杭州 企业 建网站友情链接交易平台源码
Django开发入门 – 3.用Django创建一个Web项目
Build A Web Based Project With Django
By Jackson@ML
本文简要介绍如何利用最新版Python 3.13.2来搭建Django环境,以及创建第一个Django Web应用项目,并能够运行Django Web服务器。
创建该Django项目需要准备物理磁盘资源,同时使用Terminal和其它工具,逐步完成并建立一个Django新项目。大致有以下四个步骤:
1. 创建项目文件结构
为了归拢项目中涉及到所有文件(包括Python程序文件和其它文件等),最好的办法是创建统一的项目文件夹,如果需要容易识别,则命名为django-project为好。
1) 创建项目文件夹
在Terminal中,选择适当位置创建Django项目需要的文件夹,执行以下命令:
$ mkdir Django-project
2) 获取Visual Studio Code
为了增强关联度,使开发时能够在项目文件夹下创建其它文件,则使用集成开发环境(IDE)最为直观。
于是,让我们下载和安装Visual Studio Code并配置它具备Python开发环境。对于具体步骤,本文不再赘述,请参看文章:
2025最新版Visual Studio Code安装使用指南
3) 创建新的终端
打开安装好的Visual Studio Code,并打开该项目文件夹django-project,在Terminal菜单中,点击选择New Terminal,于是,在Visual Studio Code中打开新的终端,如下图所示:

2. 创建Django虚拟环境
1) 创建项目虚拟环境
新的终端打开后,显示在VS Code下方,执行以下命令,建立Djang项目所需的虚拟环境:
$ python3 -m venv django-env
于是,在VS Code左侧看到创建了子文件夹和相应的文件,如下图:

2) 激活虚拟环境
在创建的项目文件夹内,子文件夹/bin会有激活命令,于是,在终端内执行该命令(注意相对路径):
$ source django-env/bin/activate
虚拟环境激活成功!

可以看到,命令提示符前,已经有django-env字样,在一对圆括号()包裹下,位于终端命令行最前端,表明已处于独立的虚拟环境中。
接下来,安装所需的库,就可以在此独立虚拟环境中进行。
3. 创建Django项目
1) 安装Django
由于基于Python3系列开发,因此可以用pip3来安装Django:
$ pip3 install django
于是,开始出现“Collecting Django”并完成安装,结果如下图:

安装完毕,看到命令行提示pip工具可以更新升级,于是,执行该命令:
$ pip install –upgrade pip
结果如下图所示:

可以看到,pip版本已经升级为pip-25.0.1。
2) 验证Django版本
为确保Django安装完好,可以执行命令,验证Django版本:
$ python3 -m django version
结果如下图所示:

可以看到,当前安装版本为5.1.6.
3) 创建Django项目
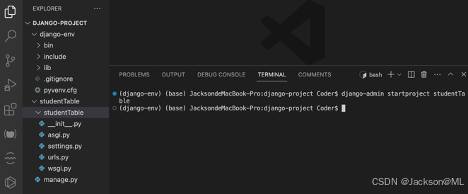
使用django-admin 命令可以创建新项目,加入新项目可命名为:studentTable。

可以看到,在项目文件夹django-project下,增加了studentTable子文件夹,其目录结构全貌如下:
4. 运行开发服务器
1) Manage.py文件
创建该项目时,自动创建了名为manage.py的Python脚本文件,在V S Code中查看该文件,如下图所示:

不难看出,该文件是作为“Django’s command-line Utility”,即Django命令行实用程序来运行的。也就是说,它是一个Django内置的应用程序,可以用该文件作为django的系列管理命令(或者称为自动批处理),
这样一来,它就可以自动分步骤执行Python脚本内容。像启动服务器这样,需要多个任务运行的动作,则非它莫属。
2) 启动运行开发服务器
即然manage.py可以自动化,那么依靠它,就可以用来直接启动运行服务器。
$ python3 manage.py runserver
结果如下图所示:

可以看到,该Web服务器已运行。
让我们一起来看看Web服务器的真面貌吧。
打开Chrome浏览器,在地址栏中输入本地Web服务器地址:
http://127.0.0:8000/
结果如下图:

由页面中央看到,”The install worked successfully! Congratulations!”,表明我们第一个项目创建成功!Web服务器已在本地成功运行。
能够看到这欣喜的一幕,倍感欣慰。
喜欢就请点赞和关注哈。
您的认可,我的动力!😃