做的网站怎么放视频海外市场推广做什么的
响应会员需求,晓零分享一份经典资料《120页ppt集团公司战略规划内容、方法、步骤及战略规划案例研究》,欢迎进入星球下载学习。
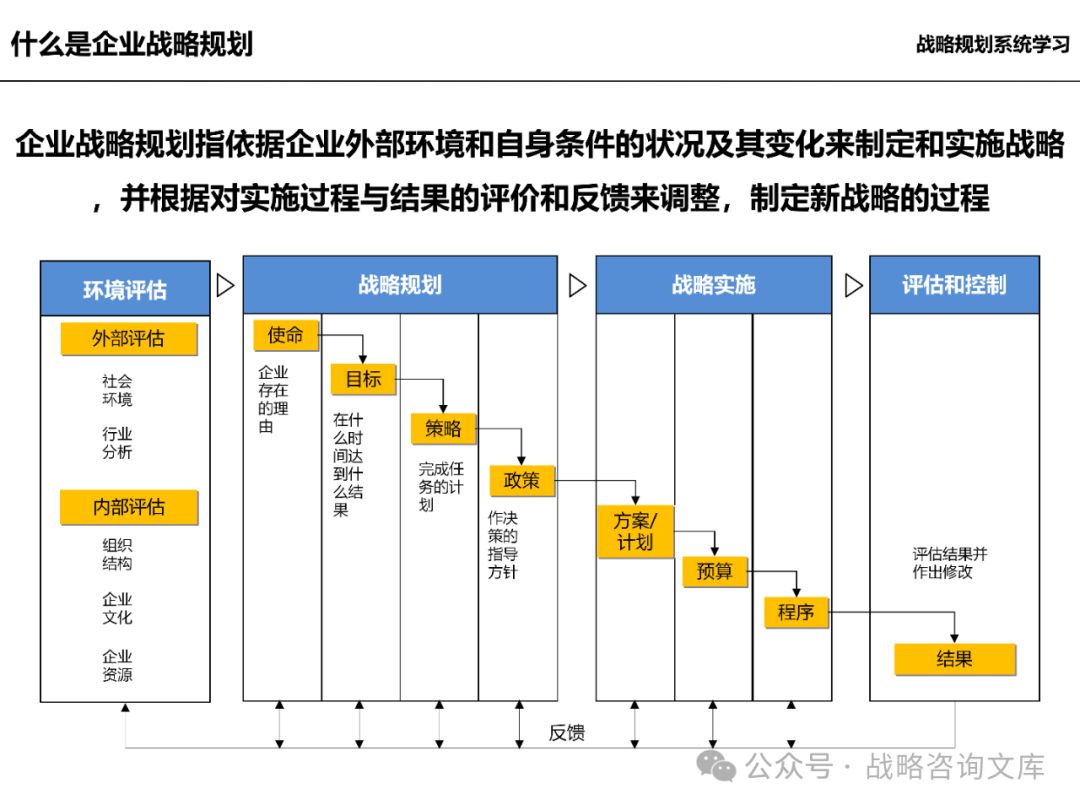
以下是对企业战略规划三个阶段八个步骤的详细解析:
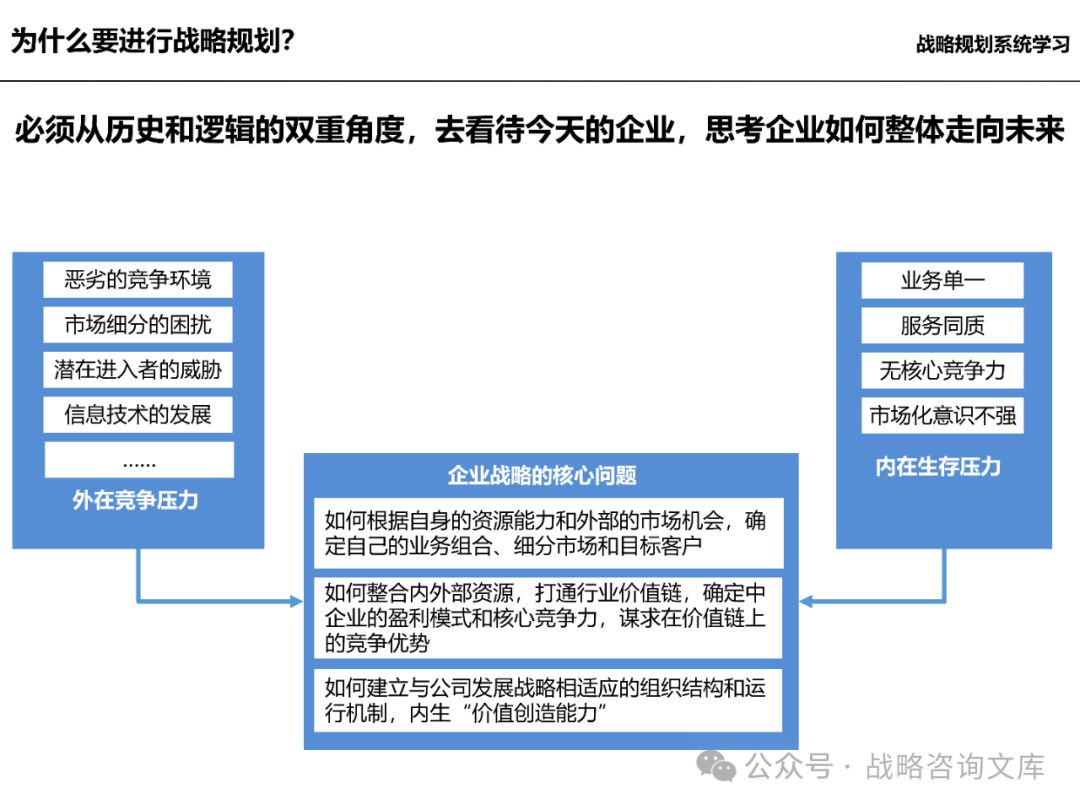
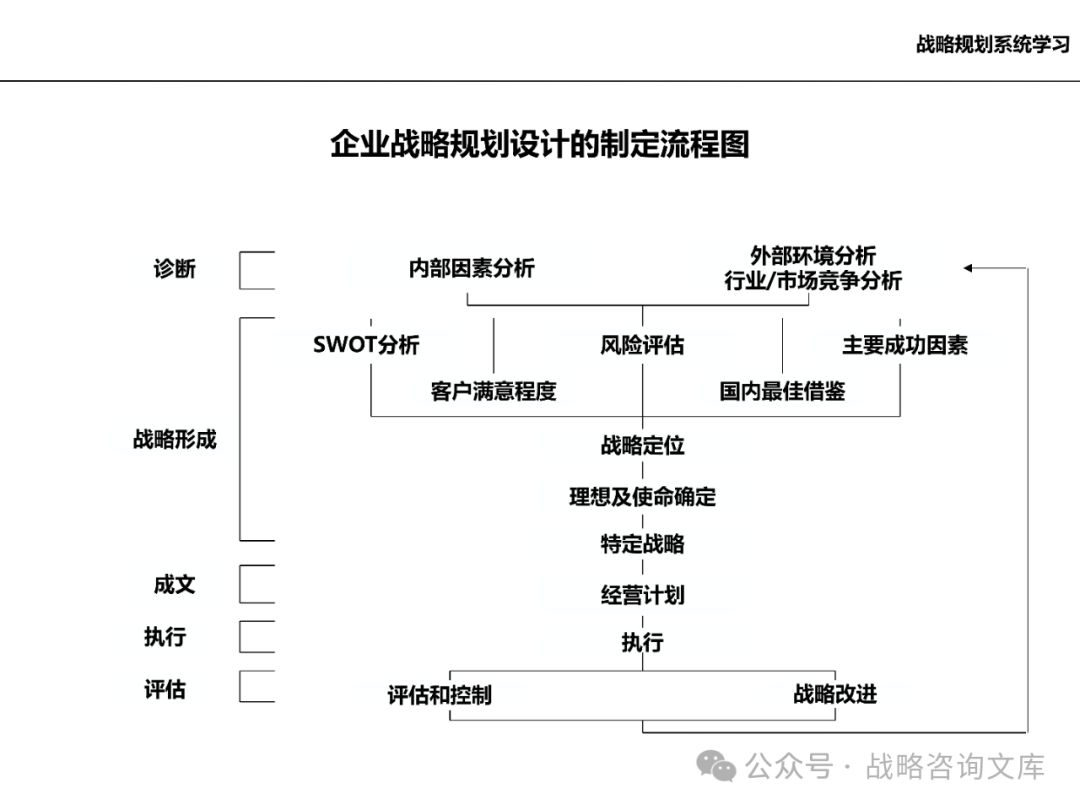
一、阶段一:内外分析
项目启动和前期准备:
明确战略规划的目标和范围,组建专业的规划团队,收集相关的基础资料和数据。
制定详细的项目计划和时间表,确保后续工作有序进行。
外部环境分析:
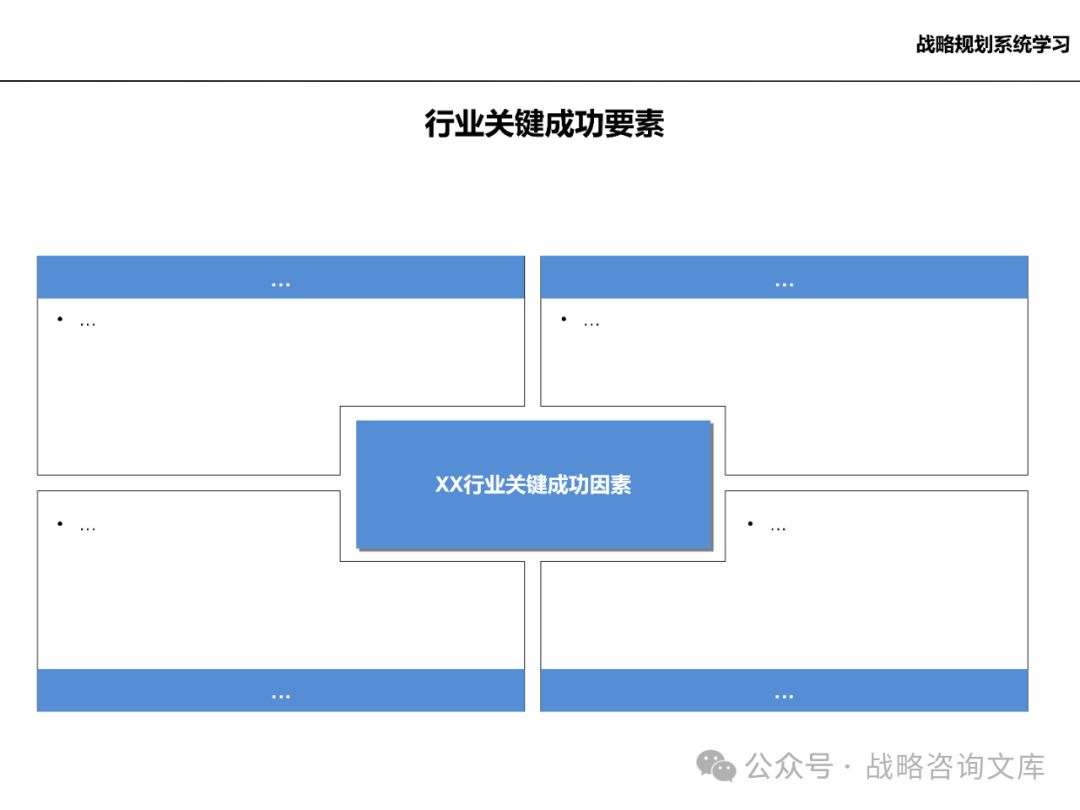
研究行业内成功企业的关键成功因素,如产品质量、品牌建设、客户服务等。
结合企业自身情况,确定企业在未来发展中需要重点关注的成功要素。
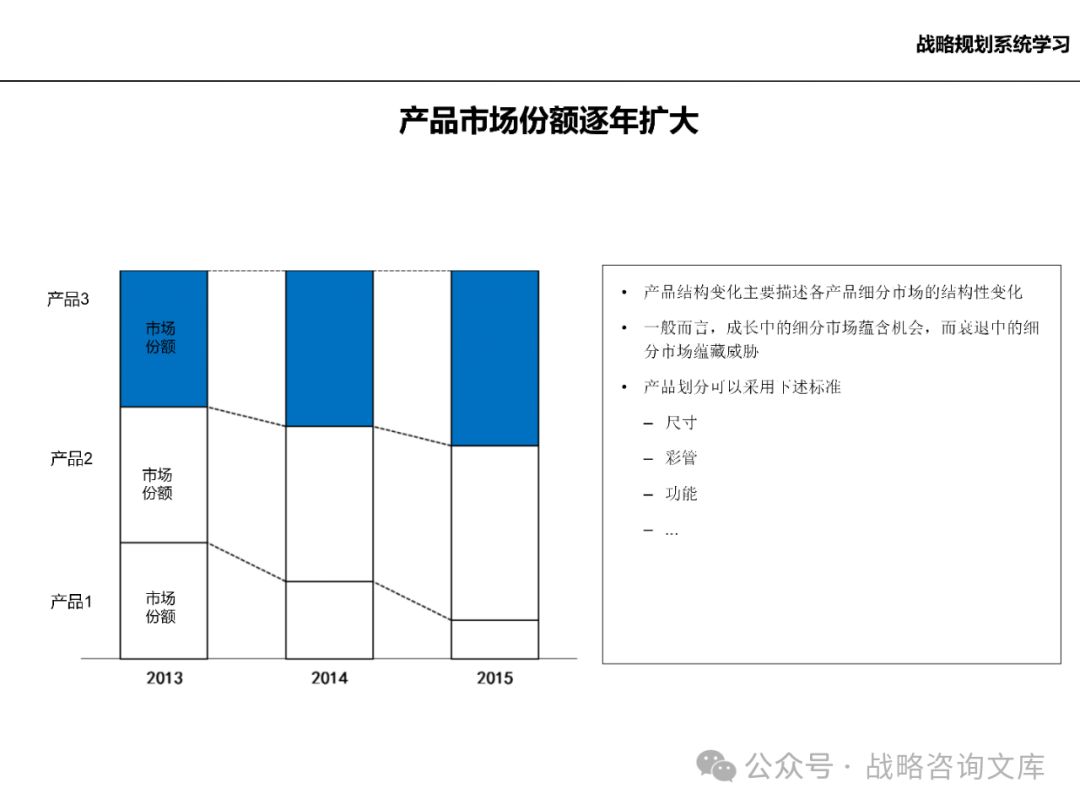
评估企业现有业务的发展潜力,包括市场份额增长、产品创新、业务拓展等方面。
分析潜在的业务机会,如新兴市场、新技术应用等,为企业未来发展提供方向。
评估市场的增长速度,判断行业的发展前景和潜力。
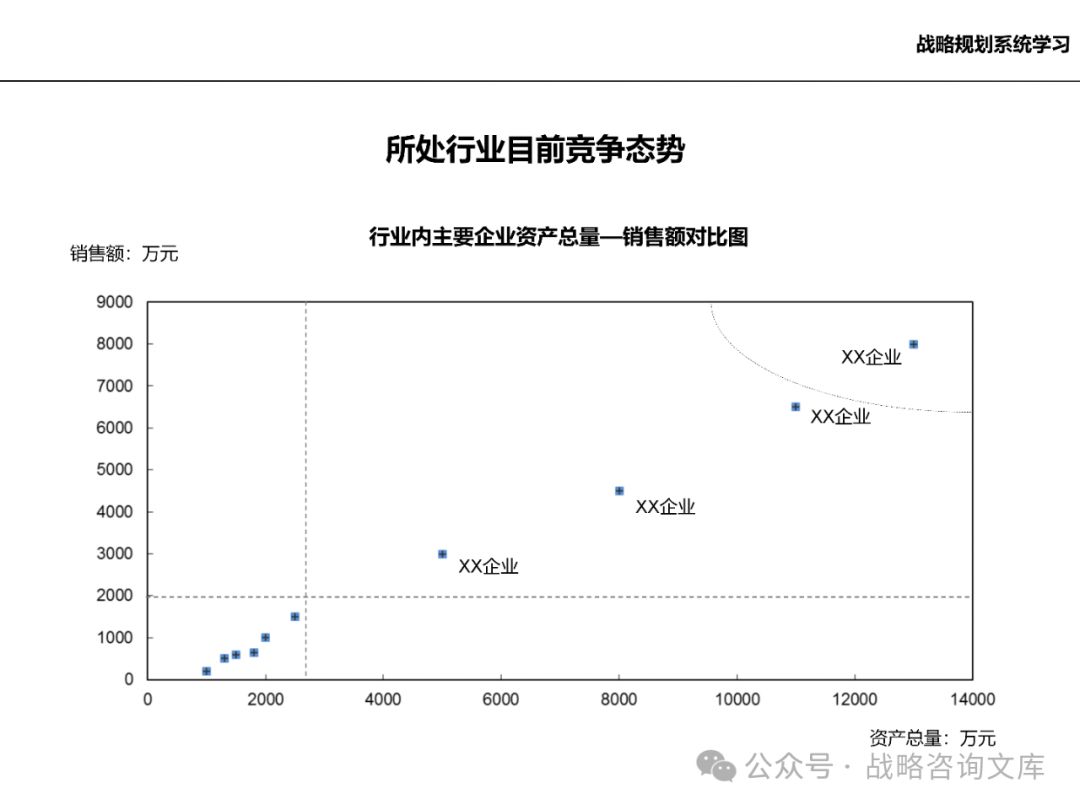
分析市场的集中程度,了解行业的竞争格局和企业的市场地位。
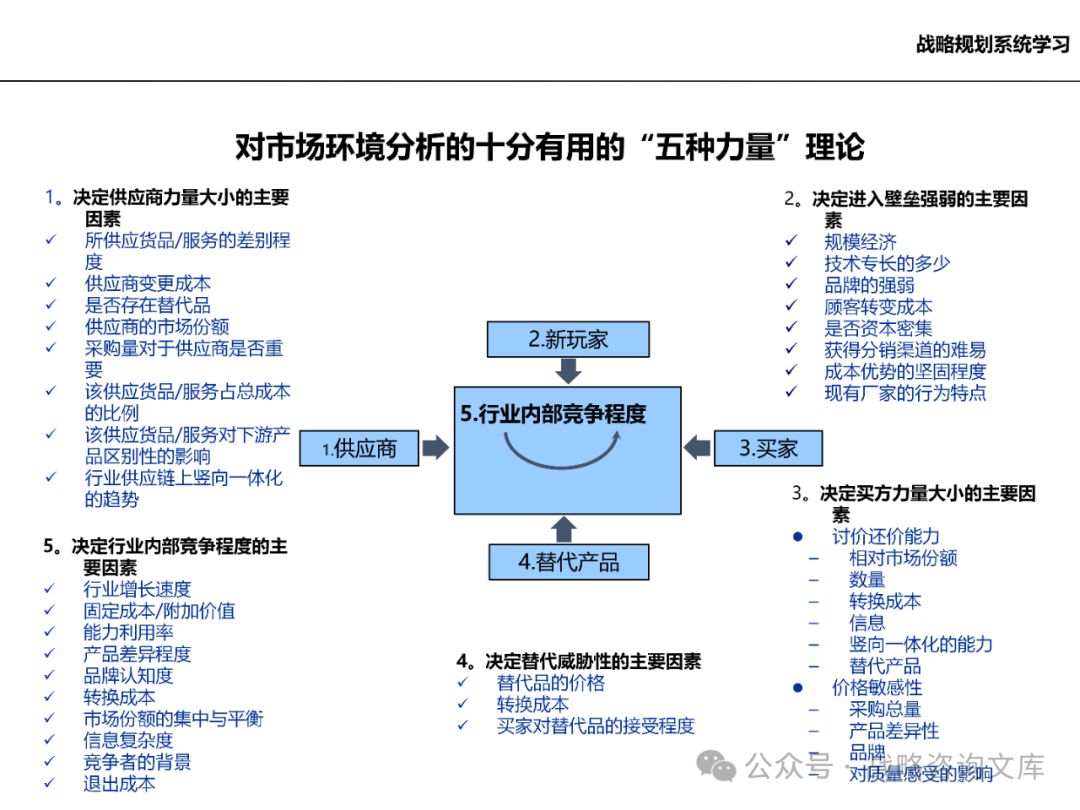
研究市场的竞争状况,包括竞争强度、竞争手段等,为企业制定竞争策略提供依据。
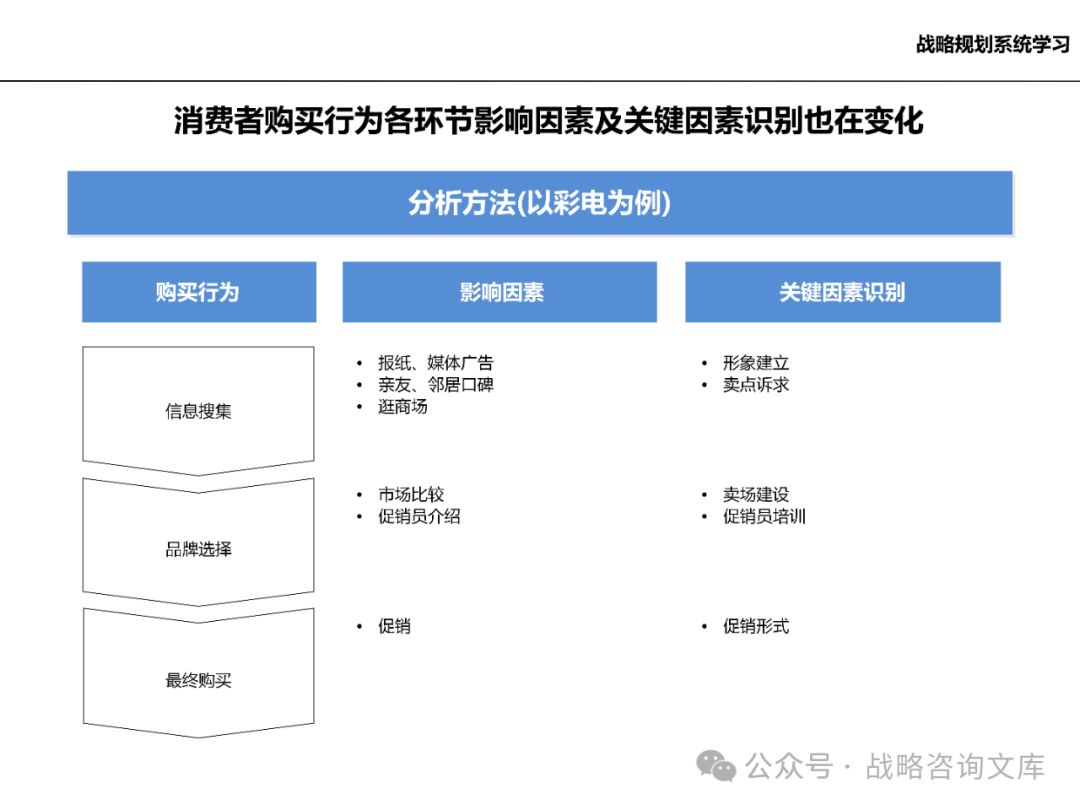
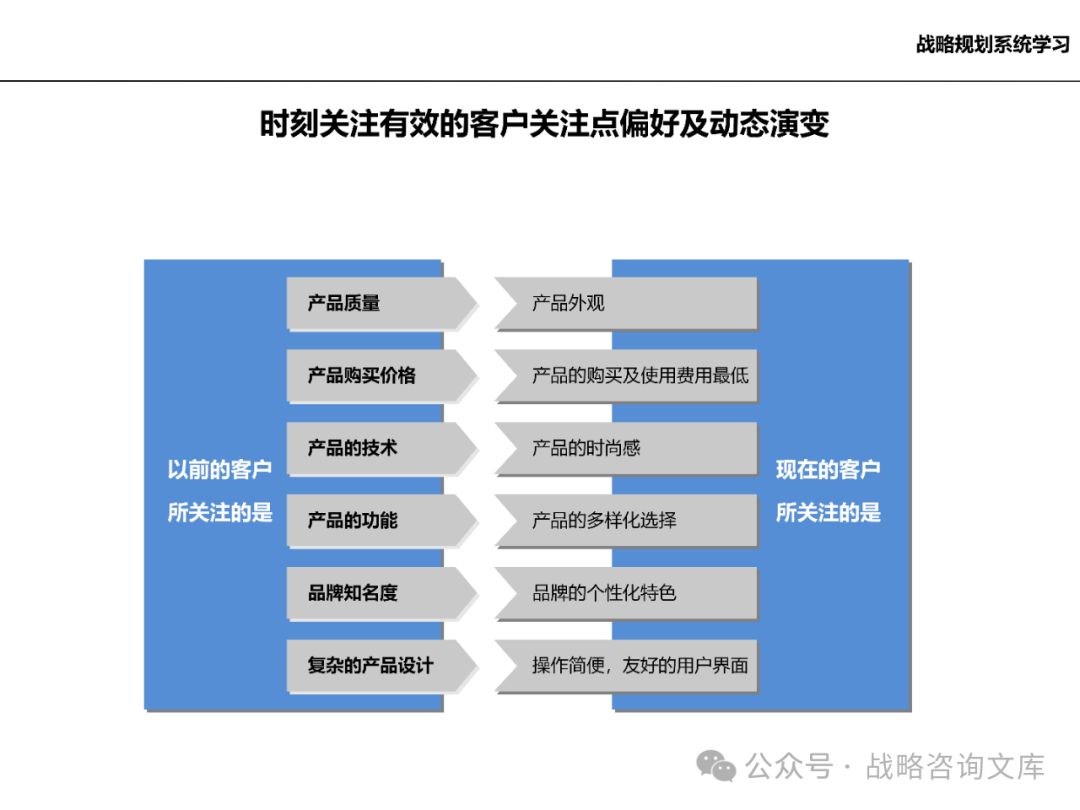
研究市场中的客户群体,了解其需求特点、购买行为和决策过程。
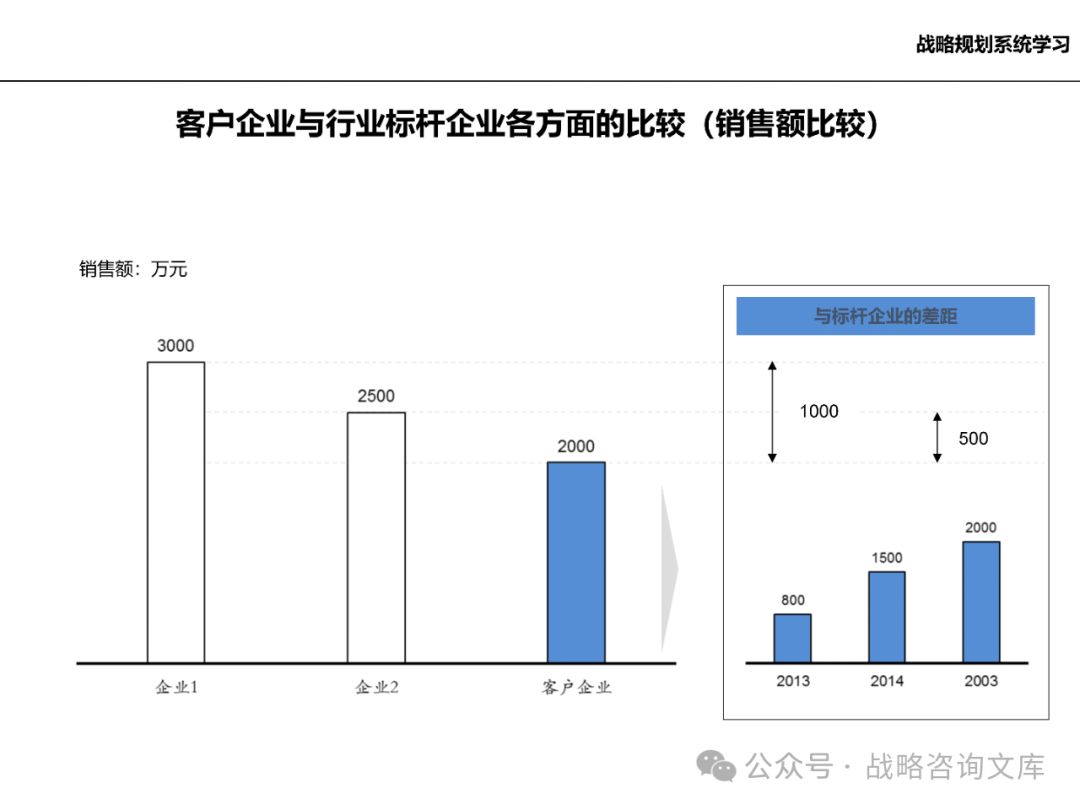
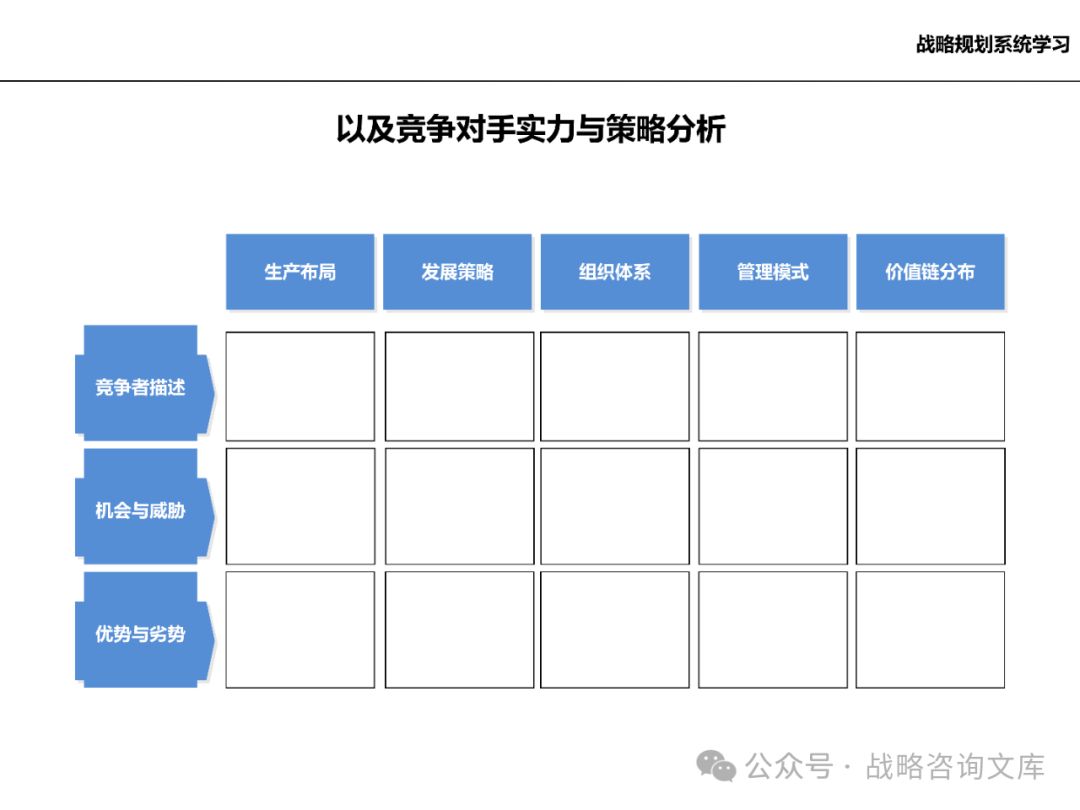
分析竞争对手的实力、市场份额、竞争策略等,评估企业的竞争地位。
考察供应商的议价能力、供应稳定性等因素,确保企业的供应链安全。
对市场进行细分,确定不同的细分市场类型和特点。
分析各细分市场的规模、增长速度、竞争状况等,为企业选择目标市场提供参考。
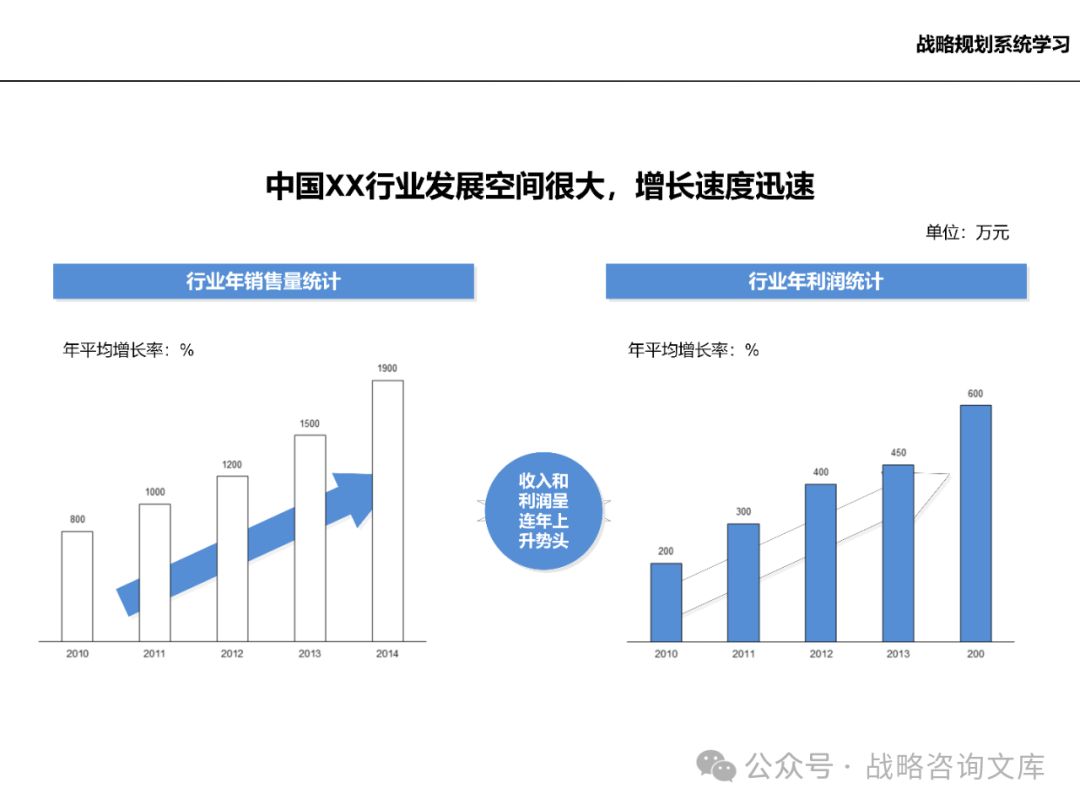
研究行业的总体规模和增长趋势,了解市场容量和潜力。
分析不同产品或服务的销售数量和收入情况,评估市场需求的变化。
关注行业利润率水平,了解企业在行业中的盈利空间。
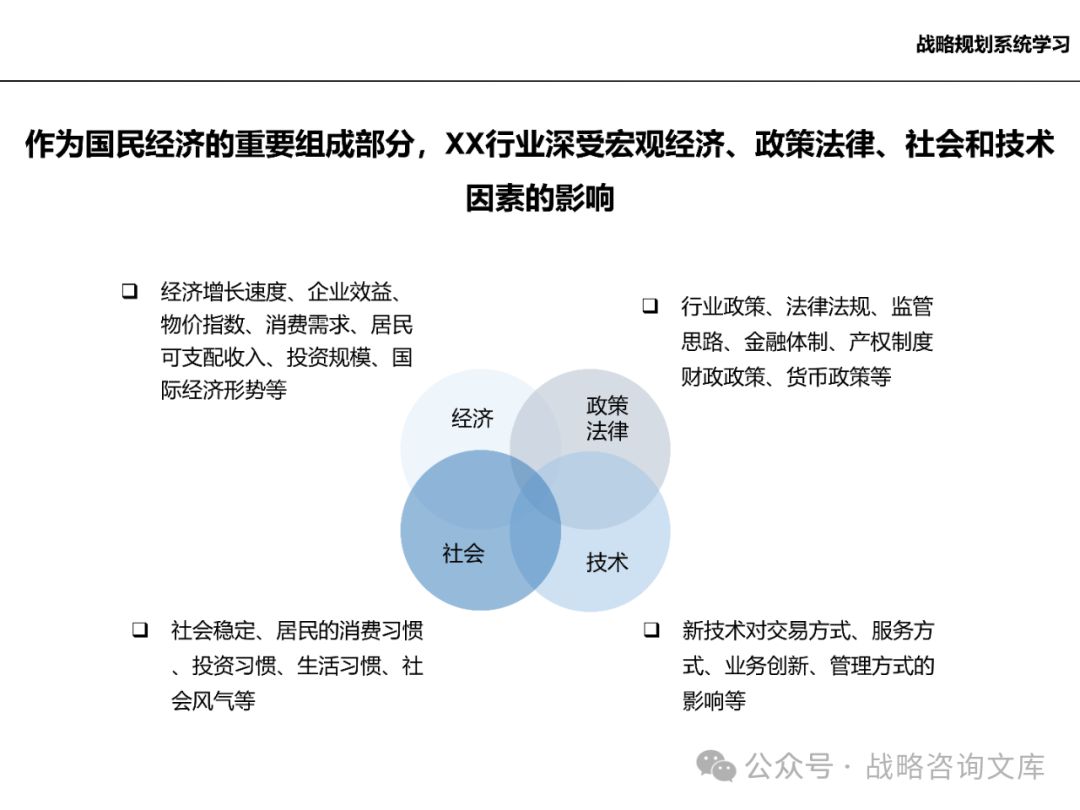
关注宏观经济形势、政策法规、技术发展趋势等因素,评估其对企业所处行业的影响。
分析宏观环境变化带来的机遇和挑战,为企业战略制定提供依据。
宏观研究和分析:
市场规模(行业收入、销售数量、利润率):
细分市场构成:
市场结构(客户、竞争者、供应商等):
市场特点(增长速度、集中程度、竞争状况):
业务潜力:
成功要素:
内部环境分析:
评估企业的资源状况,包括人力资源、财务资源、技术资源、品牌资源等。
分析企业的能力水平,如研发能力、生产能力、营销能力、管理能力等。
考察企业的核心竞争力,确定企业的竞争优势和劣势。
了解企业的文化价值观,评估其对企业战略实施的影响。
二、阶段二:战略规划和业务计划
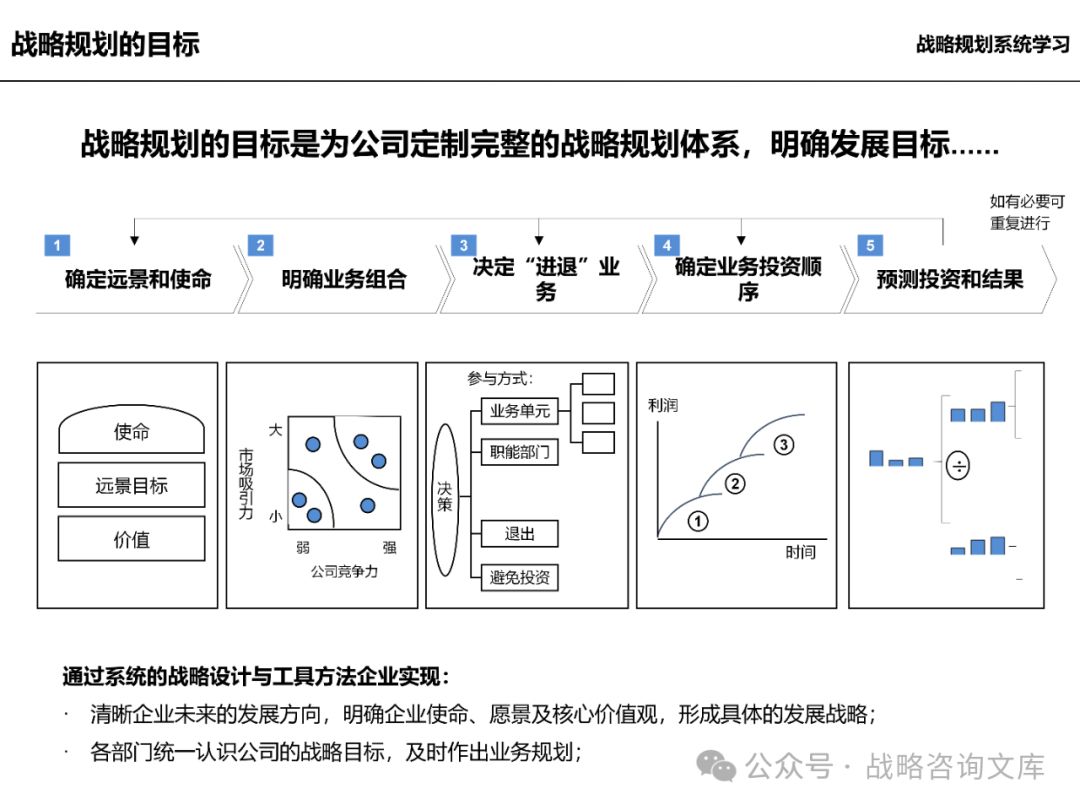
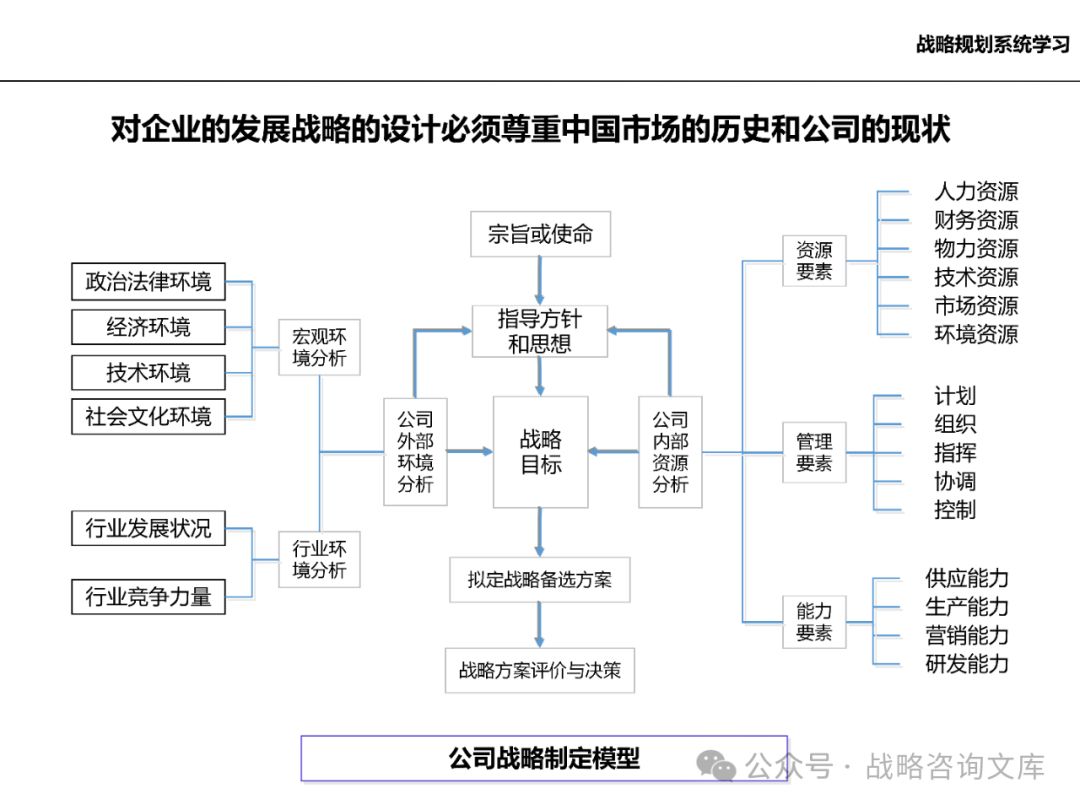
发展定位(战略规划):
企业远景:明确企业的长期发展愿景和使命,为企业战略制定提供方向和动力。
企业中长期的经营方向:确定企业在未来一段时间内的经营重点和发展方向,如市场拓展、产品创新、业务多元化等。
长期发展目标:制定具体的长期发展目标,如销售收入、市场份额、利润等指标,为企业战略实施提供量化的目标和考核标准。
业务组合:
业务单元、业务板块的划分标准:根据企业的业务特点和发展战略,确定业务单元和业务板块的划分标准,以便进行有效的业务管理和资源配置。
业务板块的独立发展任务和战略配合作用:明确各业务板块的独立发展任务和目标,同时考虑各业务板块之间的战略配合作用,实现企业整体战略的协同效应。
业务板块的定量指标(财务贡献):制定各业务板块的定量指标,如销售收入、利润、投资回报率等,以便对各业务板块的业绩进行评估和考核。
现有业务和公司向目标方案的过渡:制定现有业务向目标方案过渡的具体策略和措施,确保企业战略的顺利实施。
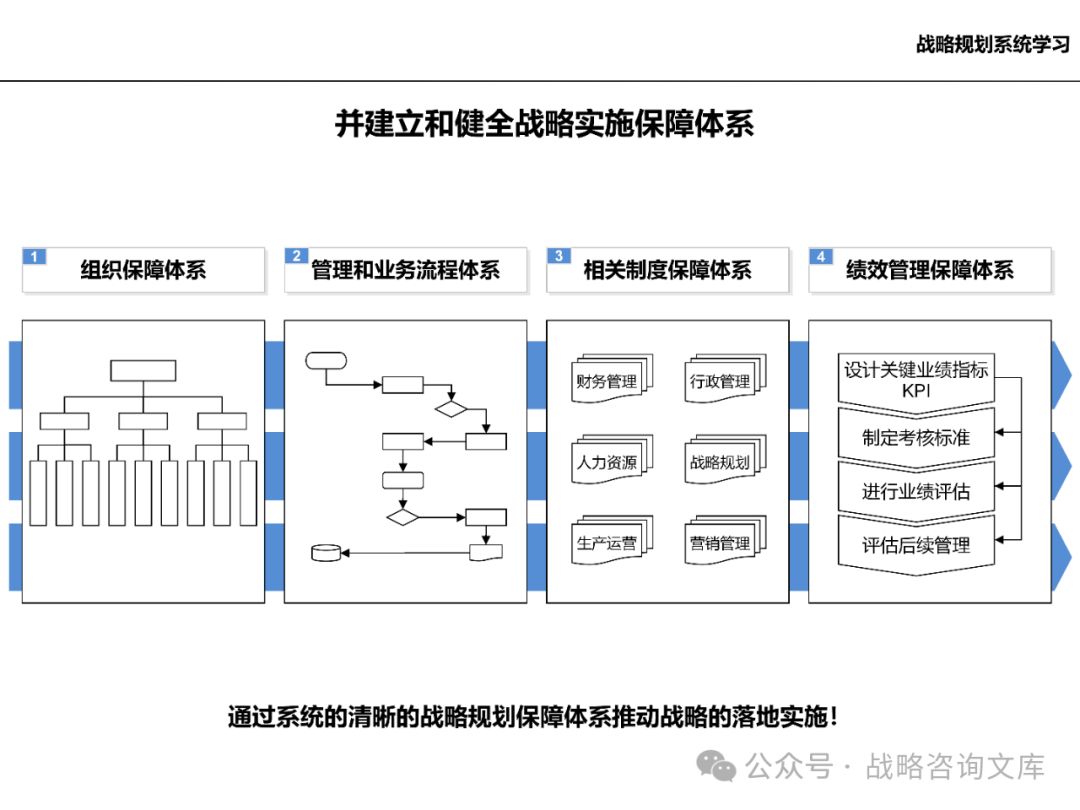
三、阶段三:组织结构和保障体系
企业组织结构:
企业结构的设计和职责界定:根据企业战略和业务需求,设计合理的企业组织结构,明确各部门的职责和权限。
企业职能部门岗位描述、人员编制和要求:对企业各职能部门的岗位进行描述,确定人员编制和岗位要求,为企业招聘和人才培养提供依据。
企业部门之间的协调:建立有效的部门之间的协调机制,确保企业内部各部门之间的沟通和协作顺畅。
企业部门与下属公司的关系界定:明确企业部门与下属公司之间的关系,包括管理权限、业务指导、绩效考核等方面。
业务体系:
战略管理:建立健全的战略管理体系,包括战略规划、战略实施、战略评估等环节,确保企业战略的有效实施。
行业研究:持续进行行业研究,了解行业动态和趋势,为企业战略调整提供依据。
年度计划:制定年度经营计划,明确各部门的工作目标和任务,确保企业年度经营目标的实现。
控制和偏差分析:建立有效的控制和偏差分析机制,及时发现和纠正企业经营中的问题,确保企业经营活动的顺利进行。
投资与股权管理:加强投资管理和股权管理,提高企业的投资回报率和资产运营效率。
投资管理:建立科学的投资决策机制,加强对投资项目的评估和管理,降低投资风险。
项目研究:对投资项目进行深入研究,包括市场前景、技术可行性、财务效益等方面,为投资决策提供依据。
投资决策:根据项目研究结果,做出科学的投资决策,确保企业的投资效益。
项目管理:加强对投资项目的管理,确保项目按时、按质、按量完成。
后期评估:对投资项目进行后期评估,总结经验教训,为企业未来的投资决策提供参考。
控制体系:
财务管理:建立健全的财务管理体系,包括预算管理、成本管理、资金管理等方面,确保企业财务状况的稳定和健康。
预算系统:制定科学的预算编制方法和流程,加强对预算执行的监控和考核,确保企业预算目标的实现。
汇报系统:建立完善的汇报制度,及时向企业管理层汇报企业经营情况和重大事项,为企业决策提供准确的信息支持。
控制系统:建立有效的内部控制体系,加强对企业经营活动的监督和控制,防范企业经营风险。
人力资源管理:建立健全的人力资源管理体系,包括招聘管理、员工培训、业绩评价、报酬体系等方面,为企业发展提供人才保障。
报酬体系:制定合理的报酬体系,激励员工的工作积极性和创造力,提高企业的绩效水平。
业绩评价:建立科学的业绩评价体系,对员工的工作业绩进行客观、公正的评价,为员工的晋升、奖励提供依据。
招聘管理:制定科学的招聘流程和标准,加强对招聘过程的管理,确保企业招聘到合适的人才。
员工培训:加强员工培训,提高员工的业务能力和综合素质,为企业发展提供人才支持。
121页PPT














平台已收录多份“战略规划”资料,欢迎下载
篇幅有限,扫码下载原文件
知识星球已上传的资料链接:
企业架构
企业架构 (EA) 设计咨询项目-企业架构治理(EAM)现状诊断
105页PPTHW企业架构设计方法及实例
麦肯锡X企业架构 (EA) 设计咨询项目系列资料—IT架构现状诊断
354页PPT—麦肯锡X企业架构 (EA) 设计咨询项目系列资料(7份完整版)
企业架构和IT战略规划项目PPT
77页PPT丨集团企业IT技术架构规划方案
80页PPT丨流程管理—企业业务流程及业务能力架构建模详细方法
144页PPT丨大型制造企业IT蓝图、信息化系统技术架构规划与实施路线方案
49页PPPT丨企业架构 (EA) 设计咨询项目-IT架构现状梳理
52页华为企业数据架构、应用架构及技术架构设计方法PPT
111页PPT丨埃森哲企业架构流程优化方法论BPR
采购及供应链
112页PPT丨罗兰贝格:某公司供应链优化咨询报告
171页PPT丨制造业采购供应链及财务管控业务流程蓝图规划
供应链管理降本增效图库,包括流程图、框架图、优化图、供应商管理
117页PPT丨集团公司卓越采购供应链管理体系规划
172页PPT丨某集团制造业数字化转型采购供应链及财务管控业务流程蓝图规划方案
供应链数字化转型顶层架构设计方案.pptx
三一集团供应链SCM计划管理现状及计划指标分析PPT
153页PPT丨石化企业一体化供应链与物流平台建设总体方案设计
230页PPT丨供应链协同管理蓝图规划项目整体解决方案
72页PPT丨智能制造基于C2M供应链IT总体规划项目建议方案
54页PPT丨供应链与生产制造L1-L4级高阶流程规划框架PPT
智能制造
130PPTSAP汽车制造企业ERP蓝图规划整体解决方案
86页PPT敏捷制造与卓越服务业务模型设计(交付版)
92页PPTEPC工程总包项目型成套SAP ERP解决方案
171页PPT制造业采购供应链及财务管控业务流程蓝图规划
82页PPT丨精益智能工厂数字化转型、制造工厂蓝图三年规划方案
装备制造业 SCM应用系统集成组顶层设计PPT
装备制造企业IT信息化整体规划及ERP咨询规划解决方案PPT
92页PPT丨大型制造业智能制造数字化转型规划项目报告
144页PPT丨大型制造企业IT蓝图、信息化系统技术架构规划与实施路线方案
159页PPT丨制造企业PLM+ERP+MES+DMS信息化建设方案
72页智能制造基于C2M供应链IT总体规划项目建议方案PPT
60页PPT车辆制造企业信息化建设总图及ERP项目信息化建设方案
供应链与生产制造L1-L4级高阶流程规划框架PPT
流程管理
236页PPT | 埃森哲集团数字化转型流程框架详解
60页PPT如何打造高效的研发IPD流程体系
120页PPT丨某大型集团流程优化与系统实施项目
120页PPT丨医药集团公司IT信息化顶层规划报告
麦肯锡-高绩效运营管理培训之--质量流程控制图
70页PPT丨流程管理之流程化设计思路
58页PPT丨流程管理实用方法
33页PPT丨流程管理—LTC流程介绍
34页PPT丨学习华为:以客户为中心的营销体系,
供应链管理降本增效图库
69页PPT《向流程要利润》:构建精益化流程管理体系及降本增效
132页PPTEPF企业流程框架、项目咨询设计方法论
91页流程管理-企业流程管理项目实施宝典:从战略制定到执行
66份全套公司管理流程图
75页PPT丨x股份有限公司组织结构及流程优化咨询项目
115页PPTIPD端到端流程培训方案(精品)
53页PPT产品研发创新体系流程规划
124页PPT集团流程优化与信息化总体规划报告
83页PPT丨集团公司业务流程BPM能力框架体系
107页PPT丨IT战略规划与流程标准化咨询项目规划方案
169页PPT丨华为流程管理体系构建与落地
67页PPT丨集团公司流程管理方法论
80页PPT丨流程管理—企业业务流程及业务能力架构建模详细方法
120页某大型集团流程优化与系统实施项目
124页PPT丨集团流程优化与信息化总体规划报告
72页PPT丨S&OP计划管理流程体系变革运营规划方案
153页PPT丨咨询公司流程管理体系规划建设方法论
220页WORD丨华为IPD流程指南第3.0版
111页PPT丨埃森哲企业架构流程优化方法论BPR
某大型集团管控制度流程PPT
92页PPT丨德勤卓越业务流程管理方法论及案例PPT
200页PPT丨XX集团流程优化及IT规划项目规划完整版
43页PPT【流程管理】IBM流程优化方法论培训教材
98页PPT营销计划与管理流程图
230页【流程管理】某公司业务流程优化设计报告
战略规划
90页详解战略规划方法论系列:业务领先模型(BLM)理论与实践
99页PPT大型医药集团战略规划方案
119页PPT五大咨询公司IT战略规划方法论
108页PPT麦肯锡:以价值为导向的企业战略规划
74页PPT麦肯锡B2B行业产品组合、产品线战略规划手册
43页PPT企业战略规划及战略规划方法论
120页ppt丨集团公司战略规划内容、方法、步骤及战略规划
企业架构和IT战略规划项目PPT
107页PPT丨IT战略规划与流程标准化咨询项目规划方案
200页PPT丨IT战略规划-架构设计报告
92页让战略活起来:战略目标分解培训
模型工具
111页PPT素质模型应用汇报会材料
86页PPT敏捷制造与卓越服务业务模型设计(交付版)
顶尖战略咨询公司常用的21种数据分析模型
23个数字化转型顶层思维之企业管理模型(精华版)PPT
63页麦肯锡结构化战略思维模型:如何想清楚-说明白-做到位
130个商业模型大全
十大战略管理分析工具
KISS复盘模型、GRAI复盘法模板、项目复盘画布模板
2024中国百模大战竞争格局分析报告
企业管理咨询常用的12种工具
战略咨询工具汇总
50页PPT质量管理常用五大工具七大手法
企业战略管理工具+最全面的企业管理的29种分析工具
PDCA、5W1H、QC七大手法管理工具
93页MBTI经典资料:持续变革的4大举措,3大关键技巧及工具
HUAWEI系列
88页PPT华为PDT经理角色认知培训教材
80页华为以客户为中心的核心价值观和管理哲学
118页PPT华为铁三角工作法完全解密
123页PPT丨华为项目管理基础培训
169页丨华为流程管理体系构建与落地
55页ppt丨华为集成服务交付ISD业务变革总体方案
【华为系列】华为质量管理手册(完整版)-30页
【采购管理】华为采购理念与采购运作剖析41页
52页华为企业数据架构、应用架构及技术架构设计方法
220页WORD华为IPD流程指南第3.0版
数字化转型
117页丨埃森哲:大型制造型集团五年发展战略规划项目规划方案
155页ppt丨大型再生资源集团数字化转型SAP解决方案参考
82页PPT丨精益智能工厂数字化转型、制造工厂蓝图三年规划方案
155页ppt丨大型再生资源集团数字化转型SAP解决方案参考
102页PPT丨新一代数字化转型信息化总体规划方案
供应链数字化转型顶层架构设计方案.pptx
189页PPT丨工程车辆集团数字化转型SAP解决方案
236页PPT丨麦肯锡制药企业数字化转型项目顶层规划方案
353页某大型汽车集团互联网数字化转型建设顶层战略设计方案