java版wordpress石家庄手机端seo
单元测试
单元测试在日常项目开发中必不可少,Spring Boot提供了完善的单元测试框架和工具用于测试开发的应用。接下来介绍Spring Boot为单元测试提供了哪些支持,以及如何在Spring Boot项目中进行单元测试。
1.Spring Boot集成单元测试
单元测试主要用于测试单个代码组件,以确保代码按预期方式工作。目前流行的有JUnit或TestNG等测试框架。Spring Boot封装了单元测试组件spring-boot-starter-test。下面通过示例演示Spring Boot是如何实现单元测试的。
(1)引入依赖
首先创建Spring Boot项目。在项目中引入spring-boot-starter-test组件,示例配置如下:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope>
</dependency>
(2)创建单元测试
在src/test目录下新建一个HelloTest测试类,如果只想输出一句“Hello Spring Boot Test”,只需要用一个@Test注解即可。示例代码如下:
@SpringBootTest
public class HelloTest {@Testpublic void hello () {System.out.println("Hello Spring Boot Test");}
}
在类的上面添加@SpringBootTest注解,系统会自动把这段程序加载到Spring Boot容器。@Test注解表示该方法为单元测试方法。
(3) 运行单元测试
单击Run Test或在方法上右击,再选择“Run ‘hello’”,运行测试方法,运行结果如图所示。
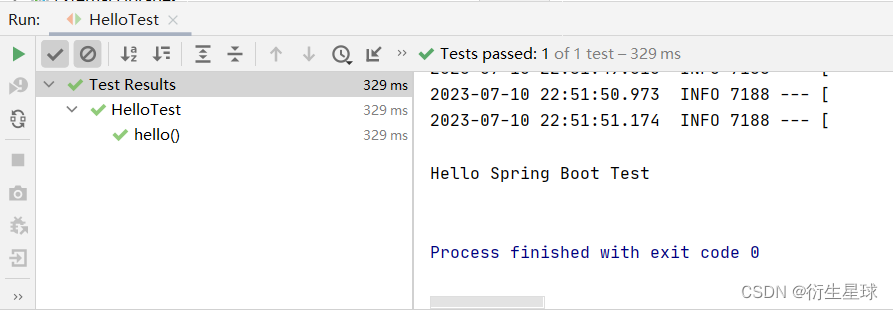
由图可知,单元测试方法运行成功并输出相应的结果,同时IDEA也会显示运行的所有单元测试结果,包括测试是否通过、运行时间、测试总数和成功次数等。以上示例中的测试方法只是spring-boot-starter-test组件中的一部分功能,Spring Boot自带的spring-boot-starter-test框架对测试的支持非常完善,包括Web请求测试、Service方法测试等,后面会逐一介绍。
2.测试Service方法
一般使用Spring Boot进行单元测试主要是针对Service和API(Controller)进行。接下来通过示例演示Spring Boot如何测试Service方法。
(1)创建Service测试类
创建Service测试类非常简单,使用IDEA可以一键自动创建单元测试类。首先,选择需要测试的Service类或方法,然后在对应的Service类中右击,选择Go To→Test→Create New Test,打开如图所示的创建测试类界面。
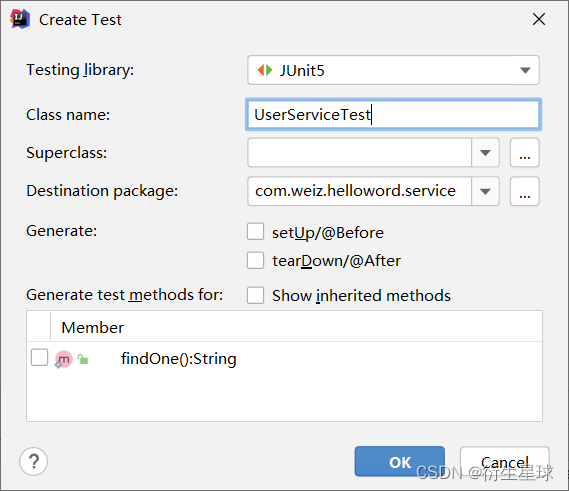
单击OK按钮,IDEA会在Test目录下创建一个UserServiceTest测试类,并为勾选的测试类自动生成单元测试的方法。
(2) 实现单元测试
在上面创建好的UserServiceTest类中会自动创建对应的单元测试方法,我们只需要在测试方法中实现对应的测试代码即可,具体的示例代码如下:
@SpringBootTest
public class UserServiceTest {@Autowiredprivate UserService userService;@Testpublic void findOne() throws Exception {Assert.assertEquals("1002", userService.findOne());}
}
如以上示例代码所示,在自动测试类上增加@SpringBootTest注解即可。首先注入需要测试的Service,然后在单元测试中调用该方法,最后通过Assert断句判断返回结果是否正确。
执行单元测试也非常简单,只需将鼠标放在对应的方法上,右击并选择Run执行该方法即可。
3.测试Controller接口方法
上面是针对Service进行测试,但是有时需要对API(Controller)进行测试,这时需要用到MockMvc类。MockMvc能够模拟HTTP请求,使用网络的形式请求Controller中的方法,这样可以使得测试速度快、不依赖网络环境,而且它提供了一套完善的结果验证工具,测试和验证也非常简单、高效。
spring-boot-starter-test具备强大的Mock能力,使用@WebMvcTest等注解实现模拟HTTP请求测试。下面通过示例演示如何测试Controller接口。
步骤01 创建Controller的测试类HelloControllerTest,实现单元测试方法。示例代码如下:
@RunWith(SpringRunner.class)
@WebMvcTest(HelloController.class)
class HelloControllerTest {@Autowiredprivate MockMvc mockMvc;@Testpublic void hello() throws Exception {mockMvc.perform(MockMvcRequestBuilders.post("/hello").contentType(MediaType.APPLICATION_JSON)).andExpect(status().isOk()).andDo(print());}
}
在上面的示例中,通过使用MockMvc构造一个post请求,MockMvcRequestBuilders可以支持post和get请求,调用print()方法将请求和相应的过程都打印出来。示例代码说明如下:
MockMvcRequestBuilders.post(“/hello”):构造一个post请求。
contentType (MediaType.APPLICATION_JSON)):设置JSON返回编码,避免出现中文乱码的问题。
andExpect(status().isOk()):执行完成后的断句,请求的状态响应码是否为200,如果不是则测试不通过。
andDo(print()):添加一个结果处理程序,表示要对结果进行处理,比如此处调用print()输出整个响应结果信息。
步骤02 执行单元测试。
完成测试方法之后,执行测试方法:将鼠标放在对应的方法上,右击并选择Run执行该方法即可。可以看到输出如下:

从上面的输出中可以看到,返回完整的Http Response,包括Status=200、Body = hello Spring Boot,说明接口请求成功并成功返回。
如果接口有登录验证,则需要通过MockHttpSession注入用户登录信息,或者修改登录拦截器取消对单元测试的登录验证。
4.常用的单元测试注解
在实际项目中,除了@SpringBootTest、@Test等注解之外,单元测试还有很多非常实用的注解,具体说明如表所示。
