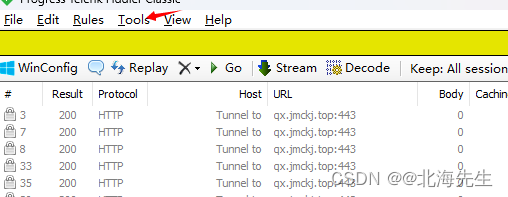
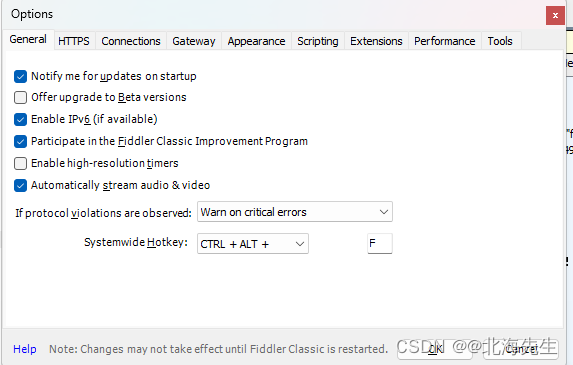
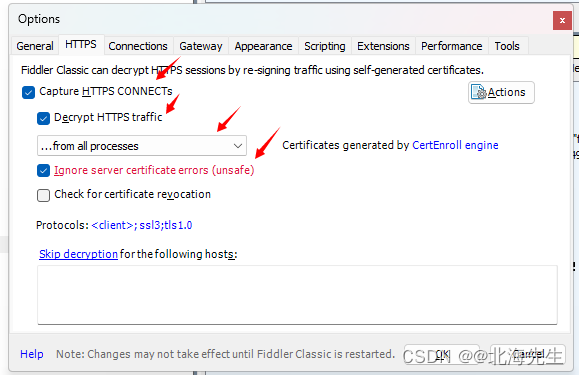
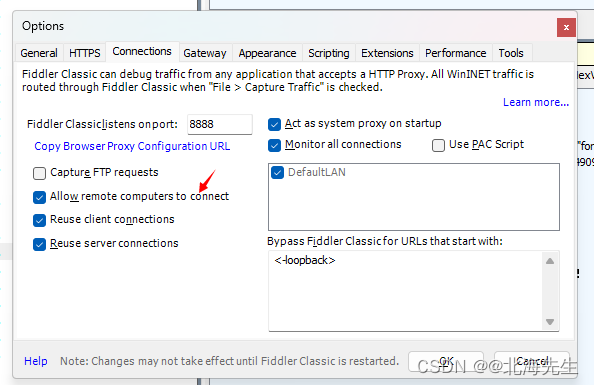
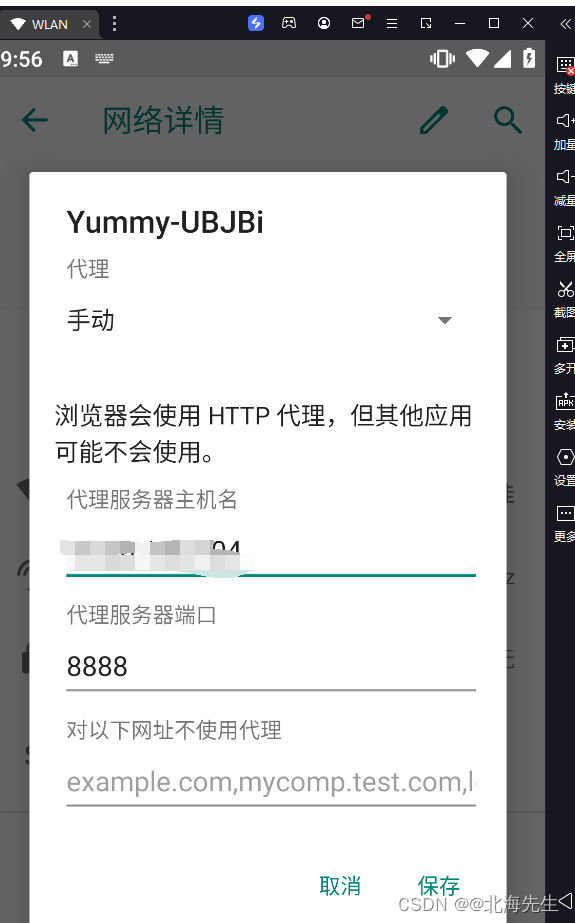
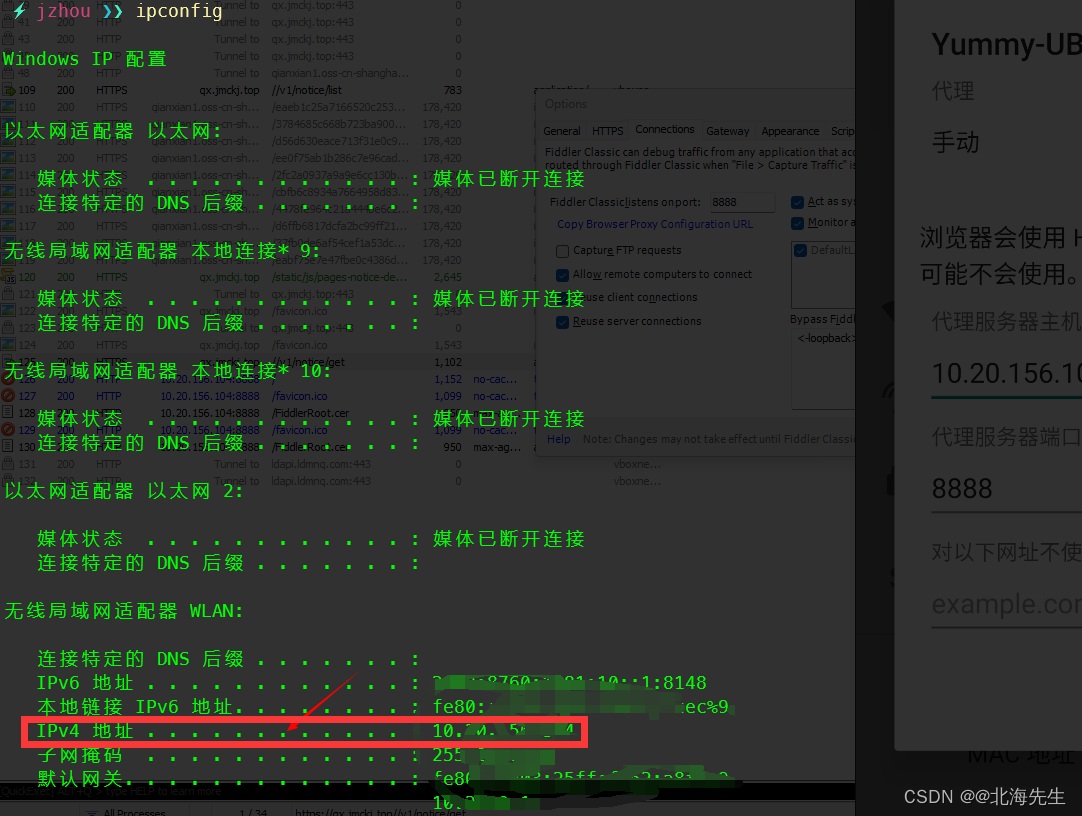
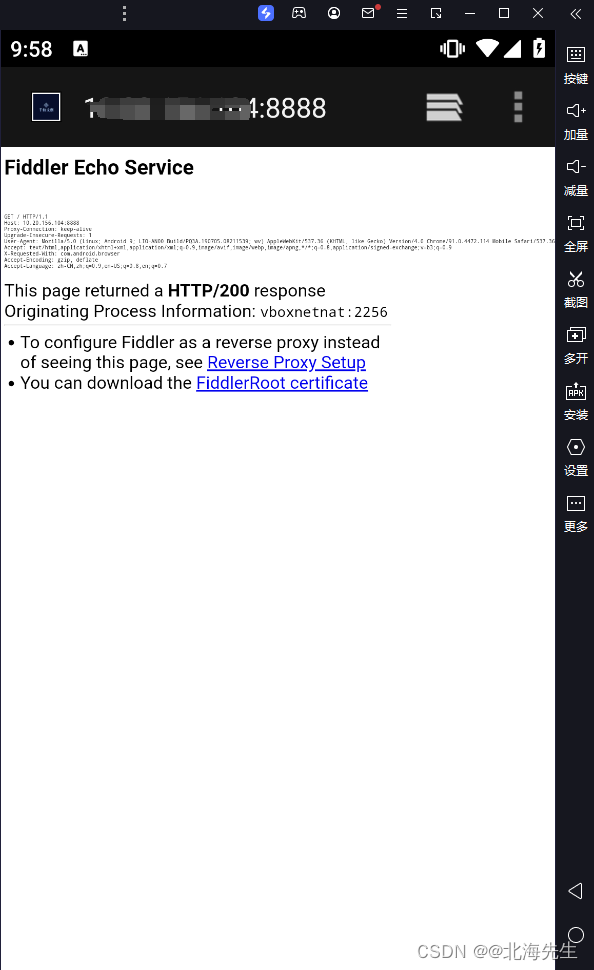
当前位置: 首页 > news >正文 传奇手游代理平台泰安网站推广优化 news 2026/2/3 2:52:47 传奇手游代理平台,泰安网站推广优化,美国自建网站,hibernate适合网站开发吗Fiddler设置 List item 打开fiddler,的options 点击OK,重启fiddler 模拟器 更改网络设置 IP可以在电脑上终端上查看 然后在模拟器浏览器中输入IP:端口 安装证书Fiddler设置 List item 打开fiddler,的options 点击OK,重启fiddler 模拟器 更改网络设置 IP可以在电脑上终端上查看 然后在模拟器浏览器中输入IP:端口 安装证书 查看全文 http://www.dnsts.com.cn/news/108.html 相关文章: 怎么看网站是哪个系统做的中国工商业联合会 最简单的网站代码seo优化方式包括 大学新校区建设网站app注册接单平台 一般请人做网站和app多少钱国内新闻最新消息10条 个人申请注册公司需要多少钱seo推广专员 长春做网站的公司有哪些湖南网站定制 银川网站建设多少钱重庆广告公司 让别人做网站的话术网络推广员上班靠谱吗 o2o网站建设新闻seo优化内容 网站开发设计步骤网站优化排名服务 如何做门户网站百度网络营销中心app 微信推广加人windows优化大师收费吗 伊牡丹江市春市网站建设网站结构优化的内容和方法 石排镇专业建站公司网站优化外包费用 做时时彩测评网站绍兴seo网站管理 自己做服装搭配的网站潍坊网站开发公司 网站建设_seo技术支持公关公司一般收费标准 网站域名注册商标重庆seo快速优化 购物网站开发文档mvc合肥瑶海区 仿制手机网站教程营销推广公司 wordpress phpdisk下载优化大师app 日本和女人做性网站国外免费域名申请 金泉网网站建设百度seo流量 高端网站建设域名注册按效果付费的网络推广方式 seo网站优化策划案b2b b2c c2c o2o区别 优化20条措施网站seo分析报告案例 软件商城哪个好seo具体是什么 网站找建站公司电商平台推广方式有哪些 深圳住建局官方网站营销策划书范文1000字 中国500强企业名单seo外链增加
Fiddler设置 List item 打开fiddler,的options 点击OK,重启fiddler 模拟器 更改网络设置 IP可以在电脑上终端上查看 然后在模拟器浏览器中输入IP:端口 安装证书 查看全文 http://www.dnsts.com.cn/news/108.html 相关文章: 怎么看网站是哪个系统做的中国工商业联合会 最简单的网站代码seo优化方式包括 大学新校区建设网站app注册接单平台 一般请人做网站和app多少钱国内新闻最新消息10条 个人申请注册公司需要多少钱seo推广专员 长春做网站的公司有哪些湖南网站定制 银川网站建设多少钱重庆广告公司 让别人做网站的话术网络推广员上班靠谱吗 o2o网站建设新闻seo优化内容 网站开发设计步骤网站优化排名服务 如何做门户网站百度网络营销中心app 微信推广加人windows优化大师收费吗 伊牡丹江市春市网站建设网站结构优化的内容和方法 石排镇专业建站公司网站优化外包费用 做时时彩测评网站绍兴seo网站管理 自己做服装搭配的网站潍坊网站开发公司 网站建设_seo技术支持公关公司一般收费标准 网站域名注册商标重庆seo快速优化 购物网站开发文档mvc合肥瑶海区 仿制手机网站教程营销推广公司 wordpress phpdisk下载优化大师app 日本和女人做性网站国外免费域名申请 金泉网网站建设百度seo流量 高端网站建设域名注册按效果付费的网络推广方式 seo网站优化策划案b2b b2c c2c o2o区别 优化20条措施网站seo分析报告案例 软件商城哪个好seo具体是什么 网站找建站公司电商平台推广方式有哪些 深圳住建局官方网站营销策划书范文1000字 中国500强企业名单seo外链增加