网络媒体设计seo免费课程视频
一、Windows Server 2003
打开服务器,点击左下角开始➡管理工具➡管理您的服务器➡添加或删除角色
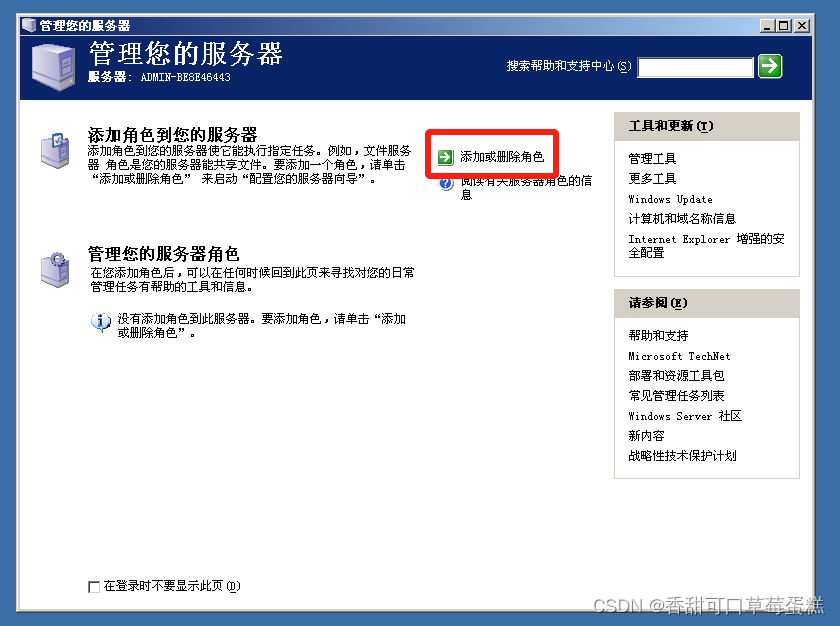
点击下一步等待测试
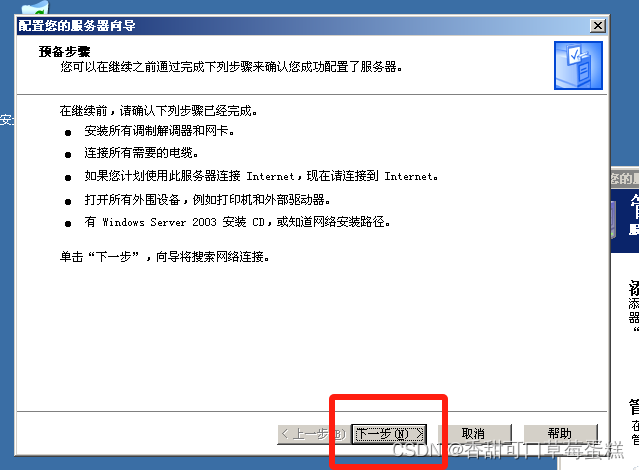
勾选自定义配置,点击下一步
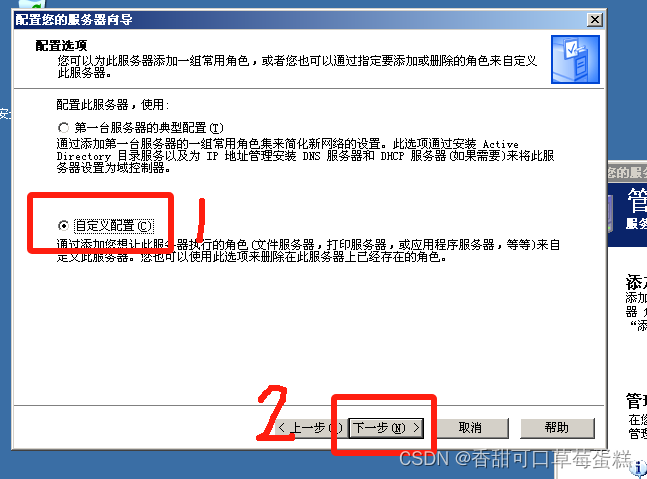
选择文件服务器,点击下一步
勾选设置默认磁盘空间,数据自己更改,最后点击下一步

默认不启用索引(除非你有上千个文件,否则这非常消耗服务器),点击下一步
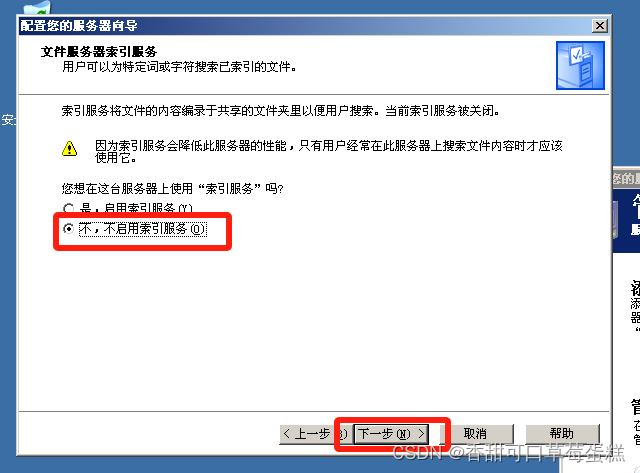
点击下一步

点击下一步

点击浏览选择文件夹,点击下一步
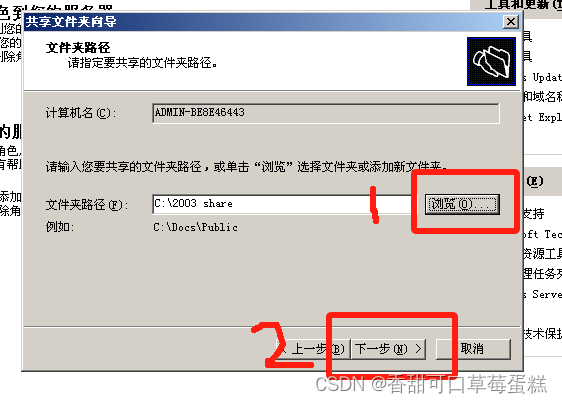
这里可以跳过直接下一步
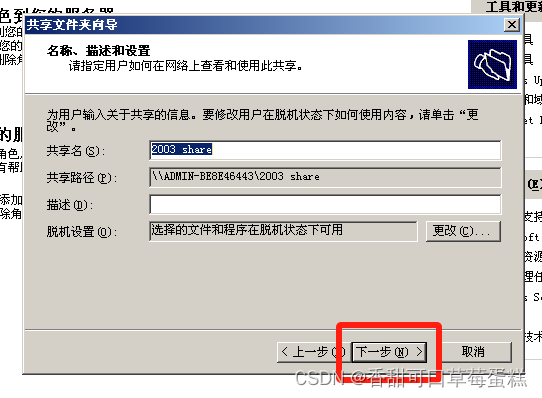
这里自己选择权限即可,点击完成

点击关闭,还想创建的话勾选选项即可

点击完成

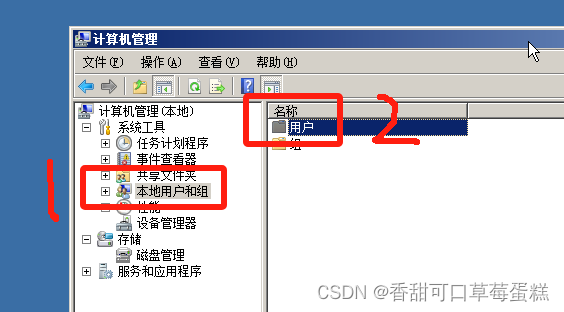
点击开始➡管理工具➡计算机管理,展开本地用户和组,点击用户

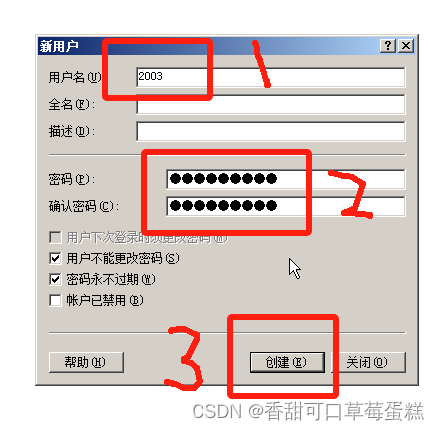
右键用户点击新用户,输入用户名密码,点击创建
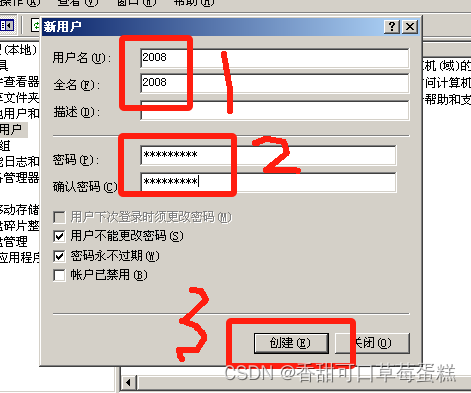
打开另一台服务器输入 \\2003IP地址 进行登录

二、Windows Server 2008
点击开始➡管理工具➡服务器管理器➡添加角色
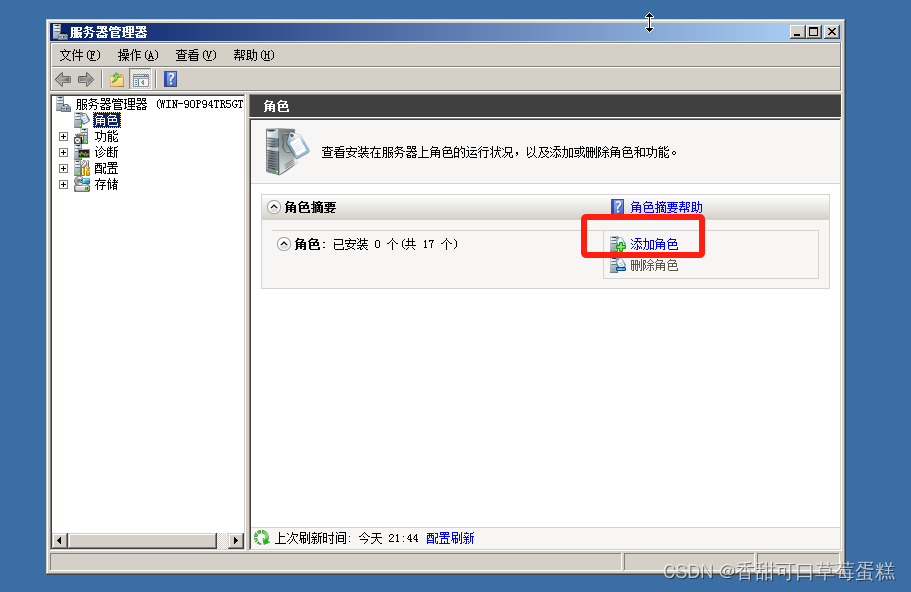
勾选默认跳过,点击下一步

勾选文件服务器,点击下一步

点击下一步
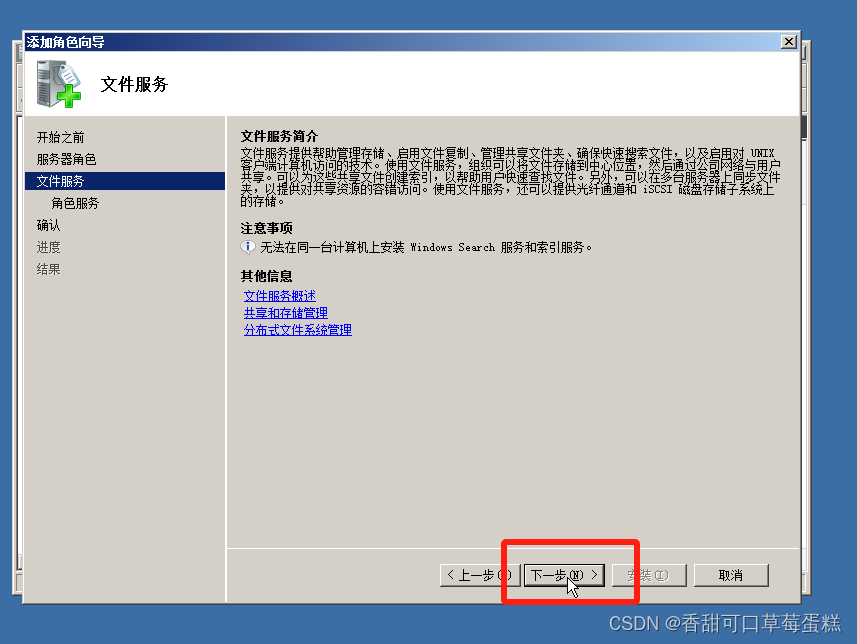
默认只安装文件服务器,点击下一步
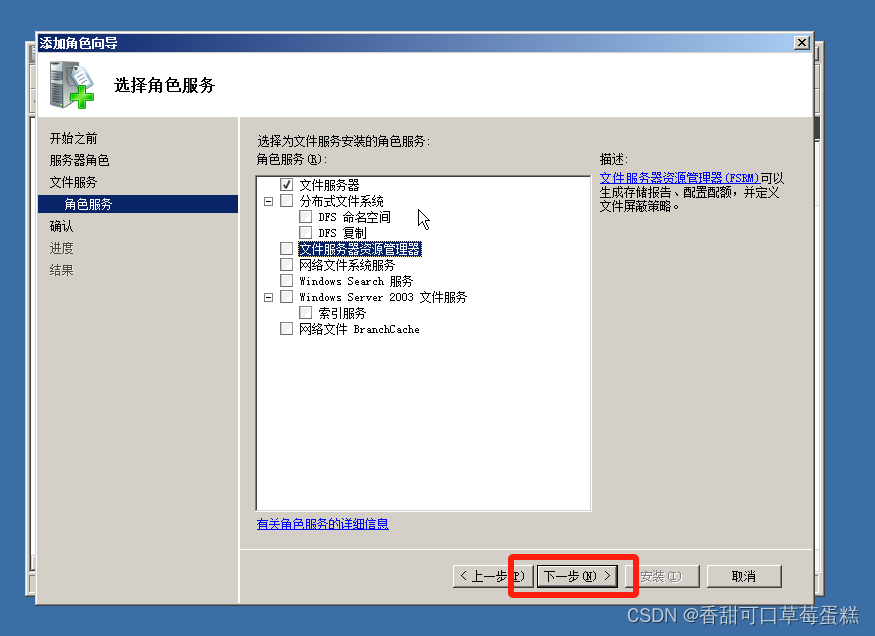
点击安装
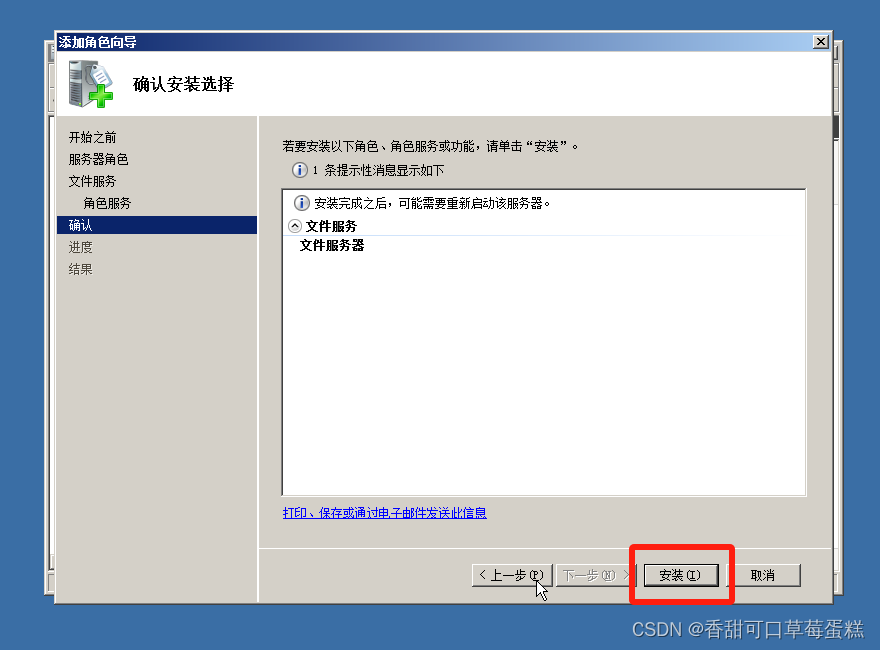
安装完成点击关闭
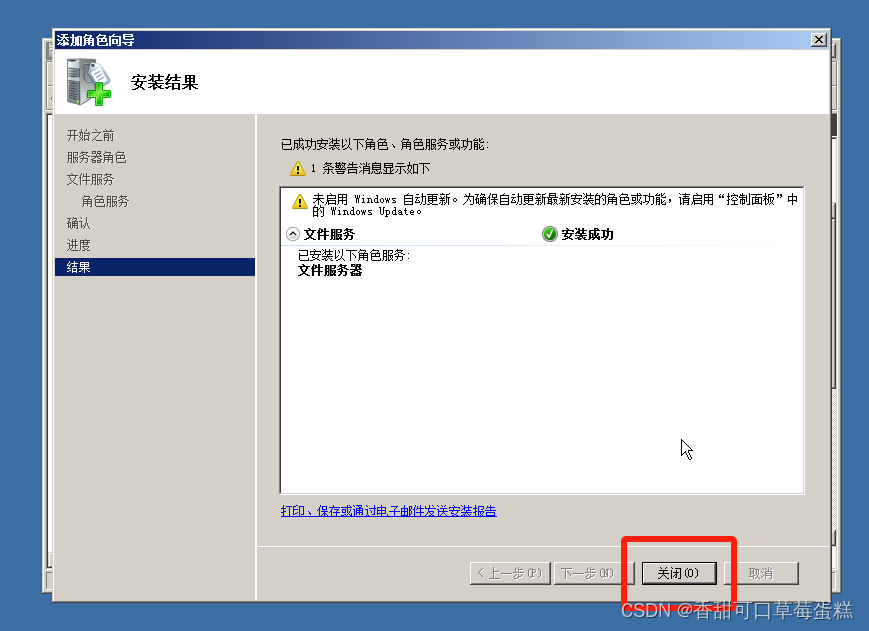
还在打开服务器管理器,一直向下展开找到共享和存储管理,右边点击设置共享

点击浏览选择文件夹,点击下一步
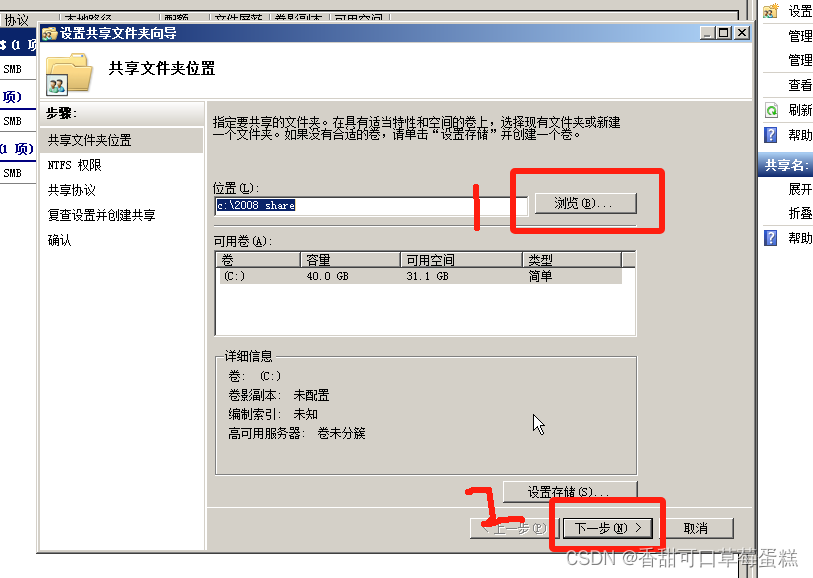
默认不更改,点击下一步
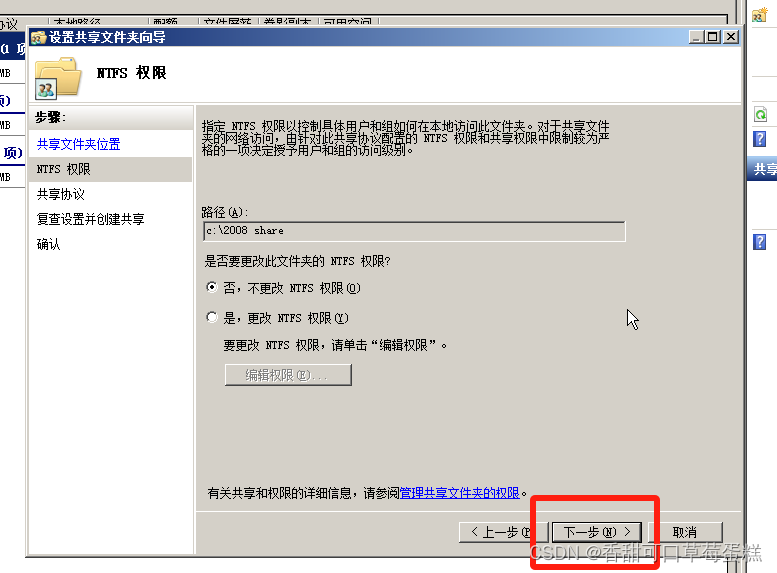
点击下一步

点击下一步

点击下一步
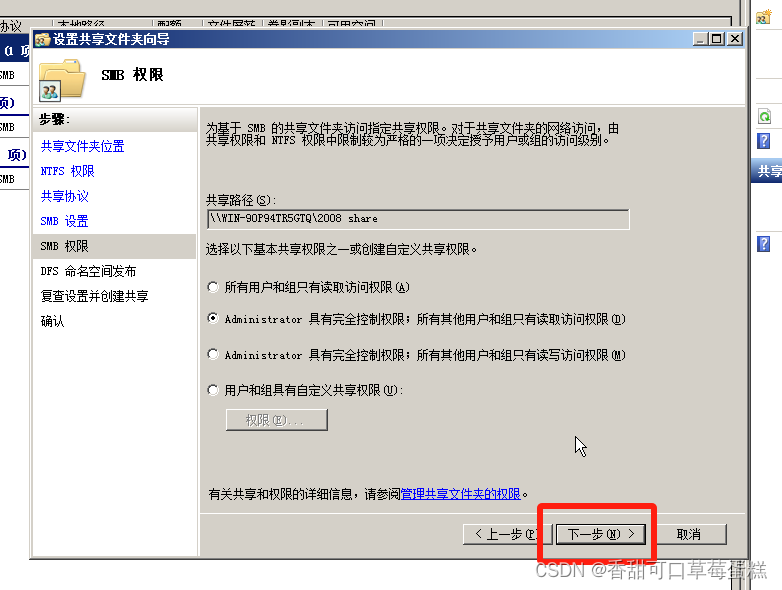
点击下一步

点击创建

点击关闭
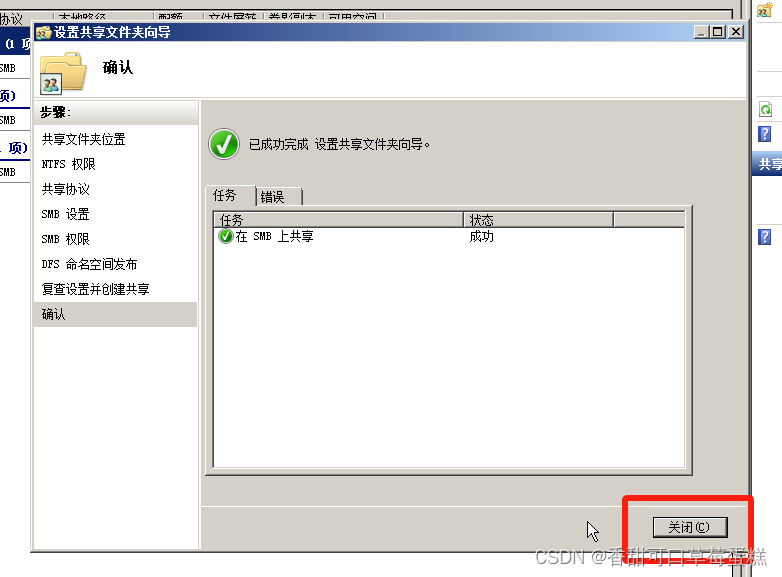
点击开始➡管理工具➡计算机管理,点击本地用户和组,右键用户,点击新用户
输入用户名和密码后点击创建
在另一台虚拟机测试登录

三、Windows Server 2012
点击左下角第一个图标打开服务器管理器

可以发现已经默认安装了文件服务器
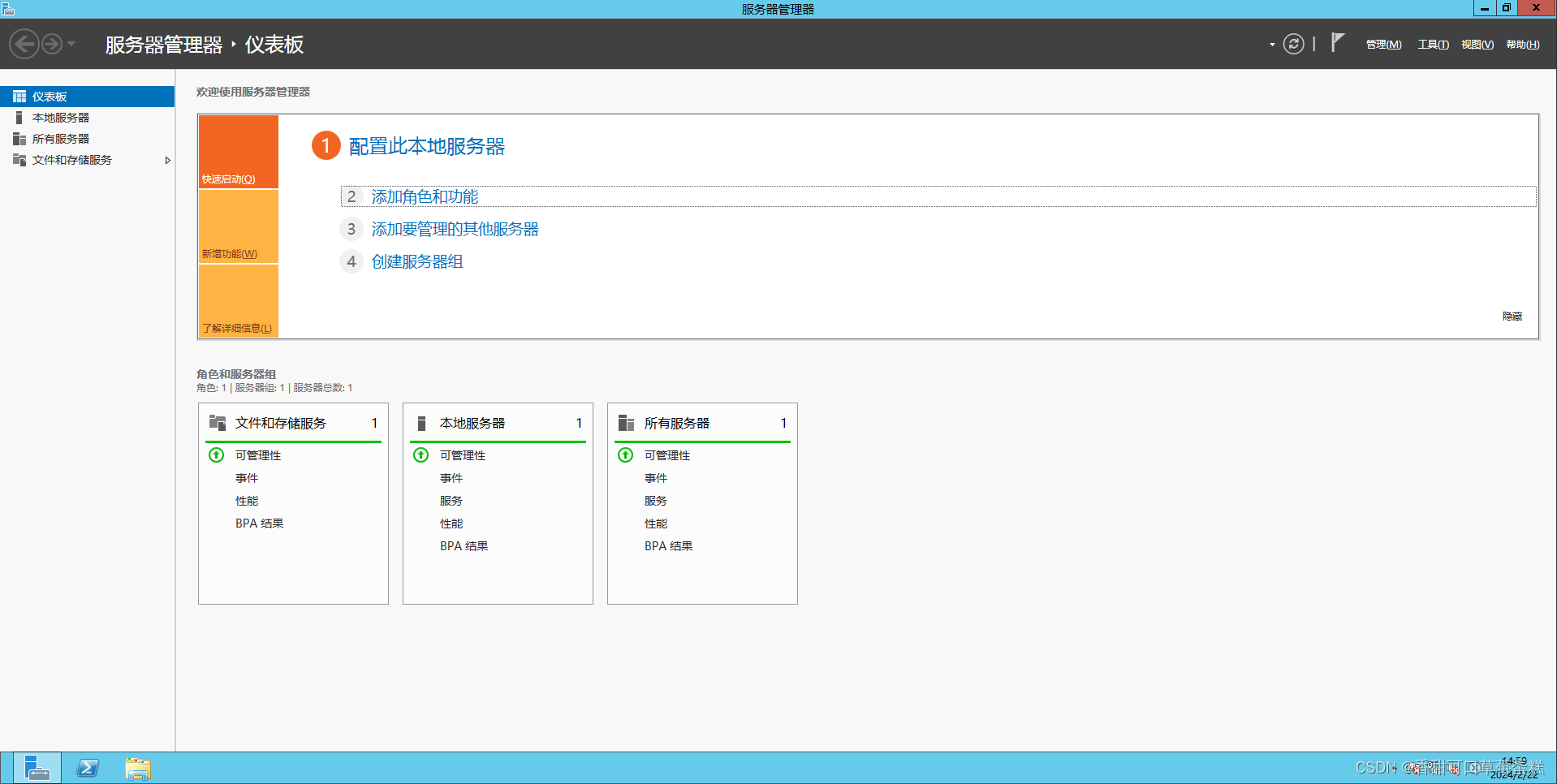
所以咱们只需建立共享文件夹及创建访问用户即可
点击右上角的工具➡计算机管理
点击共享文件夹,右键共享点击新建共享

点击下一步

点击浏览选择文件夹,点击下一步
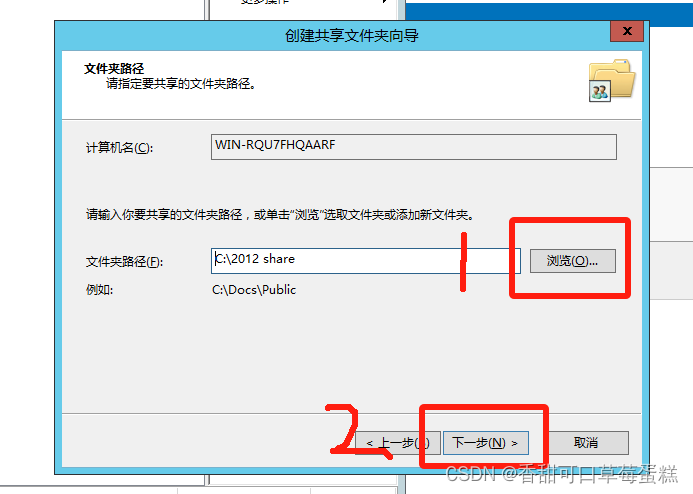
点击下一步

选择权限类型后点击完成
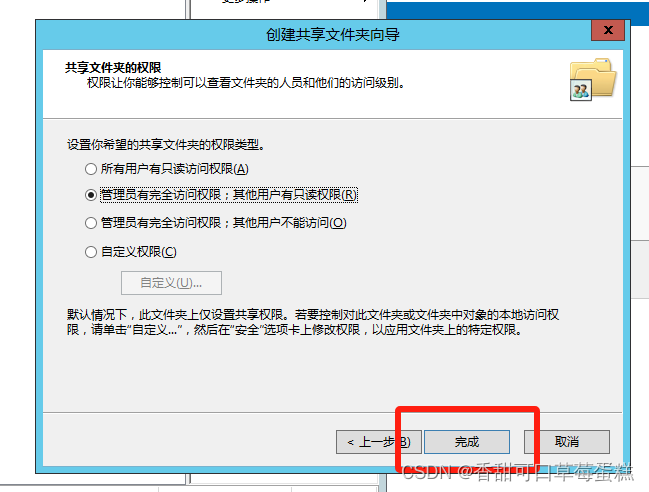
点击完成(想继续创建则勾上选项即可)

还是打开计算机管理,点击本地用户和组,右键用户新用户
输入用户名及密码,点击完成
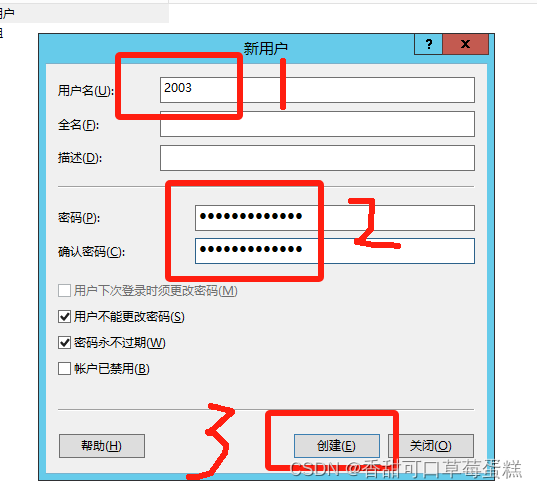
点击关闭

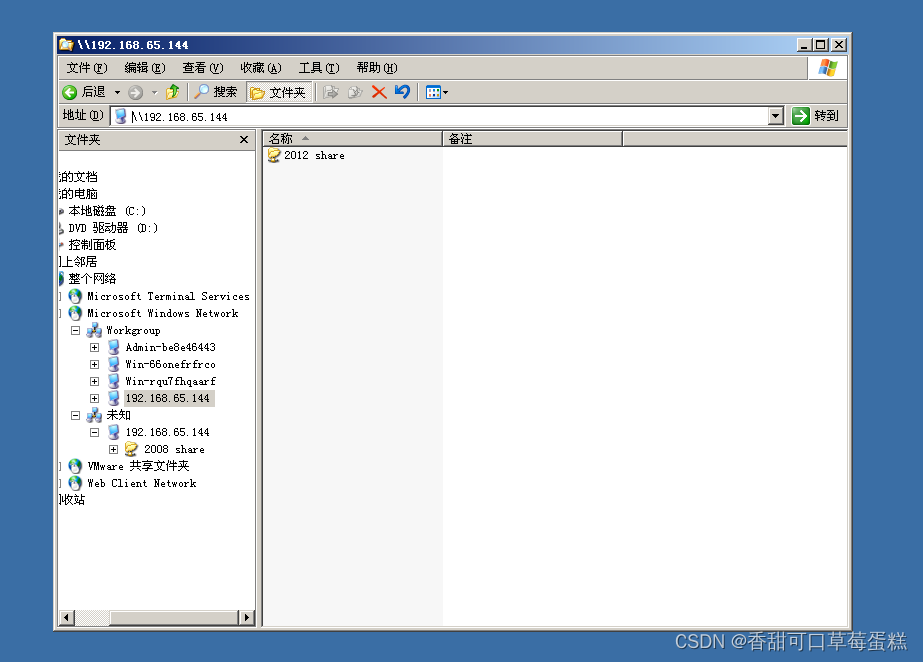
登录访问测试
四、Windows Server 2016
按 Win 键点击服务器管理器
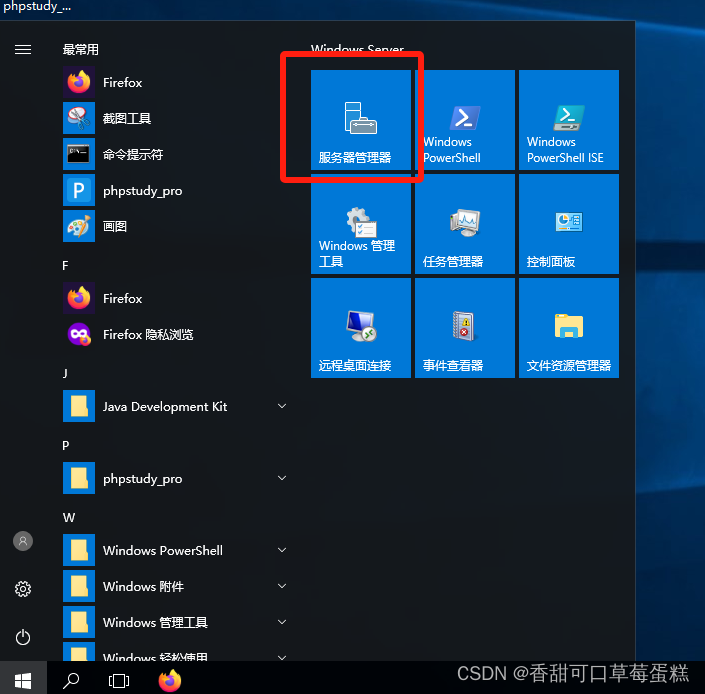
接下来的步骤和 2012 版本是一模一样滴
五、Windows Server 2019
步骤与 2016 版本一致