技术号的网站建设重庆网站优化
2023世界超高清视频产业发展大会博冠8K明星展品介绍:
一、博冠8K全画幅摄像机B1
这是一款面向广电应用的机型,可适配外场ENG制作轻量化需求,应用于8K单边机位、新闻、专题的拍摄工作,也可应用于体育转播、文艺节目等特殊机位及各类新媒体节目拍摄工作,大幅降低8K超高清制作成本,凸显使用本土化设备制作成本的高性价比。B1创新性融合广播级接口,将电影级的高画质用于广电现场制播,兼具广电级的超强稳定性,重新定义广播世界。

主要功能:
B1作为国内首款具备4路12G-SDI无压缩基带流输出接口的8K全画幅摄像机。专业级12G-SDI无压缩基带流输出接口,让8K影像数据传输畅通无碍,并支持SDI信号输出HLG曲线,适应广电应用需求,可直接供广播电视台、影视制作机构及互联网公司直播、录制使用。
8K分辨率模式下高达60fps,8K全画幅,300/2400 双原生 ISO,12bit色深,宽容度高达14档。用户可以直接从8K素材中截取3300万像素的静止图像。HLG/HDR10,大幅提升了高光亮度与阴影暗部的渲染细节能力。
对于目前广电制播存在多种分辨率规格形式,B1提供了8K无压缩、4K超采到2K高清输出等选项,同时满足日益增长的4K/8K HDR制作市场需求。而作为一款一机多用的8K机器,如果需要使用B1录制6K/5K/4K 60P,此时所使用的影像传感器面积可以达到Super 35mm规格,不会有质量损失。对于慢动作拍摄需求,B1还提供了4K最高120帧、2K最高240帧的拍摄选项,有效满足体育赛事节目录制需求。
紧凑的B1拥有原生电影级 PL 镜头卡口,耐用的法兰结构设计可以安全承受重量级的长焦镜头,让画面成像效果更加优良,暗角更少,为精益制作提供可靠支持。可通过转接环可兼容B4卡口等镜头群,满足不同场景的拍摄需求。配置Genlock、TC In/Out等众多工业标准接口,支持新标准的 CFexpress存储卡。
对于广电领域而言,稳定性是刚需。长时间8K视频录制难免担心机身过热问题,B1采用创新主动式风冷散热系统,优化了散热风道结构,紧凑式机身设计增大机身进风量,降低热量在内部堆积,从而保证在8K最高规格下依旧可以长时间录制。同时,紧凑的机身内还设置了智能无级风扇调速系统,在确保散热性能的前提下有效降低风扇噪音。
小于3Kg的机身重量,融入20多年光学设计能力,紧凑机身却拥有无限张力,零层级菜单系统设计,标准12针镜头控制接口,兼容写入速度较快的B型CFexpress存储卡或外置SSD,V口电池设计帮助用户获得长续航,并且兼容多种网络协议,极速推拉流打造广播节目现场直播间。
全画幅,8K 60P,4路12G-SDI,三大特点令其成为国产8K高帧率机型中的前沿选手。毫无疑问,B1的诞生将加速电视与多媒体效果电影化进步,与电视摄像机传感器相比,我们正在进入一个基于大型传感器和带有PL卡口的高分辨率摄像机的广播世界。
主要应用:
2022年北京冬奥会开/闭幕式拍摄;2022年央视网超级月亮户外机位直播拍摄;2022年珠海航展8K拍摄;2023年央视春晚拍摄;2023年央视元宵节晚会拍摄。
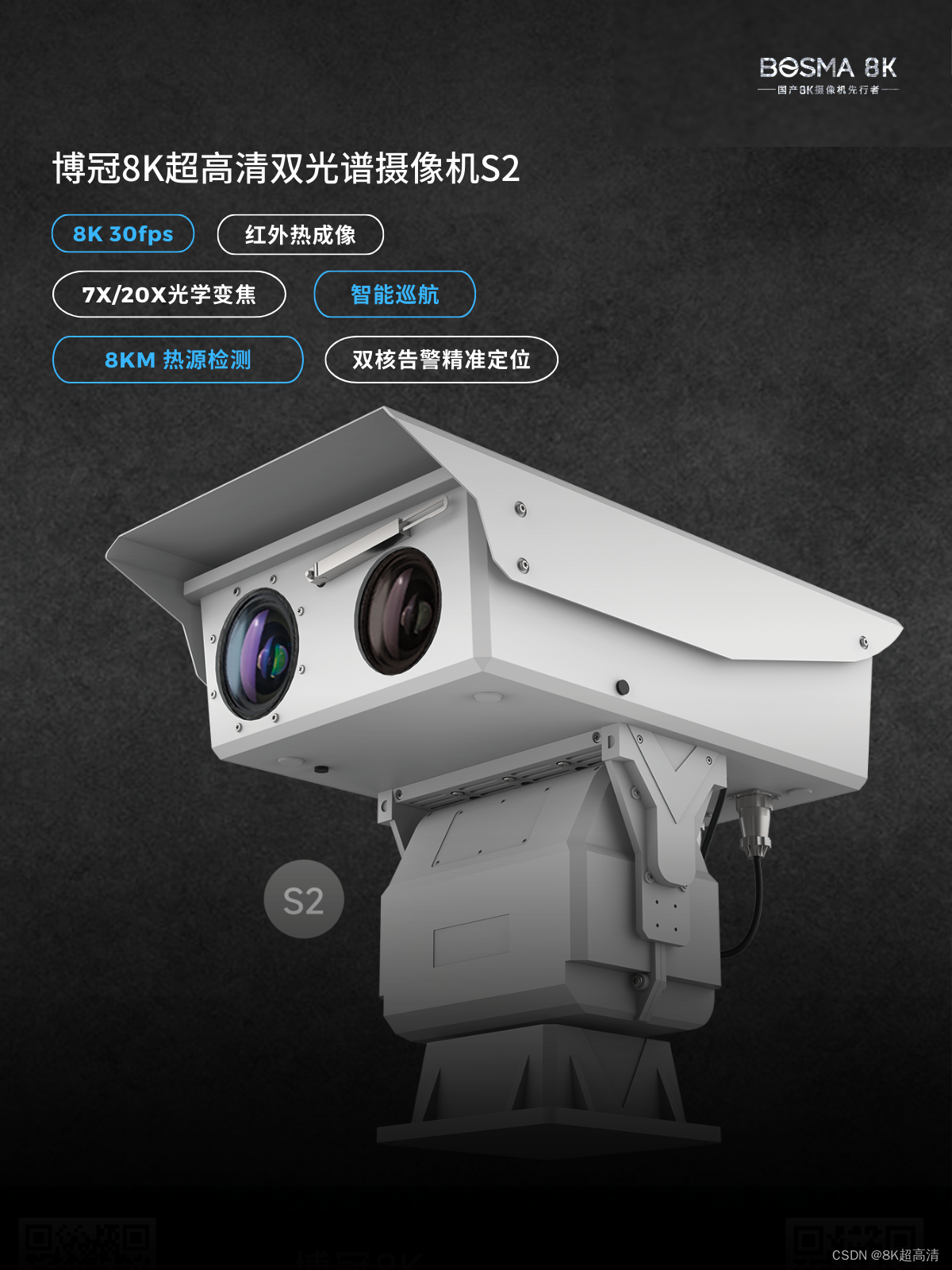
二、博冠8K超高清双光谱摄像机S2
作为国产8K摄像机先行者,BOSMA博冠不仅深研专业级8K采集,也在全产业链的角度上,推动8K技术与众多前沿技术的融合、应用。继国产全画幅8K摄像机后,他们又推出全球首款8K双光谱监控。
以博冠8K双光谱摄像机为核心,充分利用8K超高清、5G、AI、红外热成像、大数据与云计算等高新技术手段进行建设,实现全天候、全方位、远距离监测大范围区域,快速识别火情并准确预警,为应急响应赢得更多宝贵时间。随着科技的进步,8K双光谱摄像头应用于森林防火已成为可能。这种新技术可以用于检测火灾信息,并通过警报系统发出警报来控制火灾。
8K可见光与红外热成像
博冠8K双光谱监控摄像机S2拥有3300万像素,分辨率7680*4320,可以输出8K级别超高清视频,带来画质的全方位提升。在8K分辨率加持下,S2内嵌AI图像增强算法,开启后有效提高图像画质,减少过曝,算法实现自动监控画面颜色失真问题,还原真实色彩。F1.5~F2.6超大光圈镜头,低光摄像时进光量再提升,AI有效减少过曝,算法针对特殊对象自动调节图像参数,减少过曝,呈现更多细节。
4/3英寸图像传感器与业内先进红外热成像技术,实现24小时连续性监控,亮光下色彩清晰辨别,暗光下还原真实视界。作为业内首款8K可见光与红外热成像技术结合的监控产品,S2采用了业内先进的非制冷热成像探测器,成像效果好,不受外界照明影响,对于热点可以准确及时的报警显示,误报率低,标识准确,实现昼夜全天时实时热点探测视频监控;兼具近距离大范围搜索和远距离图像特征采集。
8K双光谱技术应用优势
精准识别火源。8K可见光与红外热成像双识别引擎交叉确认,叠加动态烟火快速识别算法,实现超高清可见光在白天精准识别烟、火,红外热成像在夜间加强监控巡视,降低漏报率与误报率,将森林火灾隐患扼杀在萌芽状态,营造可观的经济效益。
高空瞭望看全景。8K级别视频监控,3300万像素图像效果数十倍超越普通1080P高清,适合在高空上定点,360度全景覆盖,实现全局视野全貌观看,放大查看局部,兼顾细节的捕捉抓拍。值班人员可以直接通过监测平台对现场的火情态势、地形地貌、植被覆盖、风力风向等进行进一步研判分析,为下一步启动应急处置预案和火灾扑救提供信息支撑,在很大程度上提高森林防火工作的效率。
预警管理。一旦智能识别判定为火情后,系统会根据设备所在瞭望塔的经纬度位置,设备的水平俯仰角信息,定位出火情位置,并在电子地图上显示。同时以声音、短信等多种方式向有关部门人员进行告警,让防控更及时。
8K双光谱技术在应用于森林防火预警、森林资源监测之余,甚至可以进行野生动物拍摄记录,超高清记录动物迁徙痕迹,为林场运营增加更多可能性。