云南网站建设电话百度app首页
作者:Daniel@footprint.network
数据来源:NFT Monthly Report
三月份的 NFT 市场上出现了两个有趣的趋势。一方面,Polygon 链尽管在二月份有所突破,达到了 NFT 总交易量的 4.2%,但于三月再次跌至 1% 以下,再次在公链的 NFT 数据表现中位列第三。另一方面,Blur 的增速依然没有放缓,反而扩大了其领先优势,拥有 NFT 市场上总交易量的 66%,使其成为一个颠覆性项目。在颠覆性这个形容词被滥用的当下,Blur 足以让人眼前一亮。
ETH 的币价和整个市场于月初急剧下跌,而后强劲反弹,趋势与股市关联度高。
虽然 NFT 市场的价格支撑和用户数量数据尚且乐观,但投资环境依然相对平淡。最大的一轮——Animoca Brands 和 Hex Trust 的合资企业完成 750 万美元的融资。此外,本月 NFT 市场上融资轮次都是种子或前种子轮。
Key Findings主要研究结果
加密市场概述
-
ETH 于 3 月 11 日跌至 1,429 美元,然后在月底跃升至近七个月以来的最高点
-
ETH 的价格走势与标准普尔指数走向一致,具体表现为月初疲软,随后强势反弹
NFT 市场概览
-
3 月 18 日,NFT的市值达到 3 月最高的 204 亿,但仍低于 2 月份的高点
-
NFT 交易量在 2 月的强劲表现后明显下降
-
3 月 NFT 市场交易量为 15 亿美元
-
周 NFT 用户数量相比 2 月份下降了 25-35%
NFT 公链以及交易市场的数据情况
-
NFT 交易量最大的公链是以太链,达到 14 亿美元
-
Polygon 月交易量从上月的 8420 万美元降低到 1520 万美元
-
OpenSea 是最赚钱的交易市场,服务费收益高达 530 万美元
-
Blur 市场占有率持续扩大,本月交易量占市场的 65% 以上
NFT 投融资情况概览
-
NFT 领域的融资轮次数量从 10 次下降到 8 次,总轮次下降了 38%
-
Gryfyn 于本月完成了750万美元融资,为 NFT 市场上数额最大。Gryfyn 是 Animoca Brands 和 Hex Trust 的合资企业,旨在提供托管加密钱包。
加密市场概述
ETH 在 3 月 11 日跌至 1,429 美元,但随后反弹 30%
加密货币表现强劲,7个月的高涨显示出积极的趋势。虽然价格走势与标准普尔指数月初疲软,随后强势反弹有一定的关联性,但数据之间并不像牛市期间那样紧密相连。

ETH 价格走势
NFT 市场概览
3 月 18 日,NFT 的市值达到了 204 亿美元
NFT 市值为 204 美元(不包括 Footprint Analytics 检测到的刷单行为)比其 2 月份的最高值 212 亿美元略低。然而,NFT 交易量明显下降,为 15 亿美元。
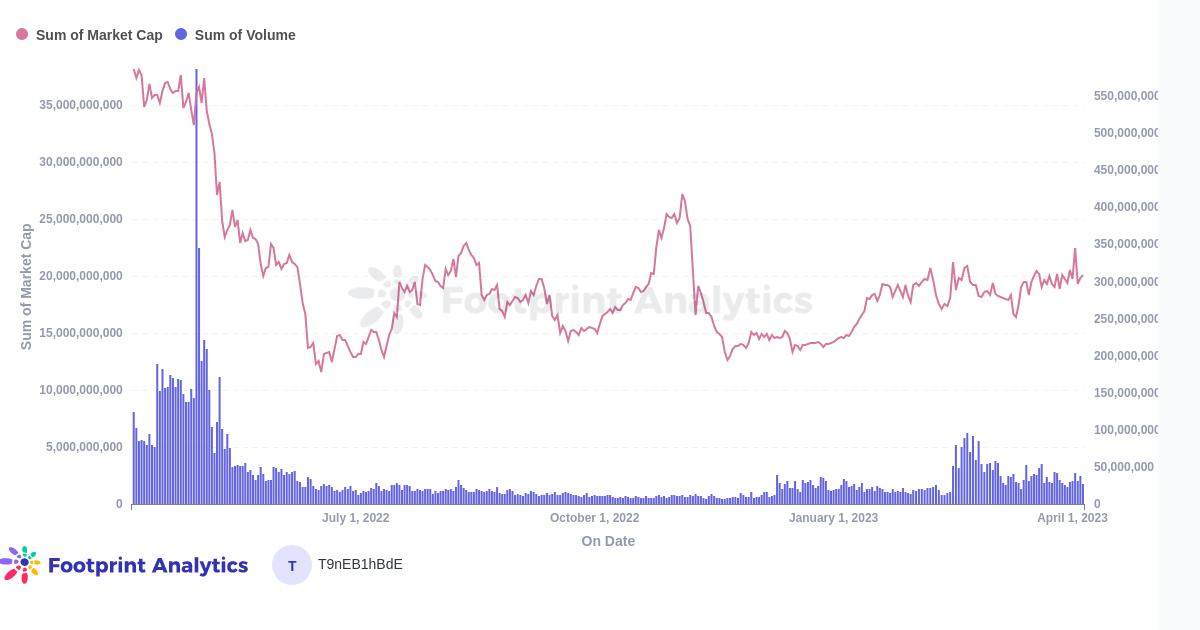
NFT 市值 & 交易量数据
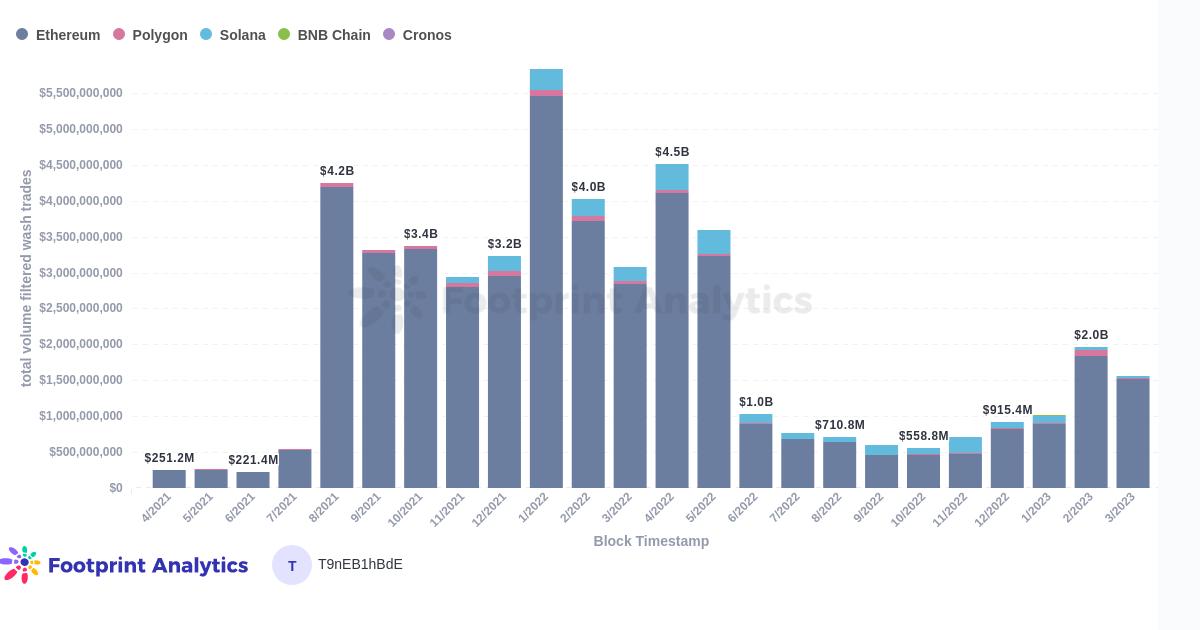
NFT 各链交易量(已排除刷单数据)
NFT 用户数量相比于上月明显下降
由于这个图表和指标是按周分布,因此可以根据一般的价格区间得出一个相比 2 月份下降了 25-35% 的大致数字。

周度用户数
NFT 公链以及交易市场的数据情况
以太链依然是 NFT 交易量最大的公链
以太链 3 月份的交易量为 14 亿美元,而其他公链交易量的市场占有率出现了较大幅度收缩。Polygon 链表现尤其明显,交易量从 8420 万下降到 1520 万。
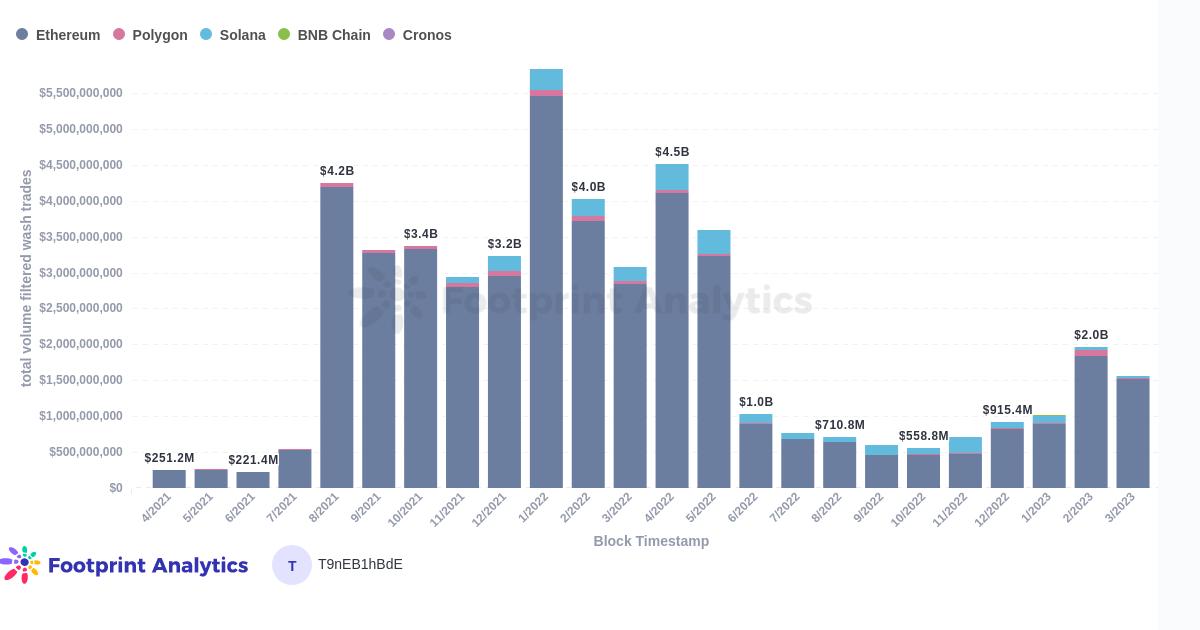
NFT 各链交易量(已排除刷单数据)
OpenSea 三月的服务费收益高达 530 万美元
收益仅次于 OpenSea 的交易市场是 LooksRare, 交易市场依然获利不菲。
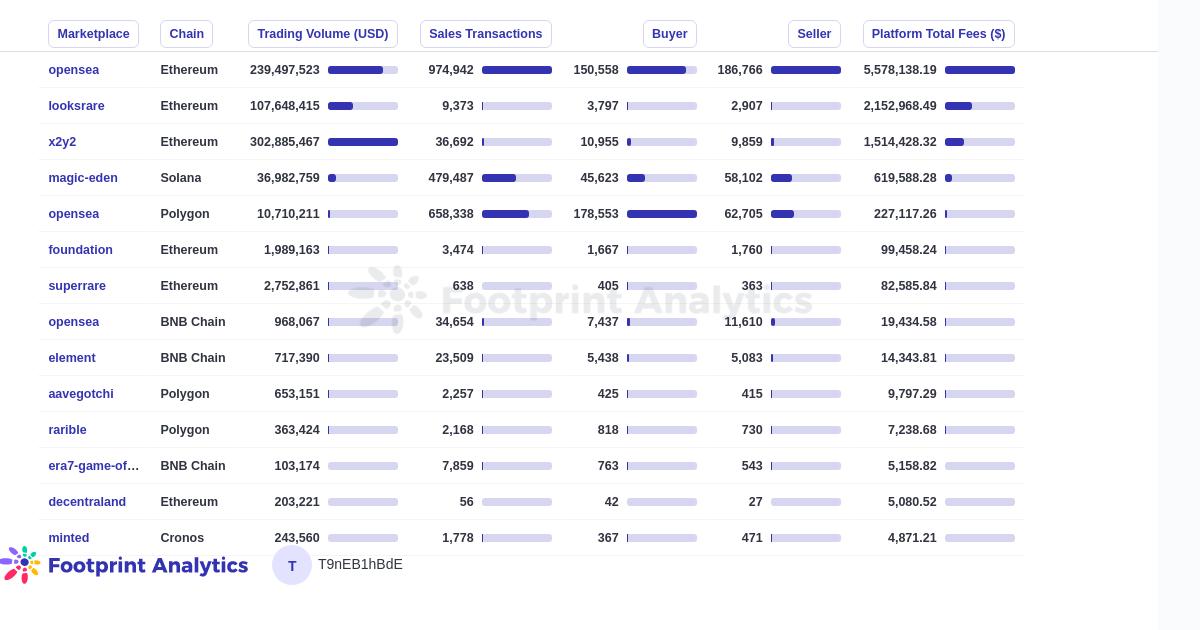
三月 NFT 交易市场相关数据
Blur 本月交易量占整个市场的 66%
Blur 专注于成为高性能 NFT 交易聚合器市场,因此其市场占有率持续扩大。熊市中,市场选择了与走在最前列的一方进行交易并不出乎意料。在市场复苏时,Blur 是否能保持其主导地位并吸引更多新入场用户,还有待观察。

NFT 各交易市场交易量(已排除刷单数据)
NFT 投融资情况概览
每月维度上来看,整个行业的融资轮次数下降了 38%,NFT 领域下降了 20%。
NFT 领域的融资轮次数量共八次,数额都相对较小且都为种子轮或者前种子轮。Gryfyn 于本月完成了750万美元融资,为 NFT 市场上数额最大。Gryfyn 是 Animoca Brands 和 Hex Trust 的合资企业,旨在提供托管加密钱包。
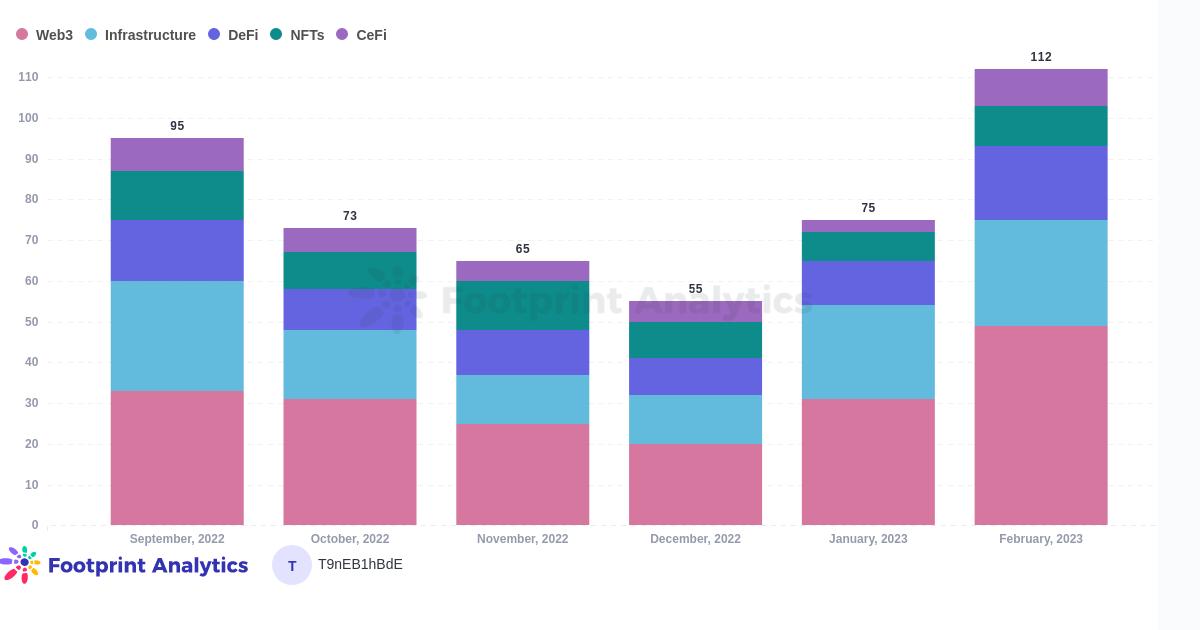
各细分领域投资情况
本文来自 Footprint Analytics 社区贡献。
Footprint Community 是一个全球化的互助式数据社区,成员利用可视化的数据,共同创造有传播力的见解。在Footprint社区里,你可以得到帮助,建立链接,交流关于Web 3,元宇宙,GameFi 与DeFi 等区块链相关学习与研究。许多活跃的、多样化的、高参与度的成员通过社区互相激励和支持,一个世界性的用户群被建立起来,以贡献数据、分享见解和推动社区的发展。
Footprint Website: https://www.footprint.network
Discord: https://discord.gg/3HYaR6USM7
Twitter: https://twitter.com/Footprint_Data