建设厅公积金中心网站优化网站建设
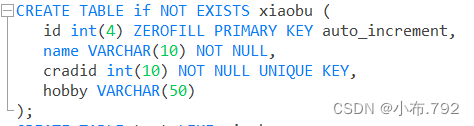
if not exists xiaobu:xiaobu这个表不存在,才会创建
zerofill:自动填充位置 1 0001
primary key:当前表的主键,主键只能有一个,而且唯一,而且不能为空
auto_increment:表示该字段可以自增长,默认从1开始,每条纪录会自动自增1
unique key:唯一性约束,跟主键不同,可以为空
CREATE TABLE test LIKE xiaobu;
复制,通过like这个语句直接复制xiaobu的表结构,只是复制表结构,不能复制表里面的数据
INSERT INTO test SELECT * FROM xiaobu;
把表名表里面的数据,复制到test,两个表数据机构一致
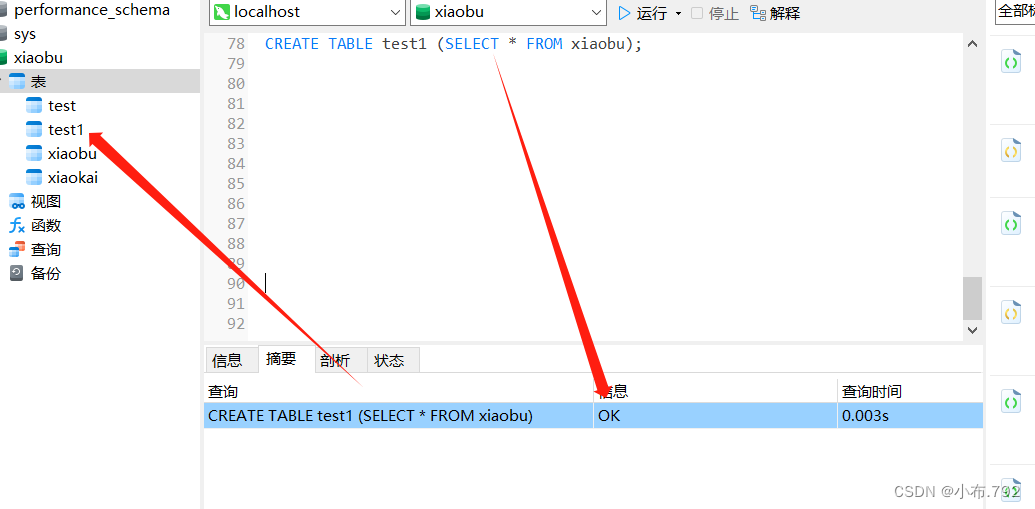
create table test1 (select * from xiaobu);
创建一张表,test1,数据从xiaobu来,表结构也是xiaobu;
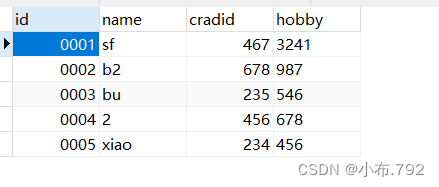
删除表内的所有所有数据
delete truncate drop
delete from 表名;
delete 删除是一行一行删除,如果表中有自增长列,清空所有纪录之后,再次添加内容,会从原来的纪录之后继续自增写入
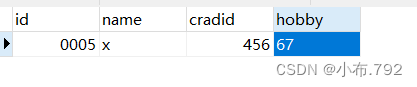
truncate table 表名;
清空表的数据,而且会把表结构重新建立,速度上比delete快,**推荐**

drop table 表名;
删除表不推荐
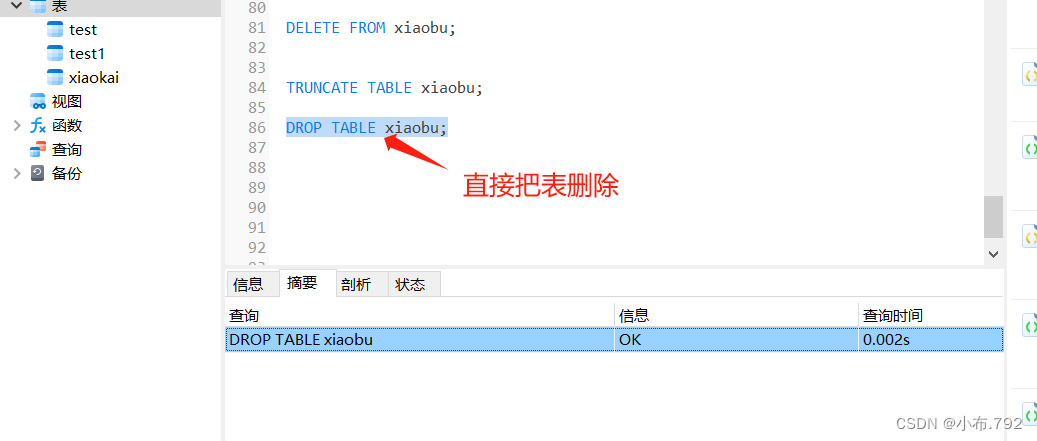
创建临时表
一用于调试,而且临时表示创建之后在表目录当中是不显示的
连接退出之后,临时表会被销毁,而且临时表无法创建外键
create temporary table 表名 (id int(4) primary key,name char(10),sex char(2),);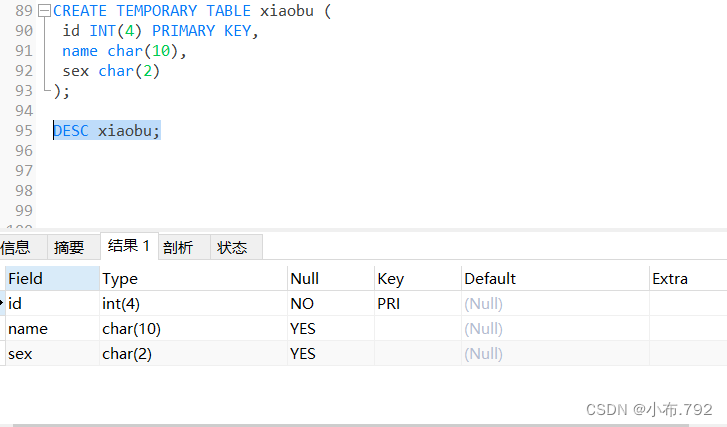
mysql 的约束方式
6种常用的约束
1、主键约束,用于唯一标识表中的每一行,主键列的值必须是唯一而且不能为空,一个表只能有一个主键
2、外键约束,用于建立表于表之间的关系,一般是和另一张的表的主键关键,保证数据引用的完整性,一个表可以有多个外键
3、非空约束,not null 必须要有一个值
4、唯一性约束,unique ,确保列中的所有值都是唯一的,类似于主键,但是可以为空,而且一个表可以有多个唯一约束
5、默认值约束。default,在插入表数据时,如果没有定义值,会提供一个默认值
6、自动约束,每行自动生成一个唯一标识,通常和主键在一起使用
创建主从表
主表
card_id int(18)设为主键
stu_name varchar(12) 非空
stu_email varchar(255) 可以为空,但不能重复
从表
stud_id int(11) 自增 主键
address varchar(50) 设置默认值
card_id 从表的外键连接主表的主键

主表和从表:
插入数据:先插入主表,再插入从表
删除数据:先删除主表,再删除从表
alter table class drop foreign key class_ibfk_1;
desc class; 查看表结构
mul:表示这个一个索引
alter table class drop index card_id;
alter table class drop primary key;
there can be only one autocolumn and it must be defined as a key
这是一个自增约束的主键,要先改变他的数据类,解除自增约束,之后主键才可以删除
alter table class modify stud_id int(12);
alter table class drop primary key;习题
两张表
主表 company(公司)
从表 depart(部门)
company:
1、work_id 非空,主键int(4)不满四位要补齐
2、name 非空 char(5)
3、sex 非空 char(2)
depart:
1、de_id 非空 主键 int(6)不满六位要补齐
2、work_id 要和主表的work_id关联为外键
3、address 为空,但是有一个默认值
4、phone 不能为空而且不能相同
主
CREATE TABLE company (work_id int(4) zerofill primary key,name char(5) not null,sex char(2) not null
);
从
CREATE TABLE depart (de_id int(6) zerofill PRIMARY KEY,address VARCHAR(50) DEFAULT '地址不详',phone int(11) not null UNIQUE,work_id int(4) not NULL,FOREIGN KEY(work_id) REFERENCES company(work_id)
);
如果没有添加主键可以用
alter table depart add FOREIGN KEY (work_id) REFERENCES company(work_id);
增加主键
先删除主键
ALTER table depart drop PRIMARY key;
添加主键
alter table depart add PRIMARY key;两张表:
school
1、de_id int(4) 不满四位要补齐,而且自增长 主键
2、name varchar(15) not null
3、email varchar(45) 可以为空,而且有默认值 xiaobu@126.com
从
cloud_ky32
id 自增长 主键 int
class_name 不能为空
address 可以为空 ,默认是'地址不详'
phone int(11) 不能为空,而且不能重复
de_id要和主键关联
3、要求删除外键关联,删除从表的主键,重新定义主键为phone
CREATE table shcool (de_id int(4) ZEROFILL auto_increment PRIMARY KEY,name VARCHAR(15) not null,email VARCHAR(45) UNIQUE DEFAULT 'bdqnkgc@126.com'
);CREATE TABLE cloud_xiaobu (id int(4) auto_increment PRIMARY KEY,class_name VARCHAR(12) not null,address VARCHAR(255) DEFAULT '地址不详',phone int(11) NOT NULL UNIQUE,de_id int(4) ZEROFILL NOT NULL,FOREIGN KEY(de_id) REFERENCES shcool(de_id)
);
DESC cloud_xiaobu;ALTER TABLE cloud_xiaobu drop FOREIGN key cloud_xiaobu_ibfk_1;ALTER TABLE cloud_xiaobu MODIFY id int(5);ALTER TABLE cloud_xiaobu drop PRIMARY KEY;ALTER TABLE cloud_xiaobu ADD PRIMARY KEY(phone);1、两张表:school
de_id int(4) 不满四位要补齐,而且自增长 主键
name VARCHAR(15) not NULL
email varchar(45) 不可以为空,而且不能重复
money int 不可为空,不能重复CREATE TABLE school (de_id int(4) ZEROFILL auto_increment PRIMARY KEY,name VARCHAR(15) NOT NULL,email VARCHAR(45) NOT NULL UNIQUE,money INT(255) NOT NULL UNIQUE
);
DESC school;2、cloud_ky32
id 自增长 主键 int
class_name 不能为空。
de_id 外键,外键和主表的主键关联。
adress 可以为空,默认是'地址不详'
phone int 不能为空,而且不能重复。CREATE TABLE cloud_xiaobu (id int(4) auto_increment PRIMARY KEY,class_name VARCHAR(12) NOT NULL,address VARCHAR(255) DEFAULT '地址不详',phone INT(11) NOT NULL UNIQUE,de_id INT(4) ZEROFILL,FOREIGN KEY(de_id) REFERENCES school(de_id)
);3、分别在两张表中插入10条数据 主表
insert into school values (1,'xiaobu1','1','1');
insert into school values (2,'xiaobu2','2','2');
insert into school values (3,'xiaobu3','3','3');
insert into school values (4,'xiaobu4','4','4');
insert into school values (5,'xiaobu5','5','5');
insert into school values (6,'xiaobu6','6','6');
insert into school values (7,'xiaobu7','7','7');
insert into school values (8,'xiaobu8','8','8');
insert into school values (9,'xiaobu9','9','9');
insert into school values (10,'xiaobu10','10','10');从表
insert into cloud_xiaobu values (1,'xiaobu1','1','1',1);
insert into cloud_xiaobu values (2,'xiaobu2','2','2',2);
insert into cloud_xiaobu values (3,'xiaobu3','3','3',3);
insert into cloud_xiaobu values (4,'xiaobu4','4','4',4);
insert into cloud_xiaobu values (5,'xiaobu5','5','5',5);
insert into cloud_xiaobu values (6,'xiaobu6','6','6',6);
insert into cloud_xiaobu values (7,'xiaobu7','7','7',7);
insert into cloud_xiaobu values (8,'xiaobu8','8','8',8);
insert into cloud_xiaobu values (9,'xiaobu9','9','9',9);
insert into cloud_xiaobu values (10,'xiaobu10','10','10',10);4、 在第二张表中增加一列,hobby。alter table cloud_xiaobu add hobby varchar(12);5、修改主表的name类型为char(15)alter table school modify column name char(15);
DESC school;6、更改cloud_xiaobu的表名,为xiaobualter table cloud_xiaobu rename xiaobu;7、修改 hobby的列名,改为hobalter table xiaobu change hobby hob varchar(12);8、通过命令行,把主表的第一行的money的初始值1000,变成900update school set money='900' where de_id = 1;