建设优质网站需要什么下载班级优化大师
文章目录
- 🌈 Ⅰ 基本概念
- 🌈 Ⅱ 基本操作
- 1. 进入 / 退出 vim
- 2. vim 模式切换
- 🌈 Ⅲ 命令模式
- 1. 光标的移动
- 2. 复制与粘贴
- 3. 剪切与删除
- 4. 撤销与恢复
- 🌈 Ⅳ 底行模式
- 1. 保存文件
- 2. 查找字符
- 3. 退出文件
- 4. 替换内容
- 5. 显示行号
- 6. 外部命令
- 7. 多文件操作
- 🌈 Ⅴ 异常退出
🌈 Ⅰ 基本概念
- vim 是一种 Linux 专门用来编写代码的多模式文本编辑器工具。
- vim 分别有命令、插入、底行三种模式,其功能区分如下:
1.命令模式
- 也称为 [ 普通模式 ] 或 [ 正常模式 ]。
- 不能直接对文件进行编辑,只能通过快捷键进行对文本的编辑控制。
2. 插入模式
- 在该模式下才可以对文本进行编辑,也就是俗称的编辑模式。
3. 底行模式
- 对文件的保存或退出,也能用来进行文件替换,找字符串,列出行号等操作。
- 在命令模式下,按下 shift + ; (也就是冒号 : ) 即可进入该模式。
🌈 Ⅱ 基本操作
1. 进入 / 退出 vim
进入 vim
- 输入 vim + 文件名后就会进入对该文件的编辑界面。
- 在进入 vim 之后,默认处于 [ 命令模式 ],切换到 [ 插入模式 ] 才能编辑该文本。

退出 vim
在 [ 底行模式 ] 下输入下列指令,就能以不同的方式退出 vim。
- q:未修改文件时,直接退出。
- q!:修改过文件时,不进行保存,强制退出。
- wq:修改过文件时,保存对文件的编辑然后退出。
2. vim 模式切换
- 注意:[ 插入模式 ] 与 [ 底行模式 ] 无法直接进行切换,需要借助 [ 命令模式 ] 进行中转。
1. 切换至命令模式
- 进入 vim 时,默认处于 [ 命令模式 ]。
- 如果处在 [ 插入模式 ] 或者 [ 底行模式 ] 时,直接按下 ESC即可。
2. 切换至插入模式
- 在 [ 命令模式 ] 下,直接按下以下指令就能以不同的形式进入 [ 插入模式 ] 。
| 选项 | 说明 |
|---|---|
| i | 在光标所在字符的前面开始插入 |
| a | 在光标所在字符的后面开始插入 |
| o | 在光标所在行的下一行开始插入 |
| l | 在光标所在行的头部开始插入,若头部有空格则在空格后插入 |
| A | 在光标所在行的末尾开始插入 |
| O | 在光标所在行的上一行开始插入 |
| S | 删除光标所在行并开始插入 |
3. 切换至底行模式
- 在英文输入法的前提下输入shift + 分号 ; 就是输入冒号 : 而已。
🌈 Ⅲ 命令模式
- 以下操作都是在 [ 命令模式 ] 下使用快捷键进行的。
1. 光标的移动
- 现有一个光标处在如下位置的文件,可以在命令模式下执行对应指令移动光标。
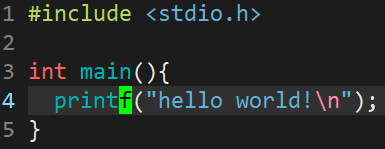
移动光标指令
- h:将光标向左移动
- j:将光标向下移动
- k:将光标向上移动
- l:将光标向右移动
- w:以单词为单位进行光标后移
- b:以单词为单位进行光标前移
- ^:将光标移动到光标所在行的开头
- $:将光标移动到光标所在行的结尾
- gg:将光标移动到当前文件的首行
- G:将光标移动到当前文件的尾行
- ctrl + b:向上翻屏,前提是文件内容够多
- ctrl + f:向下翻屏。前提是文件内容够多
- 数字 + G:将光标移动到指定行
2. 复制与粘贴
复制
- 复制单行:yy,复制当前光标所在行
- 复制多行:数字 + yy,从光标指定行开始向下复制指定行数。
粘贴
- 粘贴单次:p,从光标当前所处位置的下一行开始粘贴。
- 粘贴多次:数字 + p,将复制的内容粘贴指定次。
示例:使用 2 + yy 从第五行开始向下复制两行,然后使用 3 + p,将复制的内容粘贴三遍在第六行的下一行。

3. 剪切与删除
剪切
- 剪切单行:
- dd,剪切光标所在行,同时将下一行上移填补被剪切的空缺。
- d,只剪切光标所在行,但后面内容不会上移。
- 剪切多行:数字 + dd,从光标所在行向下剪切指定行,后面行会上移。
删除
- 删除整行:剪切之后不粘贴自然就是删除了。
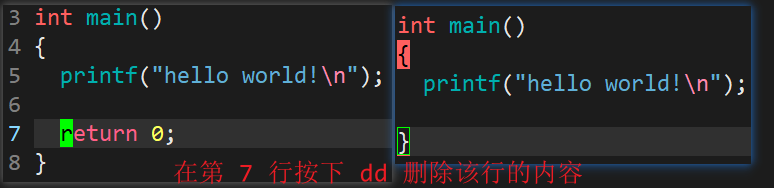
- 行内往后局部删除
- x:删除光标后面的一个字符。
- 数字 + x:在一行内,删除从光标处开始往后的 n 个字符。
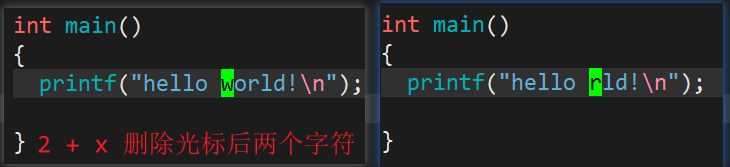
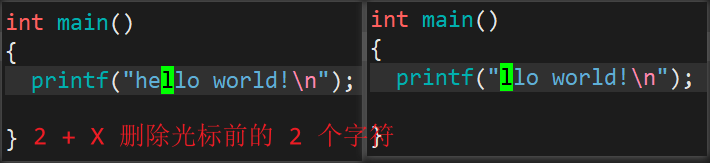
- 行内往前局部删除
- X:删除光标前面的一个字符。
- 数字 + X:在一行内,删除光标前的 n 个字符。
4. 撤销与恢复
撤销
- u:撤销上一步执行的操作,类似于 Windows 的 ctrl + z
恢复
- ctrl + r:取消之前执行的撤销操作,类似于 Windows 的 ctrl + y
🌈 Ⅳ 底行模式
- 注意:在执行下面的操作前需要先输入英文的冒号 : 进入底行模式。
1. 保存文件
- w:保存当前文件。
- w 文件路径:另存为指定文件。
2. 查找字符
- /关键字:往后查找第一个匹配的关键字。
- ?关键字:往前查找第一个匹配的关键字。
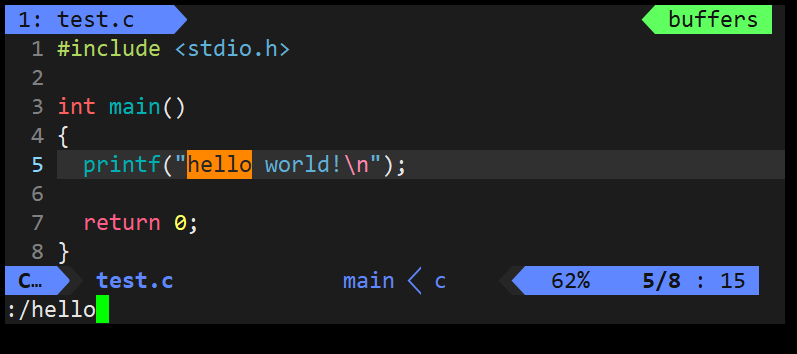
3. 退出文件
- q:若未对文件进行修改,可直接使用 q 退出文件。
- q!:若已对文件进行修改,不保存并且强制退出文件。
- wq:保存并退出当前文件
4. 替换内容
现有一份初始内容如下的文件:
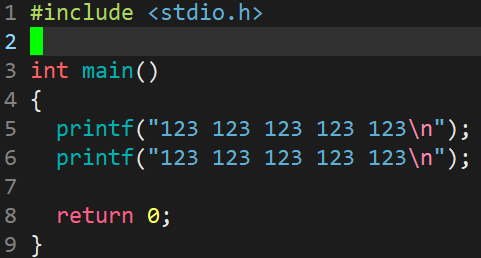
- s/搜索的内容/指定内容:用指定内容替换光标所在行 第一个 被搜索到的内容。
- s/搜索的内容/指定内容/g:用指定内容替换 光标所在行 全部被搜多到的内容。
- %s/搜索的内容/指定内容:用指定内容替换 整个文件 每一行第一个被搜索到的内容。
- %s/搜索的内容/指定内容/g:用指定内容替换整个文件 全部 被搜索到的内容。
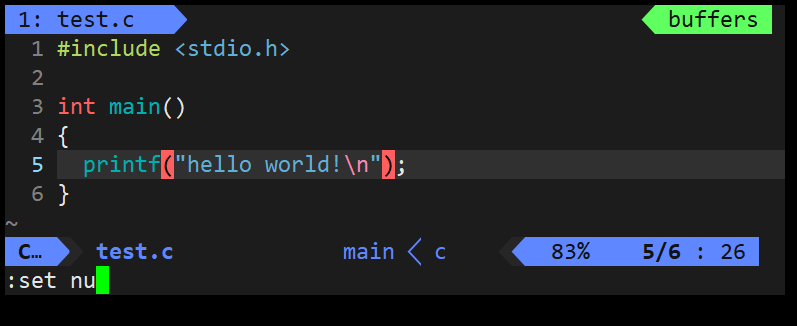
5. 显示行号
- set nu:显示的行号是暂时的,下次再打开该文件时不会显示。
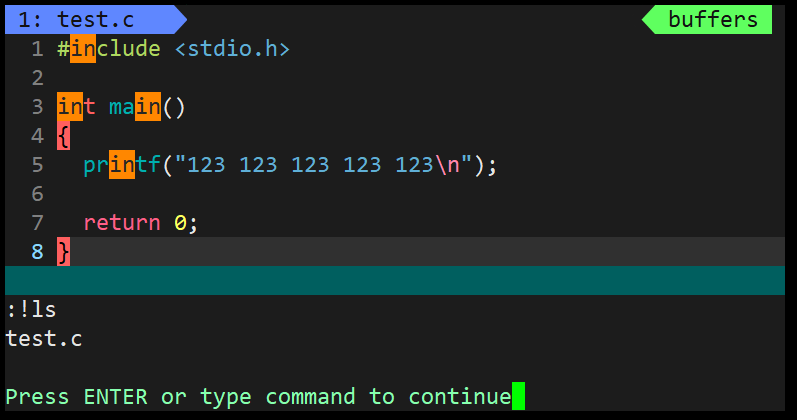
6. 外部命令
- 可以不用退出 vim 在命令行执行基本操作指令。
- 在 vim 界面的底行模式可以使用 ! 指令 的方式调用外部命令。
7. 多文件操作
- 在当前文件工作时,vim 不能像 vs 那样直接切换到其他文件进行操作 。
- 此时可以使用 vs 文件名,分屏打开其他文件进行操作。
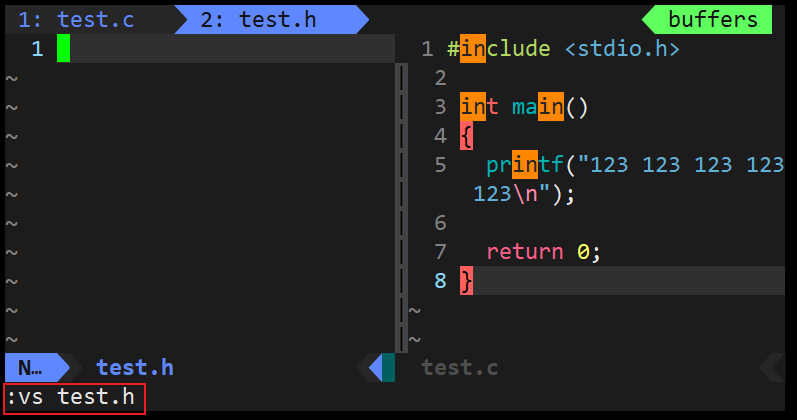
- 分频模式下如何编辑文件:光标在哪个文件就是对哪个文件进行操作。
- 切换光标 (切换操作文件):ctrl + ww
🌈 Ⅴ 异常退出
- 编辑中的文件未保存直接退出就是异常退出。
- 见的最多的异常退出就是在命令模式下不小心 ctrl + z 之后,之后再打开文件就会出现以下情况。
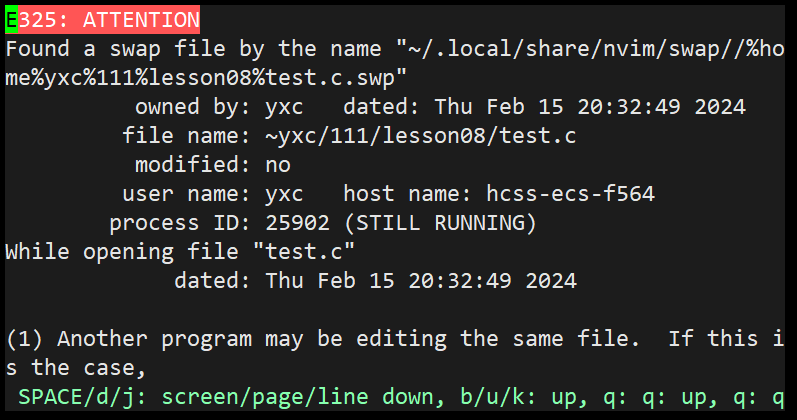
1. 临时解决
- 按下 q 之后出现以下信息,输入 E 或者 R 就能进入文件,但是之后还是会出现该提示。

2. 永久解决
- 异常退出只是将 vim 暂停,此时 vim 变成了一个后端任务,并没有真的退出。一个 Linux 文件只能被一个程序打开。
- 在异常退出 vim 时,vim 会自动在当前目录下生成一个隐藏的==.swp 临时文件==方便恢复数据。
- 这个临时文件会一直占着 vim,只要删除该临时文件即可。
隐藏文件的名字已经在提示时给出了。
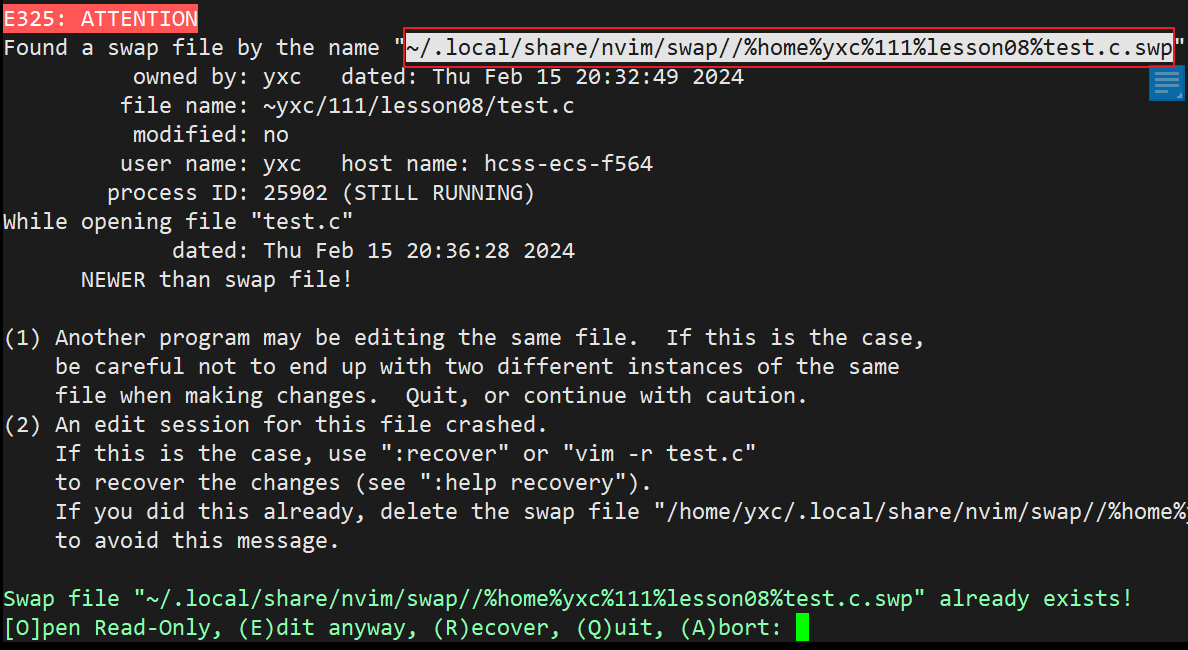
- 知道了隐藏文件的名字之后只需要使用 rm 指令删除该文件即可。
