网页设计作品文章免费刷seo
一般找数据集的都是需要训练底膜的,大家git上找的开源项目大多是预训练模型。预训练就是别人已经训练好的底膜,你在他的基础上进行调整。而我们训练如果他这个模型不理想是需要训练底膜的。
找的方式是从git开源上找
中文
推荐MockingBird,知更鸟里面有很多对外的中文数据集,或者去阿里的modelscope里面有数据集。
https://github.com/babysor/MockingBird/blob/main/README-CN.md

英文的,我找了几个比较好的
GitHub - robmsmt/ASR-Audio-Data-Links: A list of publically available audio data that anyone can download for ASR or other speech activities
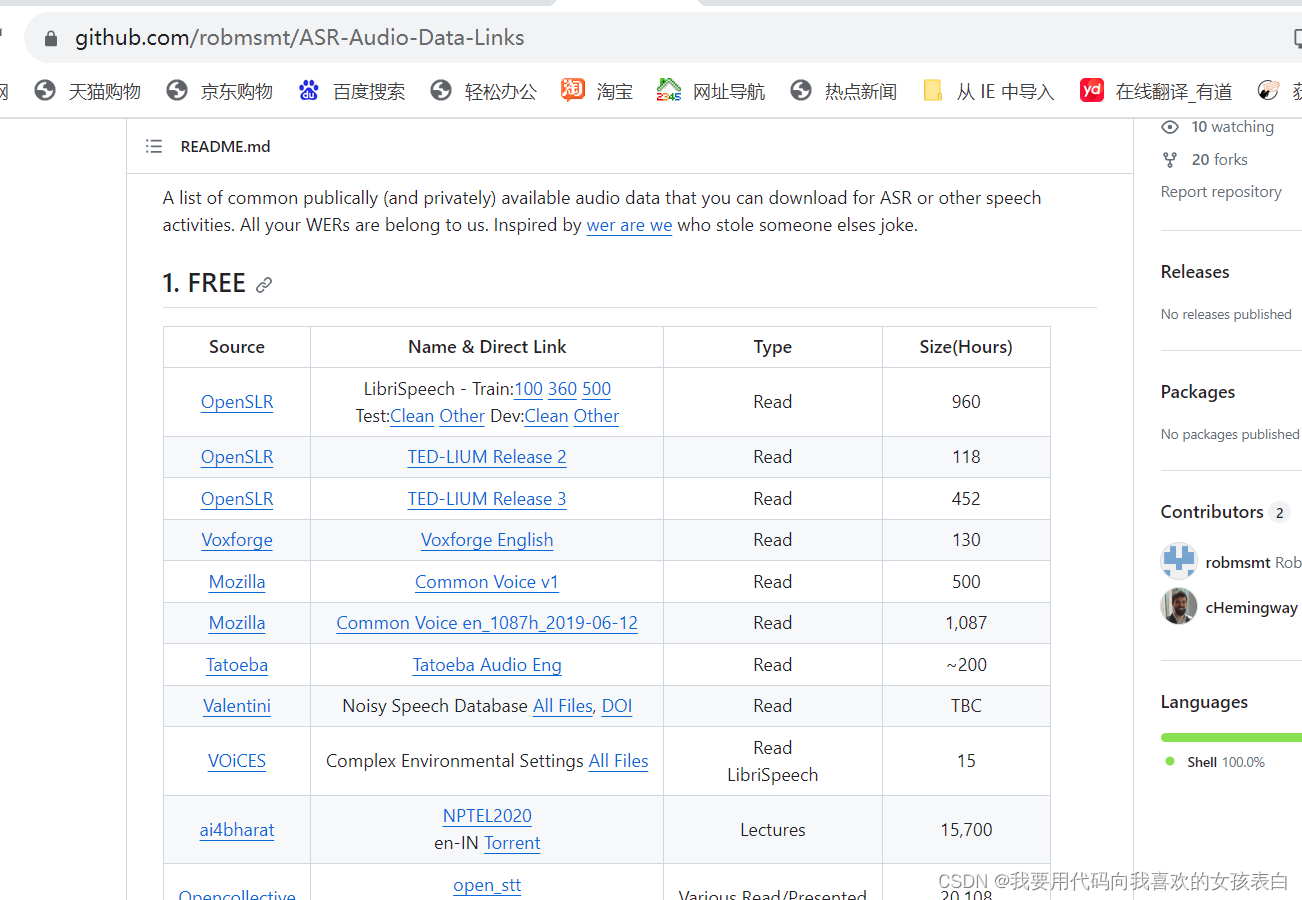
点击可以直接进入,下载,有火狐还有一些非盈利公司等提供的音频
关于其他语言
就要自己在git上看了,总之git上都有,开源大家庭就是好啊,造福全人类呀