江西网站建设公司哪家好html网页模板
一、前言
最新版的企微机器人已经集成 Chat ,无需开发可快速搭建智能对话机器人。
从官方介绍看目前集成版本使用模型为 3.5-turbo。
二、入门
-
创建 WorkTool 机器人
你可以通过这篇快速入门教程,来快速配置一个自己的企微机器人。实现的流程如图:
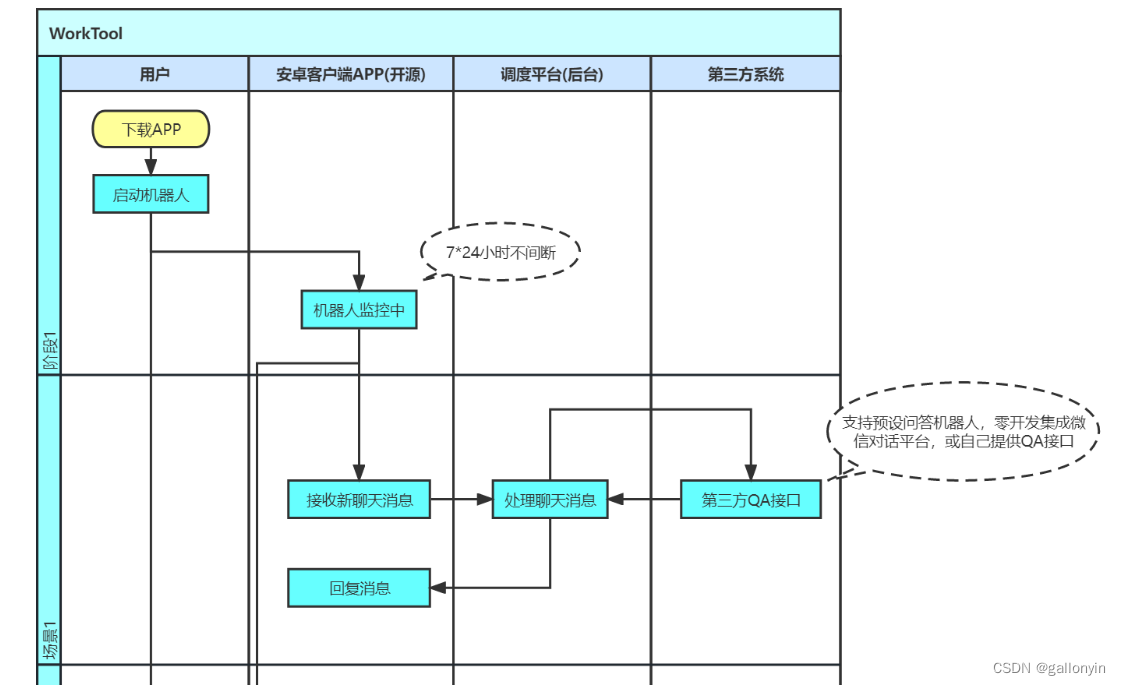
-
创建 Chat 账户并获取 apiKey
第一步完成后,你应该已经有一个自动执行的企微机器人了,然后需要获取 apiKey,获取方法还需要自行搜索教程、注册或采购。 -
WorkTool 机器人绑定 apiKey
绑定方法:https://worktool.apifox.cn/api-68569089?nav=2- 点击调试
- 点击Params 修改robotId后面的参数值为你的机器人id
- 点击Body 修改apiKey后面的参数值为你自行注册的Chat apiKey
- 点击发送即可完成绑定
这时再向你的机器人提问,机器人就会使用 Chat 的问答能力进行回答啦。
实现原理
项目采用 Java 语言编写,核心方法本质上还是请求官方接口,并暂时保存用户会话上下文来达到多轮问答的效果。
核心工具类如下:
import java.util.*;
import com.huggingface.chatbot.*;
import com.database.*;
import com.nlp.*;
import com.speech.*;public class ChatbotClient {private static final int MAX_HISTORY_SIZE = 10;private DialogManager dialogManager;private DatabaseManager databaseManager;private NLPProcessor nlpProcessor;private SpeechProcessor speechProcessor;public ChatbotClient() {dialogManager = new DialogManager();databaseManager = new DatabaseManager();nlpProcessor = new NLPProcessor();speechProcessor = new SpeechProcessor();}public void startChat() {Scanner scanner = new Scanner(System.in);while (true) {String input = scanner.nextLine();String userMessage = speechProcessor.speechToText(input);String chatbotResponse = getResponse(userMessage);System.out.println(\"Chatbot: \" + chatbotResponse);String chatbotSpeech = speechProcessor.textToSpeech(chatbotResponse);System.out.println(\"(Speech) Chatbot: \" + chatbotSpeech);}}private String getResponse(String userMessage) {String chatbotResponse = dialogManager.getPreviousResponse();if (chatbotResponse != null && !chatbotResponse.isEmpty()) {System.out.println(\"User: \" + userMessage);String nlpResult = nlpProcessor.process(userMessage);String databaseResult = databaseManager.query(nlpResult);chatbotResponse = chatbotResponse + \" \" + databaseResult;} else {chatbotResponse = Chat.getResponse(userMessage);}dialogManager.addResponse(chatbotResponse);return chatbotResponse;}private class DialogManager {private LinkedList<String> history = new LinkedList<>();public void addResponse(String response) {history.add(response);if (history.size() > MAX_HISTORY_SIZE) {history.poll();}}public String getPreviousResponse() {if (history.isEmpty()) {return null;}return history.getLast();}}public static void main(String[] args) {ChatbotClient chatbotClient = new ChatbotClient();chatbotClient.startChat();}
}
总结
至此,你应该已经完成了企微机器人智能问答对接,一个智能企微机器人就实现了,后续我会继续进行AI能力的扩展,如多模态等。喜欢本文可以关注我~有问题可以留言或私信我。