深圳模板网站建设公微信群推广
Meta分析是针对某一科研问题,根据明确的搜索策略、选择筛选文献标准、采用严格的评价方法,对来源不同的研究成果进行收集、合并及定量统计分析的方法,现已广泛应用于农林生态,资源环境等方面,成为Science、Nature论文的重要分析方法。以ChatGPT为代表AI大语言模型带来了新一波人工智能浪潮,可以快速提升Meta分析的理解和应用效率。R语言拥有完整有效的数据处理、统计分析与保存机制,可以对数据直接进行分析和显示,命令格式简单、结果可读性强,包含众多针对Meta分析软件包,是进行Meta整合分析及评价的有效平台。通过AI大模型全程助力Meta分析,从文献计量分析研究热点变化,寻找科学问题、R-Meta多手段全流程分析与Meta高级绘图、多层次分层嵌套模型构建与Meta回归诊断、贝叶斯网络、MCMC参数优化及不确定性分析、Meta数据缺失值处理的六种方法与结果可靠性分析、Meta加权机器学习与非线性Meta分析等方面讲解,每个专题,每一部分结合多个典型案例实践,深受众多学员好评。
专题一、AI+Meta分析的选题与检索、寻找科学问题
1、AI大模型助力Meta分析的选题与文献检索
1)什么是Meta分析
2)Meta分析的选题策略
3)精确检索策略,如何检索全、检索准
4)文献的管理与清洗,如何制定文献纳入排除标准
5)文献数据获取技巧,研究课题探索及科学问题的提出
6)文献计量分析CiteSpace、VOSViewer、R bibliometrix及研究热点分析
7)AI大模型的发展与底层逻辑
8)AI大模型的高级提问框架
9)AI大模型助力寻找科学问题
专题二、AI助力Meta分析与R语言数据清洗及统计方法
2、Meta分析的常用软件/R语言基础及统计学基础
1)R语言做Meta分析的优势及其《Nature》、《Science》经典案例应用
2)AI大模型助力,实现R语言基本操作与数据清洗
3)统计学基础和常用统计量计算(sd\se\CI)、三大检验(T检验、卡方检验和F检验)
4)传统统计学与Meta分析的异同
5)R语言Meta分析常用包及相关插件讲解
从自编程计算到调用Meta包(meta、metafor、dmetar、esc、metasens、metamisc、meta4diag、gemtc、robvis、netmeta、brms等),全程分析如何进行meta计算、meta诊断、贝叶斯meta、网状meta、亚组分析、meta回归及作图。
专题三、AI+R语言Meta效应值计算与图形绘制
3、AI大模型助力R语言Meta效应值计算
1)R语言Meta分析的流程
2)各类meta效应值计算、自编程序和调用函数的对比连续资料的lnRR、MD与SMD分类资料的RR和OR
3)R语言meta包和metafor包的使用
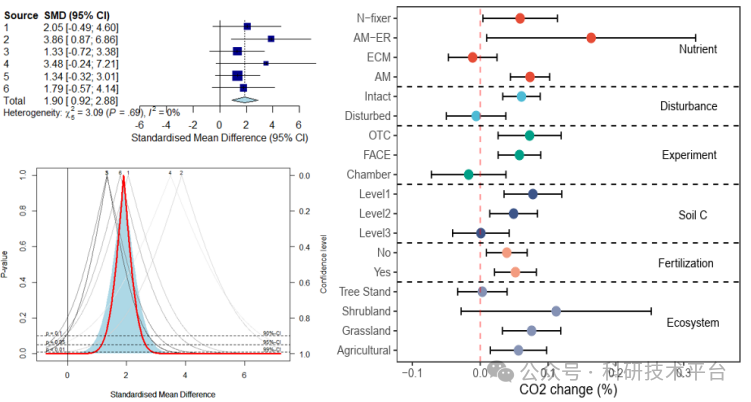
4)如何用R基础包和ggplot2绘制漂亮的森林图
专题四、如何利用AI+R语言Meta分析与回归分析、混合模型构建
4、AI大模型助力R语言Meta分析与混合效应模型(分层模型)构建
1)Meta分析的权重计算
2)Meta分析中的固定效应、随机效应
3)如何对Meta模型进行统计检验和构建嵌套模型、分层模型(混合效应)
4)Meta回归和普通回归、混合效应模型的对比及结果分析
5)使用Rbase和ggplot2绘制Meta回归图
专题五、AI+R语言Meta诊断分析进阶
5、AI大模型助力R语言Meta诊断进阶
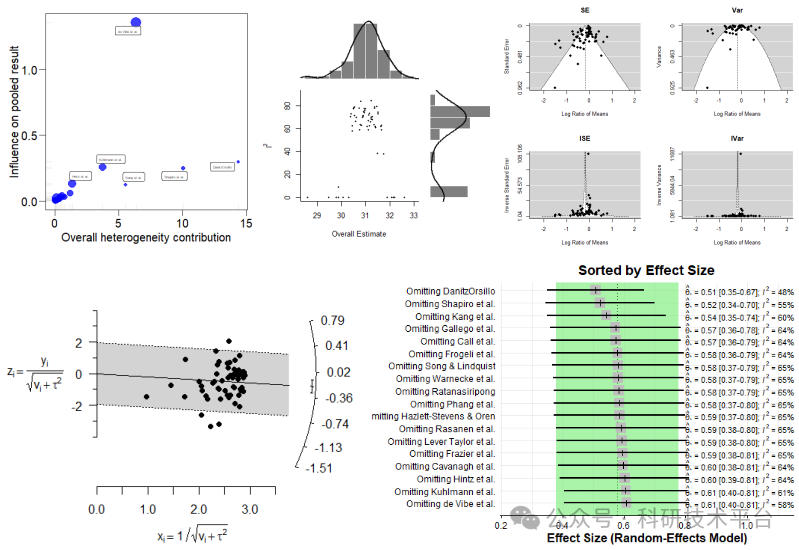
1)Meta诊断分析(t2、I2、H2、R2、Q、QE、QM等统计量)
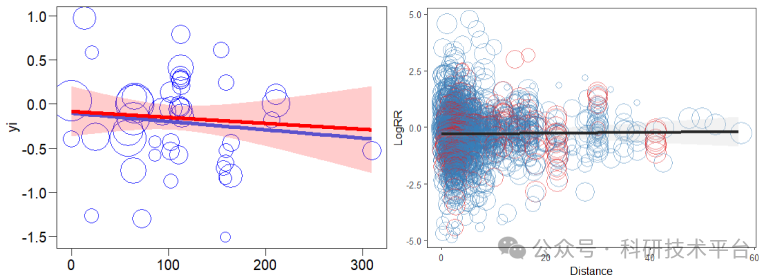
2)异质性检验及发表偏移、漏斗图、雷达图、发表偏倚统计检验
3)敏感性分析、增一法、留一法、增一法、Gosh图
4)风险分析、失安全系数计算
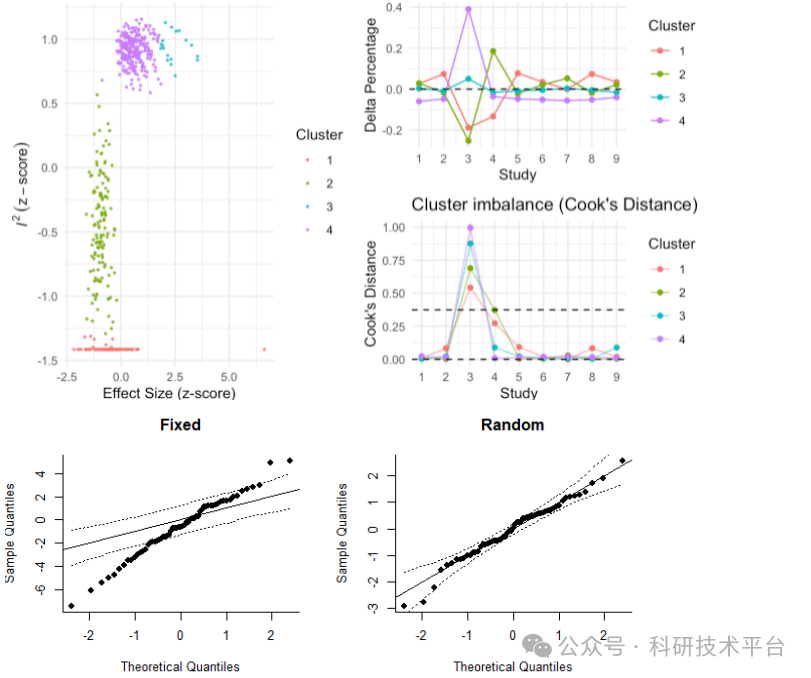
5)Meta模型比较和模型的可靠性评价
6)Bootstrap重采样方法评估模型的不确定性
7)如何使用多种方法对文献中的SD、样本量等缺失值的处理
8)AI大模型复现Science最新Meta分析案例
专题六、AI+R语言Meta分析的不确定性及贝叶斯Meta分析
6、AI大模型助力R语言Meta分析的不确定性
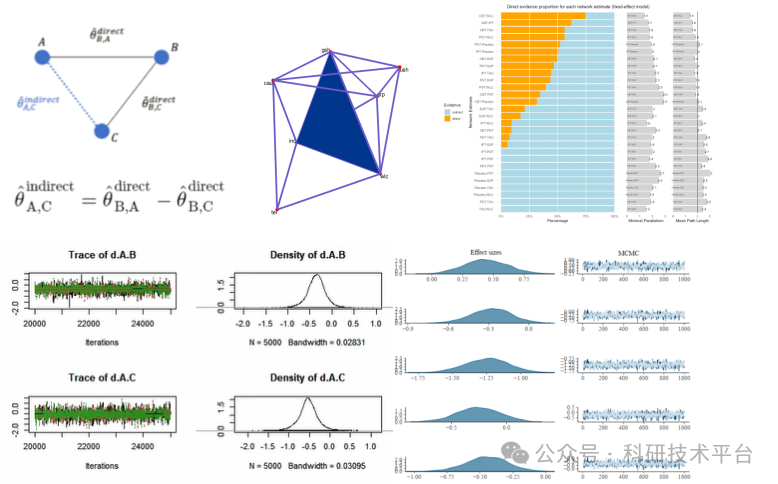
1)网状Meta分析
2)贝叶斯理论和蒙特拉罗马尔可夫链MCMC
3)如何使用MCMC优化普通回归模型和Meta模型参数
4)R语言贝叶斯工具Stan、JAGS和brms
5)贝叶斯Meta分析及不确定性分析
专题七、AI+Meta机器学习方法应用
7、AI大模型助力机器学习在Meta分析中的应用
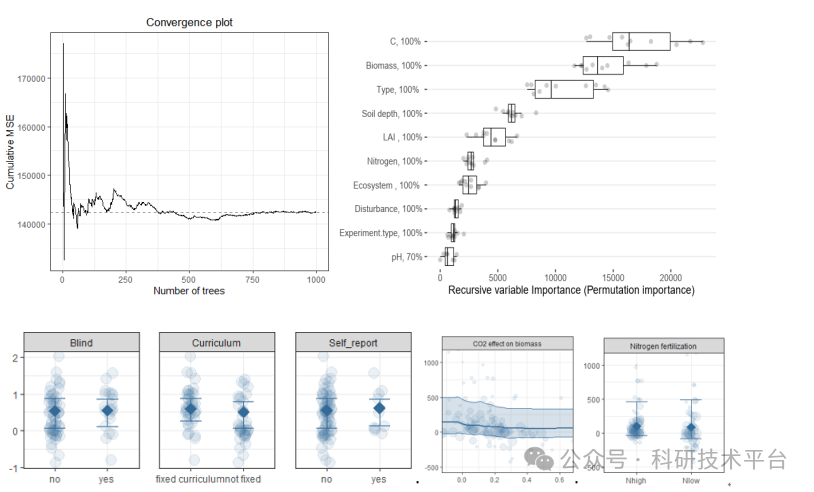
1)机器学习基础以及Meta机器学习的优势
2)Meta加权随机森林(MetaForest)的使用
3)使用Meta机器学习和传统机器学习对文献中的大数据训练与测试
4)如何判断Meta机器学习使用随机效应还是固定效应以及超参数的优化
5)使用Meta机器学习进行驱动因子分析、偏独立分析PDP
专题八、讨论与答疑
1 练习
2 讨论与答疑