网站被host重定向处理怎么做一个免费的网站
目录
一.HTTPS概述
二.概念准备
三.为什么要加密
四.常⻅的加密⽅式
1.对称加密
2.⾮对称加密
五.数据摘要,数字签名
六.HTTPS的加密过程探究
1.方案一——只使用对称加密
2.方案二——只使⽤⾮对称加密
3.方案三——双⽅都使⽤⾮对称加密
4.方案四——⾮对称加密+对称加密
5. 中间人攻击
七.引⼊证书
1.CA认证
2.理解数据签名
3.⽅案5-⾮对称加密+对称加密+证书认证

一.HTTPS概述
HTTPS也是⼀个应⽤层协议,是在HTTP协议的基础上引⼊了⼀个加密层。
HTTP协议内容都是按照⽂本的⽅式明⽂传输的,这就导致在传输过程中容易出现⼀些被篡改的情况。
http为什么不安全?
下图是http协议在用户在表单中提交的用户名和密码,用户名和密码都是明文传输的,存在的严重的风险,在2012年以前,账号基本都是没有绑定手机号的要求,这就导致了只要知道了你的用户名和密码,就能轻易的将号盗取。

HTTPS存在的意义就是加密传输报文。
二.概念准备
加密就是把明⽂(要传输的信息)进⾏⼀系列变换,⽣成密⽂。
解密就是把密⽂再进⾏⼀系列变换,还原成明⽂。
在这个加密和解密的过程中,往往需要⼀个或者多个中间的数据,辅助进⾏这个过程,这样的数据称为密钥。
加密解密到如今已经发展成⼀个独⽴的学科:密码学。
⽽密码学的奠基⼈,也正是计算机科学的祖师爷之⼀,艾伦·⻨席森·图灵。

对比我们的另外一外祖师爷:约翰·冯·诺依曼

好像图灵⼤佬的头发有点多.....
其实这是⼀个悲伤的故事.图灵⼤佬年少有为,不光奠定了计算机,⼈⼯智能,密码学的基础,并且在⼆战中⼤破德军的Enigma机,使盟军占尽情报优势,才能扭转战局反败为胜.但是因为⼀些原因,图灵⼤佬遭到英国皇室的迫害,41岁就英年早逝了.
有一部电影《模仿游戏》改变自《艾伦·图灵传》讲的就是二战中图灵大佬研制破译机的故事。
计算机领域中的最⾼荣誉就是以他名字命名的"图灵奖"。
三.为什么要加密
臭名昭著的"运营商劫持"
在没有普及https协议的时候,将出现我们在网上搜索下载一个软件,当我们点击了下载的时候,弹出的下载连接却是其他软件的下载连接。
由于我们通过⽹络传输的任何的数据包都会经过运营商的⽹络设备(路由器,交换机等),那么运营商的⽹络设备就可以解析出你传输的数据内容,并进⾏篡改。
点击"下载按钮",其实就是在给服务器发送了⼀个HTTP请求,获取到的HTTP响应其实就包含了该APP的下载链接.运营商劫持之后,就发现这个请求是要下载"天天动听",那么就⾃动的把交给⽤户的响应给篡改成"某Q浏览器"的下载地址了。

所以:因为http的内容是明⽂传输的,明⽂数据会经过路由器、wifi热点、通信服务运营商、代理服务器等多个物理节点,如果信息在传输过程中被劫持,传输的内容就完全暴露了。劫持者还可以篡改传输的信息且不被双⽅察觉,这就是 中间⼈攻击 ,所以我们才需要对信息进⾏加密。
不⽌运营商可以劫持,其他的⿊客也可以⽤类似的⼿段进⾏劫持,来窃取⽤⼾隐私信息,或者篡改内容.
试想⼀下,如果⿊客在⽤⼾登陆⽀付宝的时候获取到⽤⼾账⼾余额,?甚⾄获取到⽤⼾的⽀付密码.....
在互联⽹上,明⽂传输是⽐较危险的事情!!!
HTTPS就是在HTTP的基础上进⾏了加密,进⼀步的来保证⽤户的信息安全。
四.常⻅的加密⽅式
1.对称加密
采⽤单钥密码系统的加密⽅法,同⼀个密钥可以同时⽤作信息的加密和解密,这种加密⽅法称为对
称加密,也称为单密钥加密,特征:加密和解密所⽤的密钥是相同的。
- 常⻅对称加密算法(了解):DES、3DES、AES、TDEA、Blowfish、RC2等。
- 特点:算法公开、计算量⼩、加密速度快、加密效率⾼
对称加密其实就是通过同⼀个?"密钥",把明⽂加密成密⽂,⽂解密成明⽂.
例如最简单的一个对称加密原理——异或运算:
假设明⽂a=1234,密钥key=8888
则加密a^key得到的密⽂b为9834.
然后针对密⽂9834再次进⾏运算b^key,得到的就是原来的明⽂1234.
(对于字符串的对称加密也是同理,每⼀个字符都可以表⽰成⼀个数字)
当然,按位异或只是最简单的对称加密.HTTPS中并不是使⽤按位异或.
2.⾮对称加密
需要两个密钥来进⾏加密和解密,这两个密钥是公开密钥(publickey,简称公钥)和私有密钥
(privatekey,简称私钥)。
- 常⻅⾮对称加密算法(了解):RSA,DSA,ECDSA
- 特点:算法强度复杂、安全性依赖于算法与密钥但是由于其算法复杂,⽽使得加密解密速度没有对称加密解密的速度快。
⾮对称加密要⽤到两个密钥,⼀个叫做"公钥",⼀个叫做"私钥".
公钥和私钥是配对的.最⼤的缺点就是运算速度⾮常慢,⽐对称加密要慢很多.
- 通过公钥对明⽂加密,变成密⽂
- 通过私钥对密⽂解密,变成明⽂
也可以反着⽤
- 通过私钥对明⽂加密,变成密⽂
- 通过公钥对密⽂解密,变成明⽂
⾮对称加密的数学原理⽐较复杂,涉及到⼀些数论相关的知识.这⾥举⼀个简单的⽣活上的例⼦.
A要给B⼀些重要的⽂件,但是B可能不在.于是A和B提前做出约定:
B说:我桌⼦上有个盒⼦,然后我给你⼀把锁,你把⽂件放盒⼦⾥⽤锁锁上,然后我回头拿着钥匙来开锁
取⽂件.
在这个场景中,这把锁就相当于公钥,钥匙就是私钥.公钥给谁都⾏(不怕泄露),但是私钥只有B⾃⼰持
有.持有私钥的⼈才能解密.
五.数据摘要,数字签名
- 数字摘要(数据指纹),其基本原理是利⽤单向散列函数(Hash函数)对信息进⾏运算,⽣成⼀串固定⻓度的数字摘要。数字指纹并不是⼀种加密机制,但可以⽤来判断数据有没有被窜改。一旦数据被篡改,哪怕只是修改了一个比特位,再次利⽤单向散列函数(Hash函数)对信息进⾏运算得到的结果都会有非常大的差异。
- 摘要常⻅算法:有MD5、SHA1、SHA256、SHA512等,算法把⽆限的映射成有限,因此可能会有碰撞(两个不同的信息,算出的摘要相同,但是概率⾮常低),在时间空间有限的请情况下几乎不会发生。
- 摘要特征:和加密算法的区别是,摘要严格意义不是加密,因为没有解密,只不过从摘要很难反推原信息,通常⽤来进⾏数据对⽐。
- 摘要经过加密,就得到数字签名(后面说)。
六.HTTPS的加密过程探究
既然要保证数据安全,就需要进⾏"加密"。
⽹络传输中不再直接传输明⽂了,⽽是加密之后的"密⽂"。
加密的⽅式有很多,但是整体可以分成两⼤类:对称加密和⾮对称加密。
1.方案一——只使用对称加密
如果通信双⽅都各⾃持有同⼀个密钥X,且没有别⼈知道,这两⽅的通信安全当然是可以被保证的(除⾮密钥被破解)。
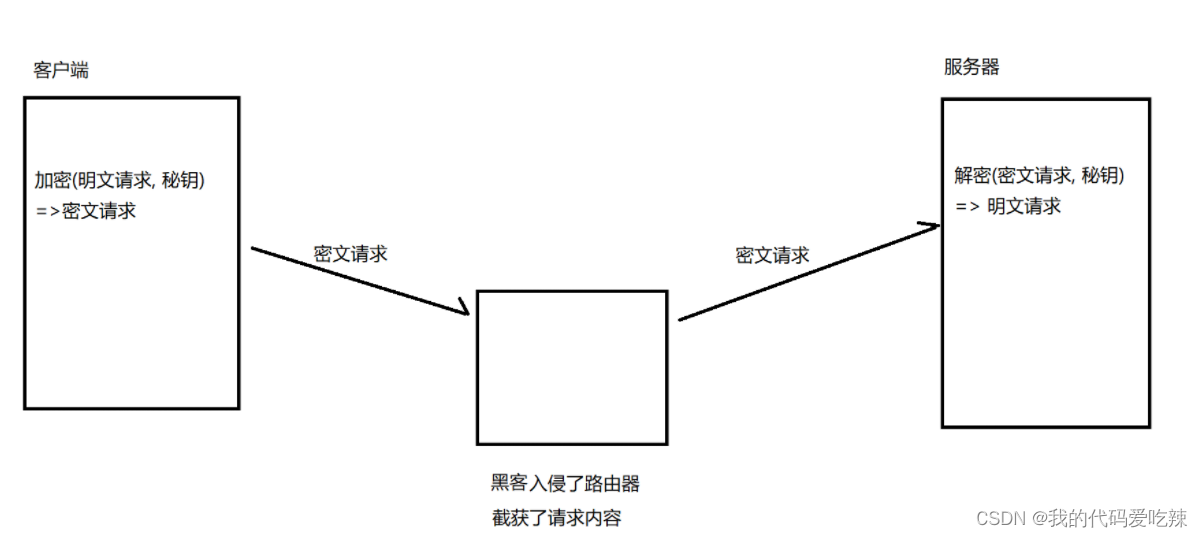
引⼊对称加密之后,即使数据被截获,由于⿊客不知道密钥是啥,因此就⽆法进⾏解密,也就不知道请求
的真实内容是啥了.
但事情没这么简单.服务器同⼀时刻其实是给很多客⼾端提供服务的.这么多客⼾端,每个⼈⽤的秘钥都必须是不同的(如果是相同那密钥就太容易扩散了,⿊客就也能拿到了).因此服务器就需要维护每个客⼾端和每个密钥之间的关联关系,这也是个很⿇烦的事情。
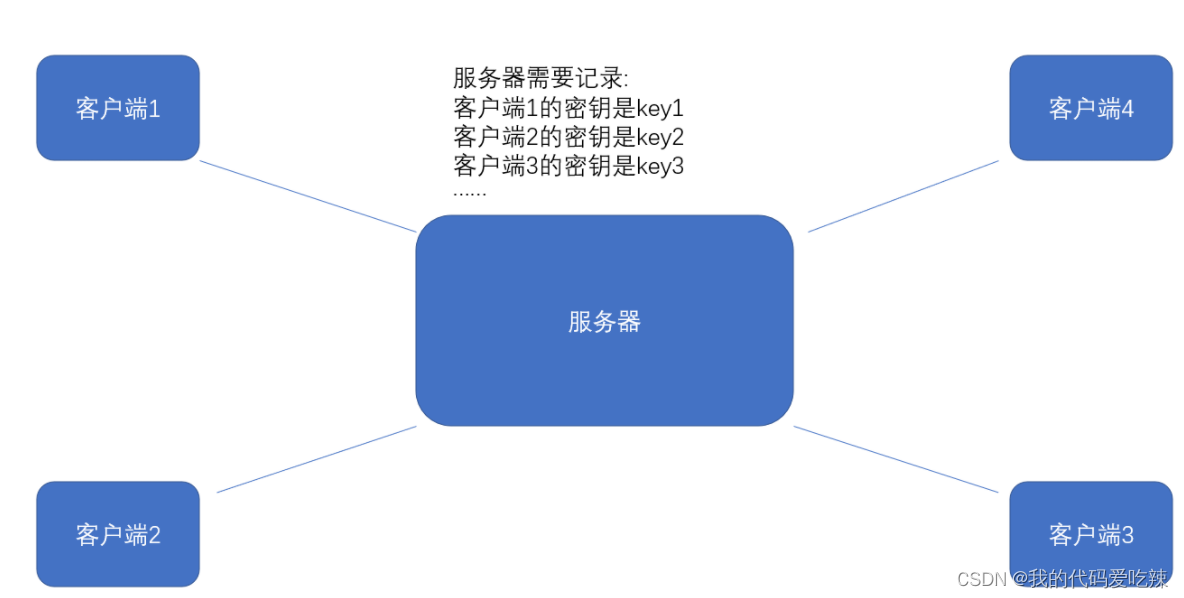
⽐较理想的做法,就是能在客户端和服务器建⽴连接的时候,双⽅协商确定这次的密钥是啥。
但是如果在协商密钥的时候,使用明文传送,密钥的内容就容易被黑客截获,因此密钥的传输也必须加密传输!如果要对密钥加密传输,就需要一个 密钥的密钥 ,这就变成了一个鸡生蛋,蛋生鸡的问题了。此时密钥的传输再⽤对称加密就⾏不通了。
2.方案二——只使⽤⾮对称加密
鉴于⾮对称加密的机制,如果服务器先把公钥以明⽂⽅式传输给浏览器,之后浏览器向服务器传数据前都先⽤这个公钥加密好再传,从客户端到服务器信道似乎是安全的(有安全问题),因为只有服务器有相应的私钥能解开公钥加密的数据。
但是服务器到浏览器的这条路怎么保障安全?
如果服务器⽤它的私钥加密数据传给浏览器,那么浏览器⽤公钥可以解密它,⽽这个公钥是⼀开始通过明⽂传输给浏览器的,若这个公钥很容易被中间⼈劫持到了,那他也能⽤该公钥解密服务器传来的信息了。
3.方案三——双⽅都使⽤⾮对称加密
- 服务端拥有公钥S与对应的私钥S',客⼾端拥有公钥C与对应的私钥C'。
- 客⼾和服务端交换公钥。
- 客⼾端给服务端发信息:先⽤S对数据加密,再发送,只能由服务器解密,因为只有服务器有私钥S'。
- 服务端给客⼾端发信息:先⽤C对数据加密,在发送,只能由客⼾端解密,因为只有客⼾端有私钥C'。

这样看似解决了安全问题,实际上仍然有安全问题,而且又使得整体的效率变得很低。
4.方案四——⾮对称加密+对称加密
先解决效率问题: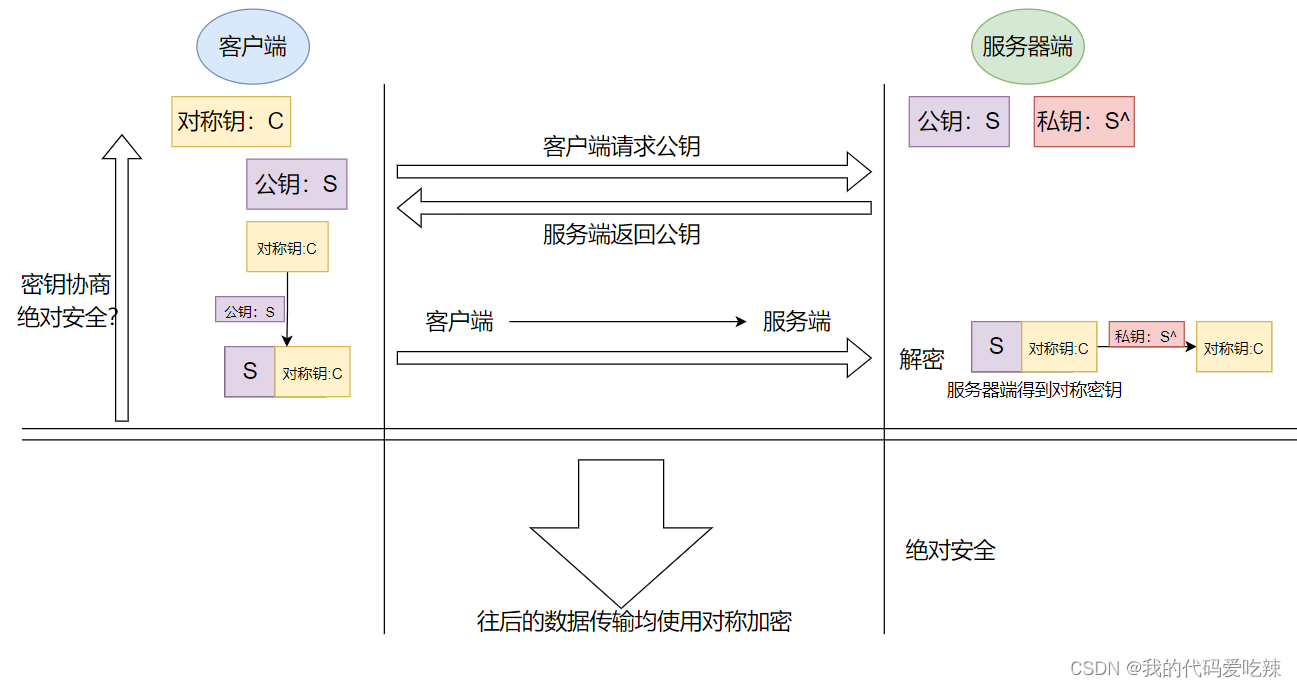
- 服务端具有⾮对称公钥S和私钥S'。
- 客户端发起https请求,获取服务端公钥S。
- 客户端在本地⽣成对称密钥C,通过公钥S加密,发送给服务器。
- 由于中间的⽹络设备没有私钥,即使截获了数据,也⽆法还原出内部的原⽂,也就⽆法获取到对称密钥(真的吗?)。
- 服务器通过私钥S'解密,还原出客⼾端发送的对称密钥C.并且使⽤这个对称密钥加密给客⼾端返回的响应数据。
- 后续客⼾端和服务器的通信都只⽤对称加密即可.由于该密钥只有客⼾端和服务器两个主机知道,其他主机/设备不知道密钥即使截获数据也没有意义.
5. 中间人攻击
上述方案均存在一个致命的问题——无法拦截中间人攻击。Man-in-the-MiddleAttack,简称“MITM攻击”。
确实,在⽅案2/3/4中,客户端获取到公钥S之后,对客户端形成的对称秘钥C⽤服务端给客户端的公钥S进⾏加密,中间⼈即使窃取到了数据,此时中间⼈确实⽆法解出客户端形成的密钥C,因为只有服务器有私钥S。
但是中间⼈的攻击,如果在最开始握⼿协商的时候就进⾏了,那就不⼀定了,假设hacker已经成功成为中间⼈。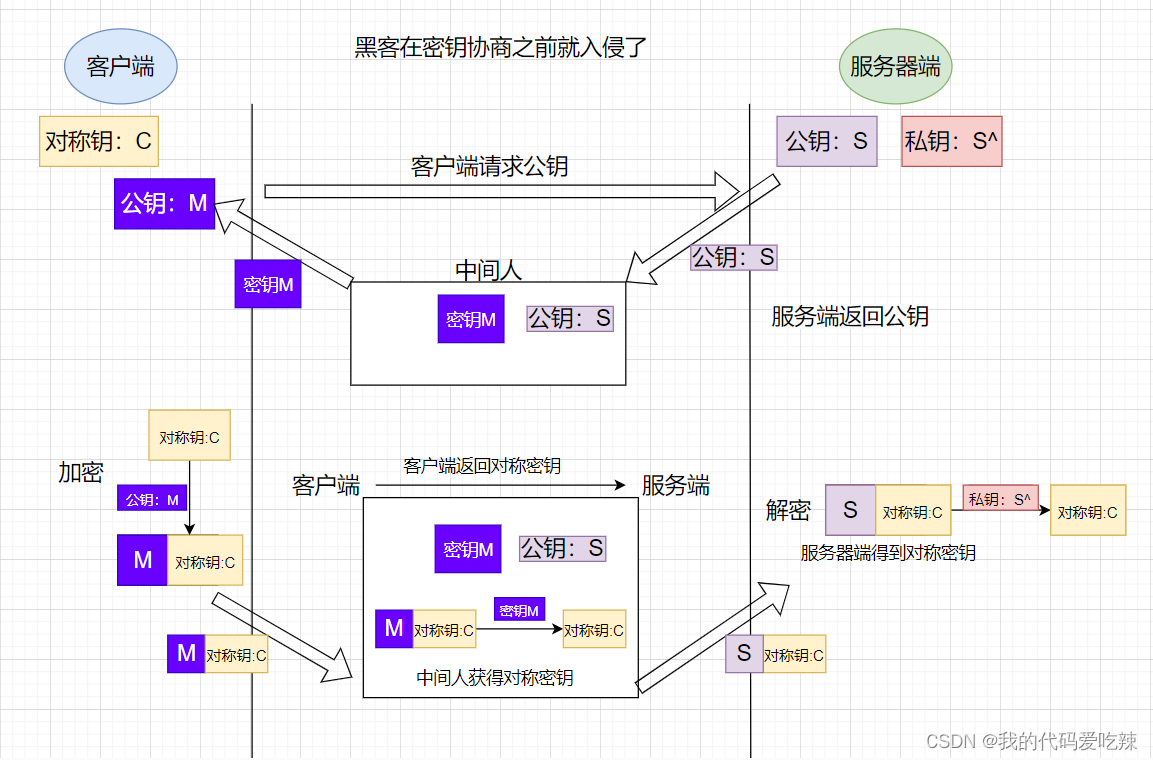
- 服务器具有⾮对称加密算法的公钥S,私钥S'。
- 中间⼈具有⾮对称加密算法的公钥M,私钥M'。
- 客户端向服务器发起请求,服务器明⽂传送公钥S给客户端。
- 中间⼈劫持数据报⽂,提取公钥S并保存好,然后将被劫持报⽂中的公钥S替换成为⾃⼰的公钥M,并将伪造报⽂发给客户端。
- 客户端收到报⽂,提取公钥M(⾃⼰当然不知道公钥被更换过了),⾃⼰形成对称秘钥X,⽤公钥M加密X,形成报⽂发送给服务器。
- 中间⼈劫持后,直接⽤⾃⼰的私钥M'进⾏解密,得到通信秘钥X,再⽤曾经保存的服务端公钥S加密后,将报⽂推送给服务器。
- 服务器拿到报⽂,⽤⾃⼰的私钥S'解密,得到通信秘钥X。
- 双⽅开始采⽤X进⾏对称加密,进⾏通信。但是⼀切都在中间⼈的掌握中,劫持数据,进⾏窃听甚⾄修改,都是可以的。
问题本质出在哪⾥了呢?客⼾端⽆法确定收到的含有公钥的数据报⽂,就是⽬标服务器发送过来的!
七.引⼊证书
1.CA认证
服务端在使⽤HTTPS前,需要向CA机构申领⼀份数字证书,数字证书⾥含有证书申请者信息、公钥信息等。服务器把证书传输给浏览器,浏览器从证书⾥获取公钥就⾏了,证书就如⾝份证,证明服务端公钥的权威性。
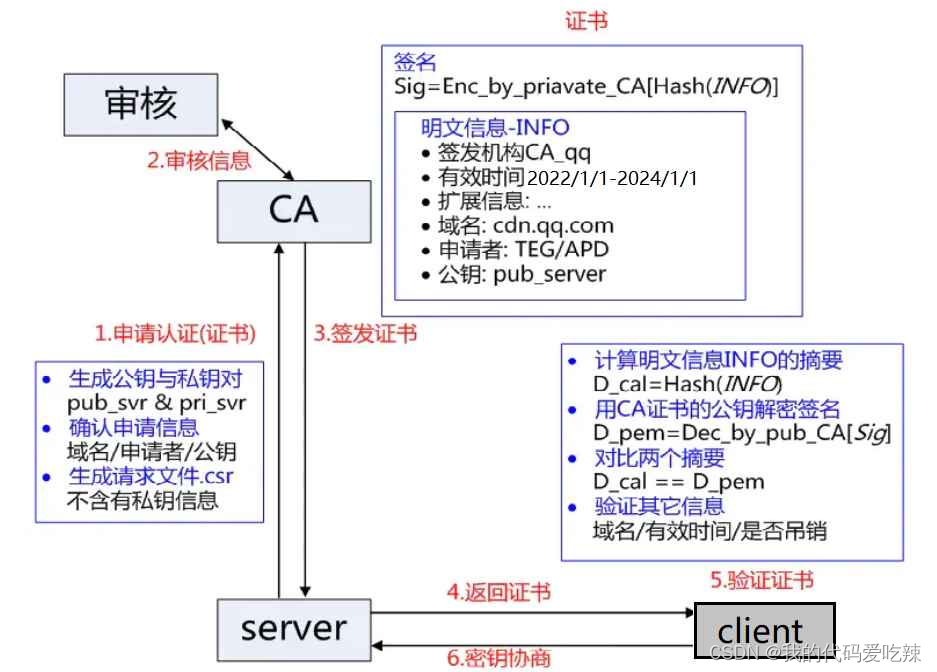
这个证书可以理解成是⼀个结构化的字符串,⾥⾯包含了以下信息:证书发布机构,证书有效期,公钥,证书所有者签名。
需要注意的是:申请证书的时候,需要在特定平台⽣成查,会同时⽣成⼀对⼉密钥对⼉,即公钥和私钥。这对密钥对⼉就是⽤来在⽹络通信中进⾏明⽂加密以及数字签名的。
其中公钥会随着CSR⽂件,⼀起发给CA进⾏权威认证,私钥服务端⾃⼰保留,⽤来后续进⾏通信(其实主要就是⽤来交换对称秘钥)。
2.理解数据签名
签名的形成是基于⾮对称加密算法的(CA机构的公钥和私钥),注意,⽬前暂时和https没有关系,不要和https中的公钥私钥搞混了。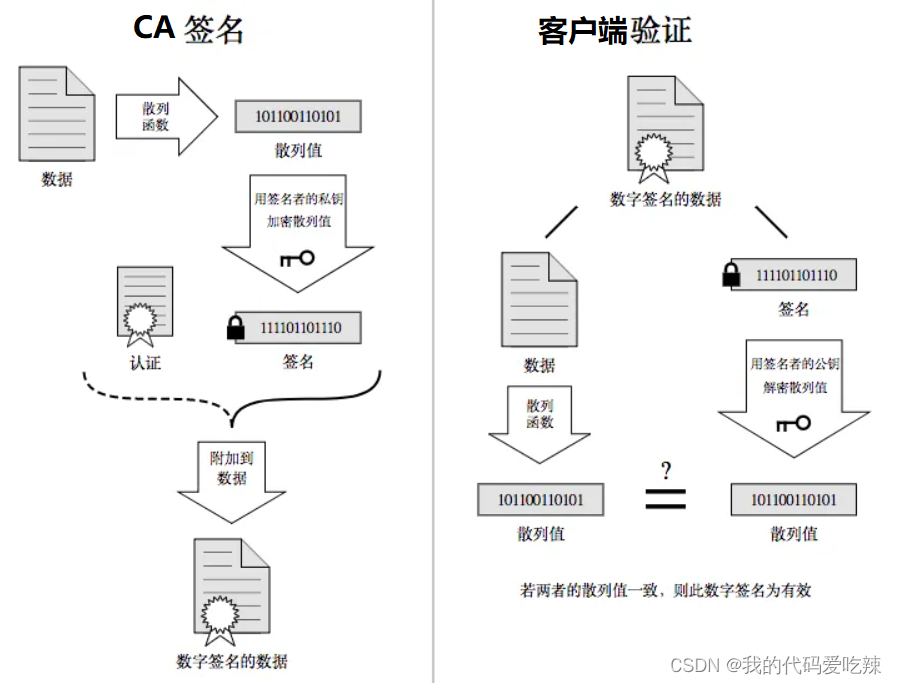
当服务端申请CA证书的时候,CA机构会对该服务端进⾏审核,并专⻔为该⽹站形成数字签名,过程如下:
- CA机构拥有⾮对称加密的私钥A和公钥A'
- CA机构对服务端申请的证书明⽂数据进⾏hash,形成数据摘要
- 然后对数据摘要⽤CA私钥A'加密,得到数字签名S
服务端申请的证书明⽂和数字签名S共同组成了数字证书,这样⼀份数字证书就可以颁发给服务端了。
3.⽅案5-⾮对称加密+对称加密+证书认证
在客户端和服务器刚⼀建⽴连接的时候,服务器给客户端返回⼀个证书,证书包含了之前服务端的公钥,也包含了⽹站的⾝份信息.
客⼾端进⾏认证:
当客⼾端获取到这个证书之后,会对证书进⾏校验(防⽌证书是伪造的).
- 判定证书的有效期是否过期。
- 判定证书的发布机构是否受信任(操作系统中已内置的受信任的证书发布机构)。
- 验证证书是否被篡改:从系统中拿到该证书发布机构的公钥,对签名解密,得到⼀个hash值(称为数。据摘要),设为hash1.然后计算整个证书的hash值,设为hash2.对⽐hash1和hash2是否相等.如果相等,则说明证书是没有被篡改过的。
中间⼈有没有可能篡改该证书?
- 中间⼈篡改了证书的明⽂
- 由于他没有CA机构的私钥,所以⽆法hash之后⽤私钥加密形成签名,那么也就没法办法对篡改后的证书形成匹配的签名
- 如果强⾏篡改,客⼾端收到该证书后会发现明⽂和签名解密后的值不⼀致,则说明证书已被篡改,证书不可信,从⽽终⽌向服务器传输信息,防⽌信息泄露给中间⼈
中间⼈整个掉包证书?
- 因为中间⼈没有CA私钥,所以⽆法制作假的证书(为什么?)。
- 所以中间⼈只能向CA申请真证书,然后⽤⾃⼰申请的证书进⾏掉包。
- 这个确实能做到证书的整体掉包,但是别忘记,证书明⽂中包含了域名等服务端认证信息,如果整体掉包,客⼾端依旧能够识别出来。
- 永远记住:中间⼈没有CA私钥,所以对任何证书都⽆法进⾏合法修改,包括⾃⼰的。
为什么摘要内容在⽹络传输的时候⼀定要加密形成签名?
常⻅的摘要算法有:MD5和SHA系列
以MD5为例,我们不需要研究具体的计算签名的过程,只需要了解MD5的特点:
- 定⻓:⽆论多⻓的字符串,计算出来的MD5值都是固定⻓度(16字节版本或者32字节版本)。
- 分散:源字符串只要改变⼀点点,最终得到的MD5值都会差别很⼤。
- 不可逆:通过源字符串⽣成MD5很容易,但是通过MD5还原成原串理论上是不可能的。
正因为MD5有这样的特性,我们可以认为如果两个字符串的MD5值相同,则认为这两个字符串相同.
理解判定证书篡改的过程:(这个过程就好⽐判定这个⾝份证是不是伪造的⾝份证)。
假设我们的证书只是⼀个简单的字符串hello,对这个字符串计算hash值(⽐如md5),结果为
BC4B2A76B9719D91。
如果hello中有任意的字符被篡改了,⽐如变成了hella,那么计算的md5值就会变化很⼤.
BDBD6F9CF51F2FD8。
然后我们可以把这个字符串hello和哈希值BC4B2A76B9719D91从服务器返回给客户端,此时客⼾端
如何验证hello是否是被篡改过?
那么就只要计算hello的哈希值,看看是不是BC4B2A76B9719D91即可.
但是还有个问题,如果⿊客把hello篡改了,同时也把哈希值重新计算下,客户端就分辨不出来了呀.所以被传输的哈希值不能传输明⽂,需要传输密⽂。黑客虽然可以解密,但是无法使用对应的私钥加密。也就无法形成签名。
所以,对证书明⽂(这⾥就是“hello”)hash形成散列摘要,然后CA使⽤⾃⼰的私钥加密形成签名,将
hello和加密的签名合起来形成CA证书,颁发给服务端,当客⼾端请求的时候,就发送给客户端,中间⼈截获了,因为没有CA私钥,就⽆法更改或者整体掉包,就能安全的证明,证书的合法性。
最后,客户端通过操作系统⾥已经存的了的证书发布机构的公钥进⾏解密,还原出原始的哈希值,再进⾏校验.
为什么签名不直接加密,⽽是要先hash形成摘要?
- 缩⼩签名密⽂的⻓度,加快数字签名的验证签名的运算速度
如何成为中间⼈
- ARP欺骗:在局域⽹中,hacker经过收到ARPRequest⼴播包,能够偷听到其它节点的(IP,MAC)地址。例,⿊客收到两个主机A,B的地址,告诉B(受害者),⾃⼰是A,使得B在发送给A的数据包都被⿊客截取。
- ICMP攻击:由于ICMP协议中有重定向的报⽂类型,那么我们就可以伪造⼀个ICMP信息然后发送给局域⽹中的客⼾端,并伪装⾃⼰是⼀个更好的路由通路。从⽽导致⽬标所有的上⽹流量都会发送到我们指定的接⼝上,达到和ARP欺骗同样的效果。
- 钓鱼wifi&&假⽹站等。