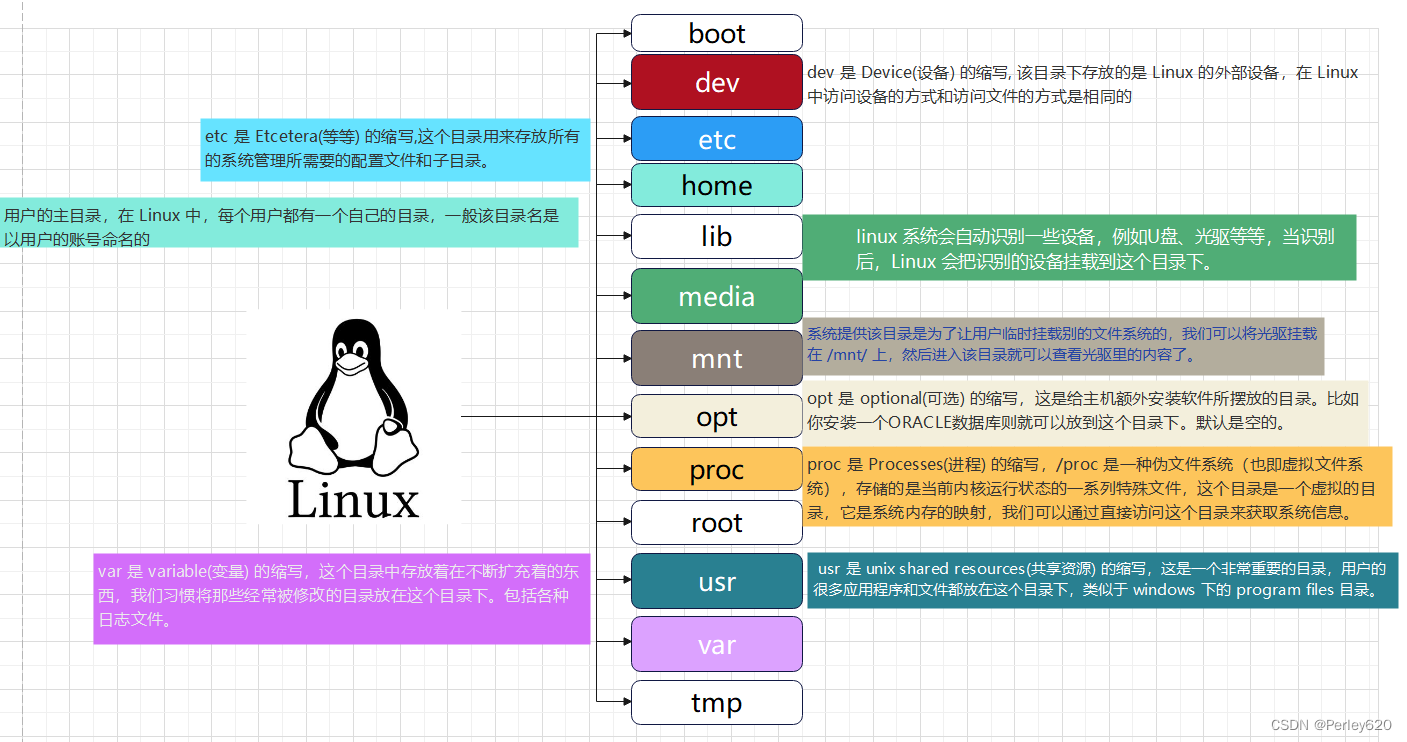
Linux文件系统组成由bootfs和rootfs两部分
- bootfs:包含bootloader(引导加载程序)和 kernel(内核)
- rootfs: root文件系统,包含的就是典型 Linux 系统中的/dev,/proc,/bin,/etc等标准目录和文件不同的linux发行版,bootfs基本一样,而rootfs不同,如ubuntu,centos等
Linux——认识Linux的目录结构 & 常用命令 & vim命令 & 权限及其控制 & 防火墙命令 & 自定义命令
思考:
Docker 镜像本质是什么?
- Docker 中一个centos镜像为什么只有200MB,而一个centos操作系统的iso文件要几个个G?
- Docker 中一个tomcat镜像为什么有500MB,而一个tomcat安装包只有70多MB?
2、Docker镜像原理
Docker镜像是由一层一层的文件系统叠加而成,最底端是 bootfs,并使用宿主机的bootfs ,第二层是 root文件系统rootfs,称为base image,然后再往上可以叠加其他的镜像文件,这种层级的文件系统被称之为UnionFS,统一文件系统(Union File System)技术能够将不同的层整合成一个文件系统,为这些层提供了一个统一的视角,这样就隐藏了多层的存在,在用户的角度看来,只存在一个文件系统
一个镜像可以放在另一个镜像的上面。位于下面的镜像称为父镜像,最底部的镜像成为基础镜像,当从一个镜像启动容器时,Docker会在最顶层加载一个读写文件系统作为容器
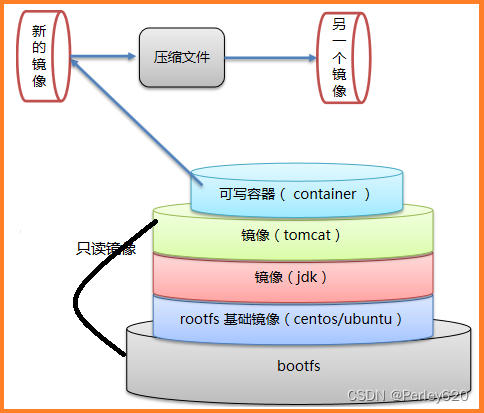
- Docker 镜像本质是一个分层文件系统
- 我们下载tomcat镜像大小是600+MB,是因为里面还包含了jdk和centos这两个镜像层,所以很大,另外需要注意一点的是,这个tomcat镜像里面包含了jdk镜像和centos基础镜像,为什么基础镜像是centos而不是ubuntu呢?这是由做这个tomcat镜像的发行商决定的。
- 我们下载centos镜像很小,是因为而centos镜像层复用了宿主机的bootfs,下载的只有rootfs,所以centos是很小的
说明:docker内核和宿主机共内核,也就是bootfs,至于rootfs发行版本,可以使和宿主机一样是centos、也可以是ubuntu或者其他的,如:docker pull centos,然后做一个容器,那么docker的发行版本是centos,进入docker容器,通过输入命令: cat /etc/redhat-release 可以查看; docker pull ubuntu,然后做一个容器,则发行版本是ubuntu
四、Docker镜像制作
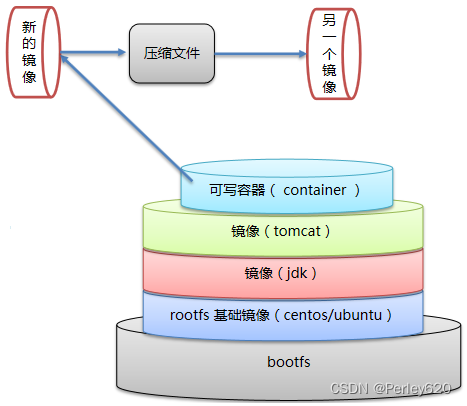
1、普通方式
将新的镜像转成压缩文件,给测试人员;测试人员把我们的压缩文件还原成一个新的镜像
docker commit 容器id 镜像名称:版本号 #把容器做成镜像
docker save -o 压缩文件名称 镜像名称:版本号 #把镜像做成压缩包,放到宿主机的某个位置
docker load –i 压缩文件名称 #别人(测试人员)加载镜像(压缩包)
注意事项:容器转为镜像,如果容器有挂载的内容,做成新镜像的时候,挂载的内容是不会载入到镜像里面的
案例一:制作centos-java镜像
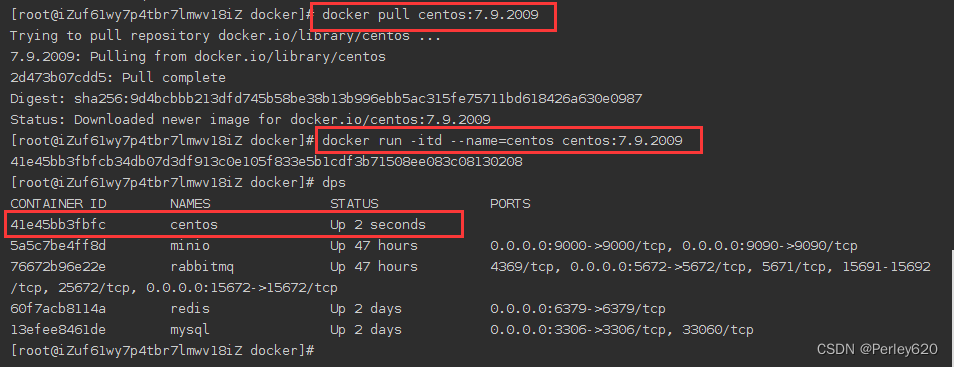
1、首先创建一个centos容器
docker pull centos:7.9.2009
docker run -it --name=centos centos:7.9.2009 /bin/bash
2、安装JDK
下载jdk-8u151-linux-x64.tar.gz到容器的home目录里面
wget http://xxx/jdk-8u151-linux-x64.tar.gz
tar -xzvf jdk-8u151-linux-x64.tar.gz
vi /etc/profile
在最下面加上:
export JAVA_HOME=/home/jdk1.8.0_151
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools
.jar
export PATH=$PATH:$JAVA_HOME/bin
使配置生效:
source /etc/profile
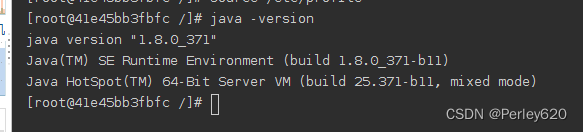
检查jdk:
java -version
3、配置/etc/bashrc
重启后环境变量仍生效在/etc/bashrc最下面加上
export JAVA_HOME=/home/jdk1.8.0_371
export CLASSPATH=.:$JAVA_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin
由于每次启动终端的时候,都会执行 /etc/bashrc ,所以可以把source /etc/profile 命令写入到 /etc/bashrc 文件中,实现环境变量立刻全面生效的效果。
退出容器
exit
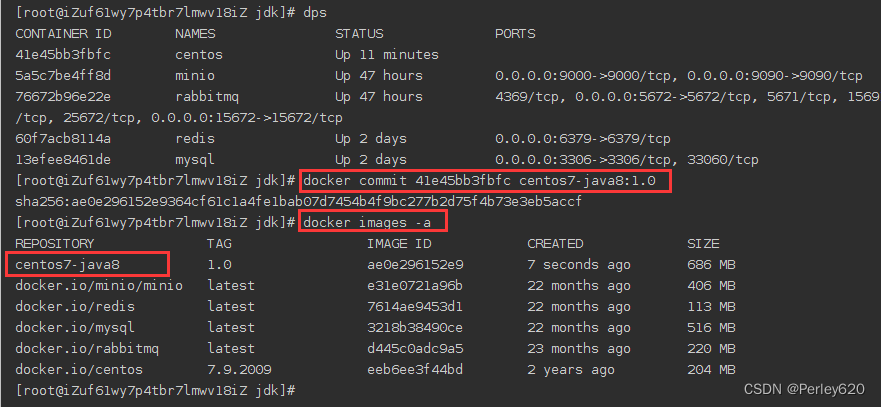
4、制作镜像
把centos7容器做成镜像
docker commit 6598a89db5f6 centos7-java8:1.0
docker images #可以查看到centos7-java8:1.0镜像
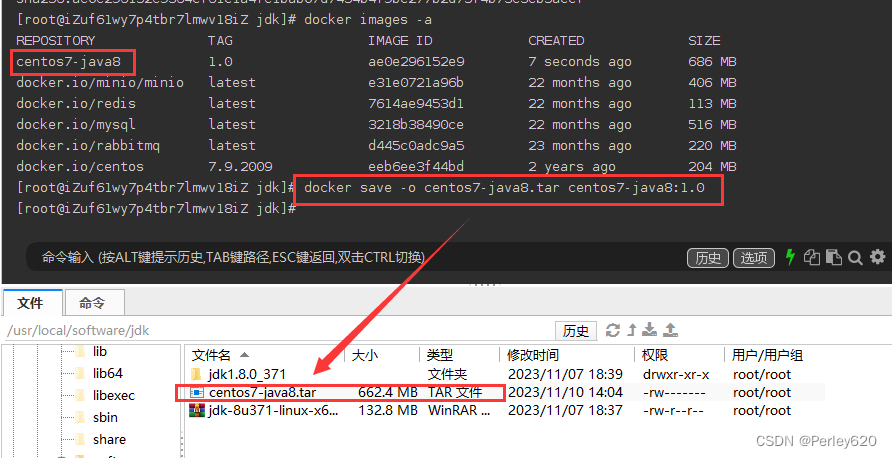
把镜像做成压缩包 放到宿主机的某个位置
docker save -o centos7-java8.tar centos7-java8:1.0
#-o:output 压缩文件保存到/root目录下
把压缩文件载入镜像(第三方载入该压缩包)
docker load -i centos7-java8.tar #镜像加载 -i (input)
docker images
用centos7-java8:1.0镜像做容器
docker run -id --name=centos7-java8 centos7-java8:1.0
docker exec -it centos7-java8 /bin/bash #进入容器
#或者启动并进入容器
docker run -it --name=centos7-java8 centos7-java8:1.0 /bin/bash
2、dockerfile方式
它是用来制作docker镜像的一个文本文件,文件包含了一条条的指令,每一条指令构建一层,基于基础镜像,最终构建出一个新的镜像,
- 对于开发人员:可以为开发团队提供一个完全一致的开发环境,
- 对于测试人员:可以直接拿开发时所构建的镜像或者用Dockerfile文件构建一个新的镜像开始工作了,
- 对于运维人员:在部署时,可以实现应用的无缝移植
| 关键字 | 作用 | 备注 |
|---|---|---|
| FROM | 指定父镜像 | 指定dockerfile基于那个image构建 |
| MAINTAINER | 作者信息 | 用来标明这个dockerfile谁写的 |
| LABEL | 标签 | 用来标明dockerfile的标签 可以使用Label代替Maintainer 最终都是在docker image基本信息中可以查看 |
| RUN | 执行命令 | 执行一段命令 默认是/bin/sh 格式: RUN command 或者 RUN [“command” , “param1”,“param2”] |
| CMD | 容器启动命令 | 提供启动容器时候的默认命令 和ENTRYPOINT配合使用 格式CMD command param1 param2 或者 CMD [“command” ,“param1”,“param2”] |
| ENTRYPOINT | 入口 | 一般在制作一些执行就关闭的容器中会使用 |
| COPY | 复制文件 | build的时候复制文件到image中 |
| ADD | 添加文件 | build的时候添加文件到image中 不仅仅局限于当前build上下文 可以来源于远程服务, ADD 源路径 目标路径 |
| ENV | 环境变量 | 指定build时候的环境变量 可以在启动的容器的时候 通过-e覆盖 格式ENV name=value |
| ARG | 构建参数 | 构建参数 只在构建的时候使用的参数 如果有ENV 那么ENV的相同名字的值始终覆盖arg的参数 |
| VOLUME | 定义外部可以挂载的数据卷 | 指定build的image那些目录可以启动的时候挂载到文件系统中 启动容器的时候使用 -v 绑定 格式 VOLUME [“目录”] |
| EXPOSE | 暴露端口 | 定义容器运行的时候监听的端口 启动容器的使用-p来绑定暴露 端口 格式: EXPOSE 8080 或者 EXPOSE 8080/udp |
| WORKDIR | 工作目录 | 指定容器内部的工作目录 如果没有创建则自动创建 如果指定 使用的是绝对地址 ,如果不是 / 开头那么是在上一条workdir的路径的相对路径 |
| USER | 指定执行用户 | 指定build或者启动的时候 用户 在RUN CMD ENTRYPONT执行的时候的用户 |
| HEALTHCHECK | 健康检查 | 指定监测当前容器的健康监测的命令 基本上没用 因为很多时候应用本身有健康监测机制 |
| ONBUILD | 触发器 | 当存在ONBUILD关键字的镜像作为基础镜像的时候 当执行 FROM完成之后 会执行 ONBUILD的命令 但是不影响当前镜像用处也不怎么大 |
| STOPSIGNAL | 发送信号量到宿主机 | 该STOPSIGNAL指令设置将发送到容器的系统调用信号以退出。 |
| SHELL | 指定执行脚本的shell | 指定RUN CMD ENTRYPOINT 执行命令的时候 使用的shell |
案例一:自定义centos7镜像
1、默认登录路径为 /usr
2、可以使用vim
步骤1:创建centos-dockerfile文件
mkdir docker-file
cd docker-file
[root@localhost docker-file]# vim centos-dockerfile
步骤2:文件内容如下
FROM centos:7 #原镜像
MAINTAINER tianju <tianju@tianju.cn>
RUN yum install -y vim
WORKDIR /usr
CMD /bin/bash
说明:
定义父镜像:FROM centos:7
定义作者信息:MAINTAINER tianju <tianju@tianju.cn
执行安装vim命令: RUN yum install -y vim
定义默认的工作目录:WORKDIR /usr
定义容器启动执行的命令:CMD /bin/bash
步骤3:通过dockerfile文件构建镜像
语法:docker build –f dockerfile的文件路径 –t 镜像名称:版本 .
docker build -f ./centos-dockerfile -t my_centos:1 .
docker images
注意事项:
利用当前centos-dockerfile文件构建镜像 -t my_centos:1 指定新镜像的名称和版本, 后面的 . 不能省略
参数:-f 表示dockerfile -t 表示tag
案例二:定义dockerfile文件构建镜像,发布springboot项目
步骤1:创建dockerfile文件并编写内容
vim springboot-dockerfile
编写如下内容
FROM java:8
MAINTAINER woniu<woniu@woniu.cn>
ADD springboot.jar app.jar
CMD java -jar /app.jar
说明:
ADD springboot.jar app.jar 表示把宿主机的springboot.jar复制到镜像里并更名为app.jar,当用镜像做容器时,app.jar默认在容器的根目录
步骤2:通过dockerfile构建镜像
docker build -f ./springboot-dockerfile -t springboot-app:1.0 .
步骤3:通过springboot-app:1.0镜像创建容器
docker run -it --name=app -p 8080:8080 springbootapp:1.0
docker logs --tail 100 -f app #查看app容器的日志末尾100行
总结
1.介绍docker的基本概念,拆解docker的结构;
2.常用的相关命令,进程命令和容器镜像命令;
3.制作镜像的两种方式,并给出操作案例。