负责公司网站的日常管理免费站推广网站2022
数据库管理 2023-02-10
- 第五十六期 监控
- 1 怎么监控
- 2 直观
- 3 历史分析
- 4 另一个BUG
- 总结
第五十六期 监控
春节后的7天班过后就来到了2月份,本周对之前发现X8M上的那个bug进行补丁修复和协助从12.2迁移了一套PDB到这个一体机上面,2次割接。这周还和原厂老大哥聊了一下,其他地方是如何监控数据库的问题,本期内容就由此展开。
1 怎么监控
和老大哥聊的是另一家数据库维护大厂维护的一个项目,其实客户是买了EMCC的,也部署了大厂自己开发的数据库监控平台,但是现场的情况是EMCC没人用,数据库监控平台也变成主要由客户使用。现场维护团队技术leader是一位“怀旧”的人,在他的的要求下,所有巡检监控通过脚本或者手工实现,脚本结果再通过Excel之类的工具再汇聚成结果,用的是很传统的非实时的监控方法;另一方面呢,还在坚持使用11g(11.2.0.4)版本,虽然11204是一个优秀的版本,但是毕竟廉颇老矣,而且原厂也停止该版本的支持了,特别是遇到bug,很难修复。
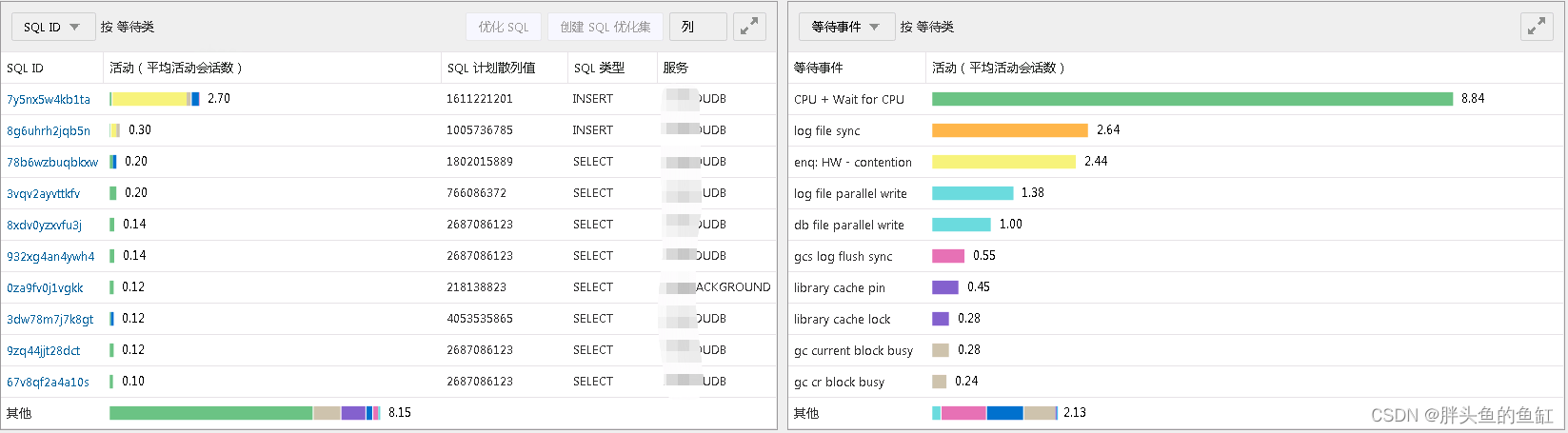
在我长期的DBA工作经历中,我认为实时的数据库监控(及告警)还是很有必要的,在出现异常的时候可以非常迅速的对问题进行定位,以EMCC的ASH分析页面为例,当我发现数据库等待较高时:

可以快速在ASH分析页面中,对SQL ID和等待时间进行对比分析,可以非常快速的发现是一条insert引起了大量的enq: HW - contention等待:
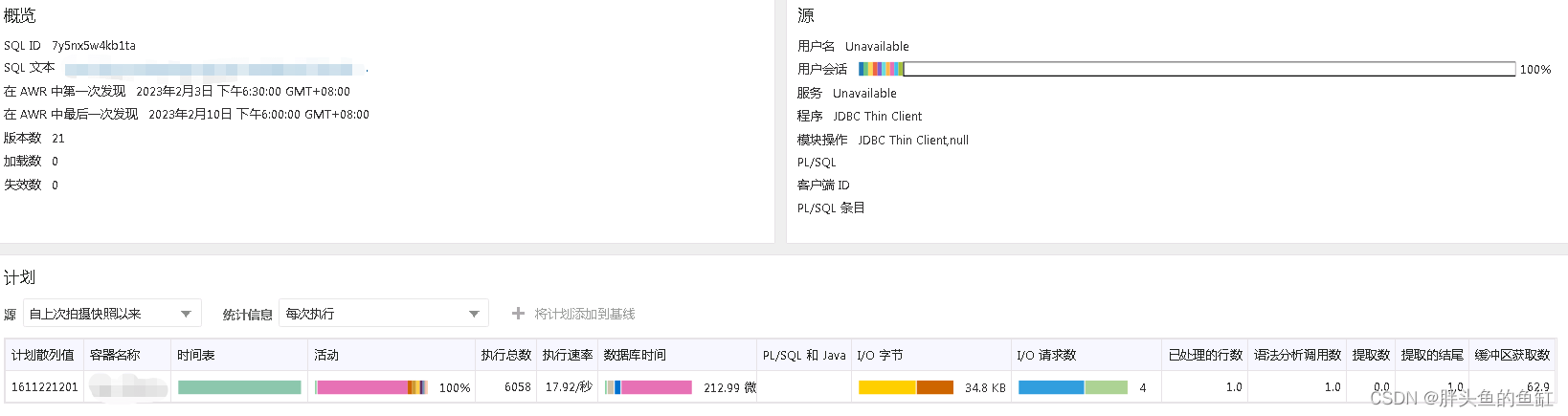
进入语句详情则发现这条insert语句是日志记录语句,没有批量提交也没有限流,造成了“壮汉挤门”的现象,所幸通过与业务方分析,这个日志记录与业务流程非强相关,是异步的,因此仅仅只会对这一张表造成影响,不会造成业务卡顿和主机CPU占用增加:
但是日志作为非常重要的一部分,涉及溯源查询,还是建议业务方批量提交事务或限流,抑或使用MongoDB或ES来存储日志。
2 直观
排查上面这个问题,如果用传统的方式,可能就要涉及一大堆SQL语句,包含当前数据库锁和等待情况查询、SQL详情查询、SQL执行计划输出、ASH查询等等,很可能还需要等到下一次AWR快照完成后(手动也行)打印AWR报表,再将查到的所有内容关联起来进行计算分析,才能得到结果,如果涉及影响生产,紧急处理不是不行,但是很可能造成溯源很麻烦。而类似于EMCC这类监控平台则非常直观的展示本需要繁琐操作、计算、统计、分析之后的结果,加快了处理问题的效率。
3 历史分析
那么一个数据库监控平台处理实时性,可以及时查询需要内容以外,对历史信息信息的展示也是非常重要的,很多时候我们查询一些性能问题都是事后查询的,在事后也能像刚才查询“壮汉挤门”这个操作这么简单,当然是最好的。
小结一下: 当然监控不是万能的,很多时候分析问题还是需要去排查相关日志,但是不得不说,一个可以实时监控、提供历史查询和实时告警能力的直观展示所有信息的数据库监控平台还是很有必要的,至少维护人员可以轻松很多。
4 另一个BUG
这个其实也是我在使用EMCC的时候发现的一个问题,X8M上出现了一个问题,涉及PDB的SQL Monitor在集群页面输出失败,只能进入PDB页面中才能输出,在sqlplus中则是SQL monitor语句再CDB中执行失败,进PDB才能正确得到结果;X9M上则是某个PDB无论在集群页面还是进入PDB页面都输出失败,而其他PDB则没有这个问题,在sqlplus中就是涉及这个PDB的SQL在哪执行SQL monitor语句再CDB中执行失败,其他PDB的语句就没问题。报错信息如下:
EMCC:
ORA-12801: error signaled in parallel query server PPA7, instance xxxsqlplus:
ERROR:
ORA-12801: error signaled in parallel query server PPA7, instance
xxx (1)
ORA-06512: at "SYS.DBMS_SQLTUNE", line 18940
ORA-22921: length of input buffer is smaller than amount requested
ORA-06512: at "SYS.DBMS_SQLTUNE", line 14318
ORA-06512: at "SYS.DBMS_SQLTUNE", line 19036
ORA-06512: at "SYS.DBMS_SQLTUNE", line 19367
ORA-06512: at line 1
当然这个其实也不是很重视,首先两台一体机都没有涉及到影响生产,其次是X8M那台还是看得到,X9M那个PDB虽然重要,但是在ASH分析里面还是能看到执行计划,影响也不大。但总归有问题,需要处理,SR开起,MOS小姐姐联系上,迅速定位一个BUG: Bug 34291138 : DBMS_SQLTUNE.REPORT_SQL_MONITOR FAILS WITH ORA-12801 AND ORA-22921 ERRORS.(Base Bug 33241359:DBMS_SQLTUNE.REPORT_SQL_MONITOR GENERATE ORA-22921 WITH PPA PROCESS - 找补丁用这个编号)。而且这个BUG涉及到了19c的绝大多数版本,如果你遇到了且没有workaround,可以考虑申请并应用相关版本的补丁。
其实这个小bug倒不是什么事,主要是MOS小姐姐有个消息让我比较震惊,Oracle现在有一套工具,通过opatch lsinv输出,可以在某些特定情况自动根据BUG生产补丁。可见现在Oracle数据库的设计及代码还是十分优秀的。
总结
还在等待ACE的评审,不晓得结果咋样,内心忐忑。
老规矩,知道写了些啥。