快照推广seo搜索优化邵阳
现在许多项目都使用jwt来实现用户登录和数据权限,校验过用户的用户名和密码后,会向用户响应一段经过加密的token,在这段token中可能储存了数据权限等,在后期的访问中,需要携带这段token,后台解析这段token才允许用户访问接口。
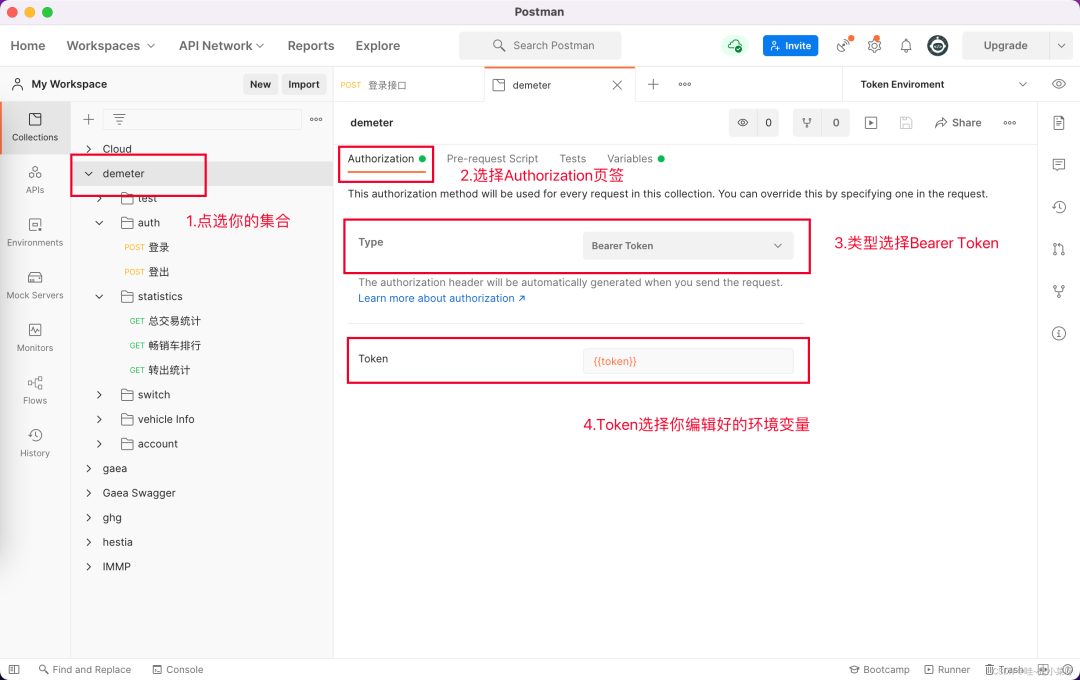
01、设置Bearer Token
如果后端项目使用的是Bearer Token进行安全认证,那么使用Postman这样操作。
设置你的环境变量
点击右上角的小眼睛,然后点击Add,添加
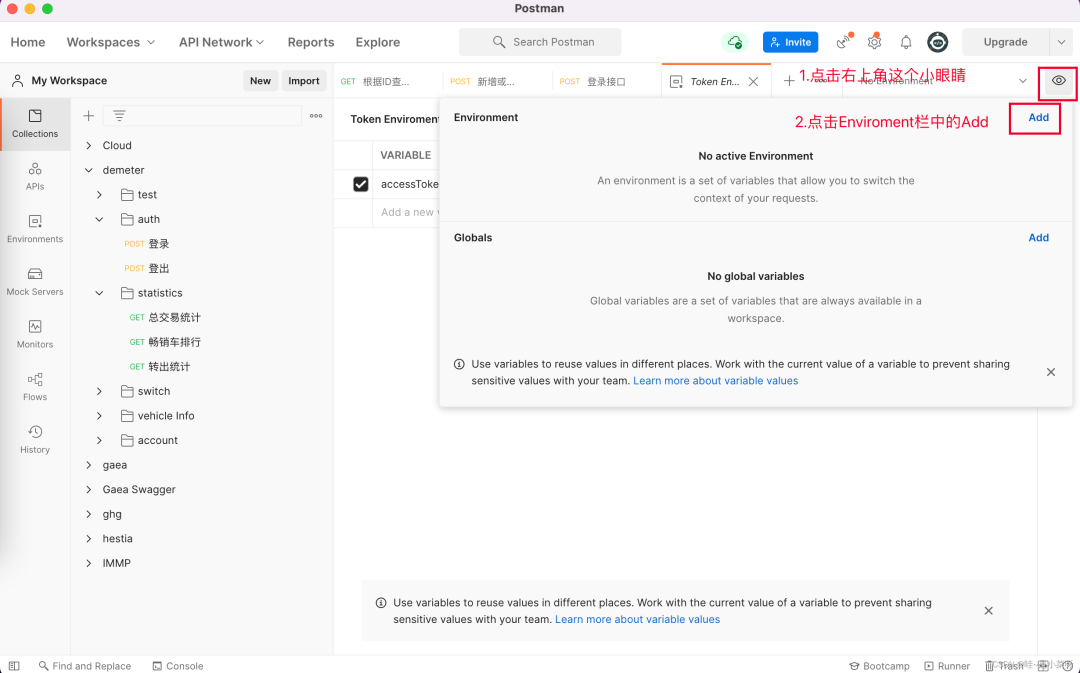
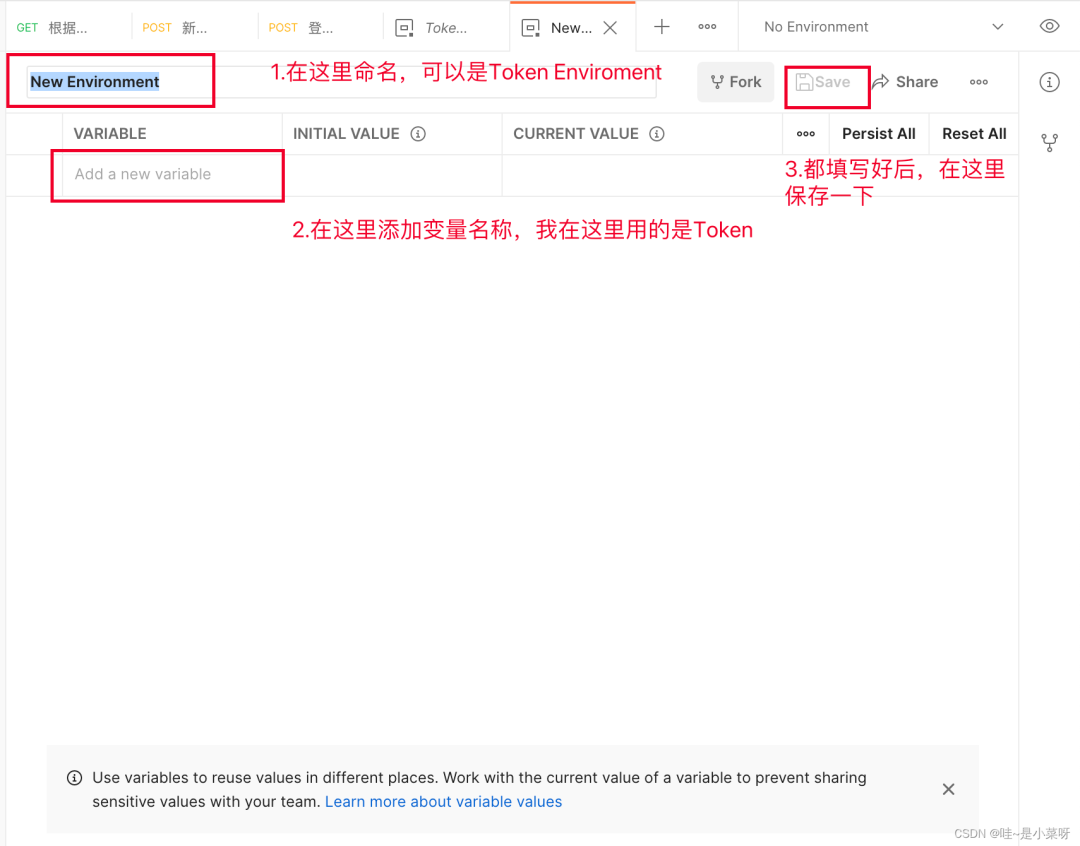
填写你的环境名和你的变量名
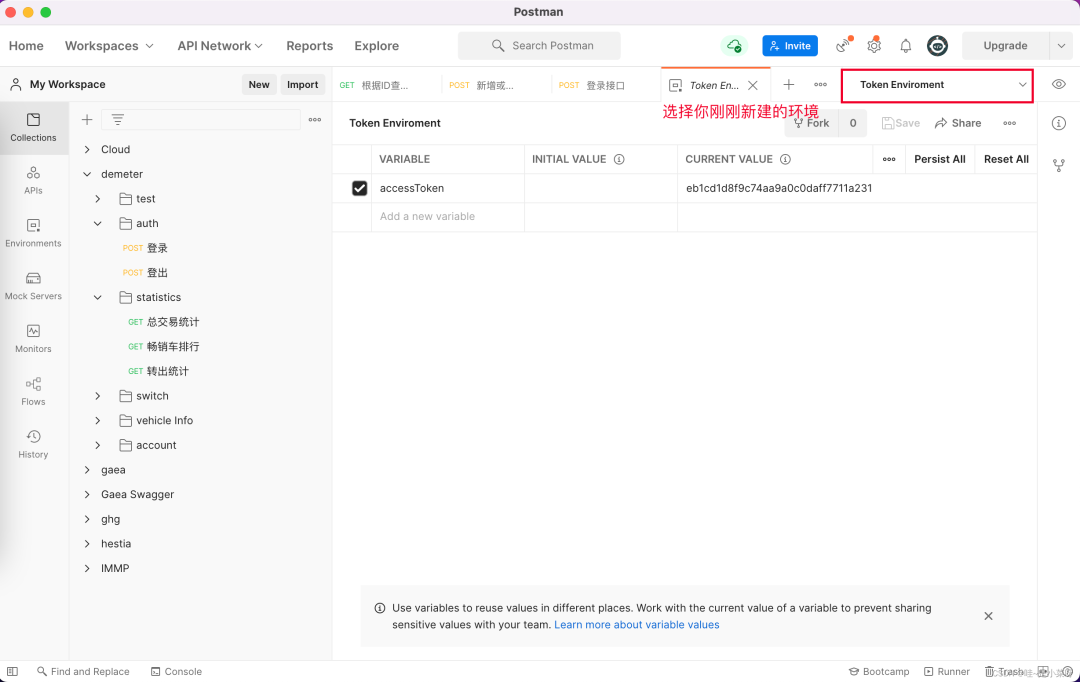
选择你新建的环境
项目集合设置认证方式及环境变量
登录接口的脚本
这个脚本的意思就是说,你的用户名和密码正确的前提下,访问后端接口会给你返回一个Token,你将这个Token储存在刚刚设置好的环境变量中,当你用别的接口访问时,由于整个项目刚刚已经设置好了访问权限使用的Token,所以你所有的接口都会携带这个token去访问,从而数据权限被后台接收和使用
// pm代表的就是postman,使用js编写脚本即可const responseJson = pm.response.json();console.log('-----------',responseJson)const accesssToken = responseJson.resultif('200'==responseJson.code){pm.environment.set('accessToken',accesssToken)}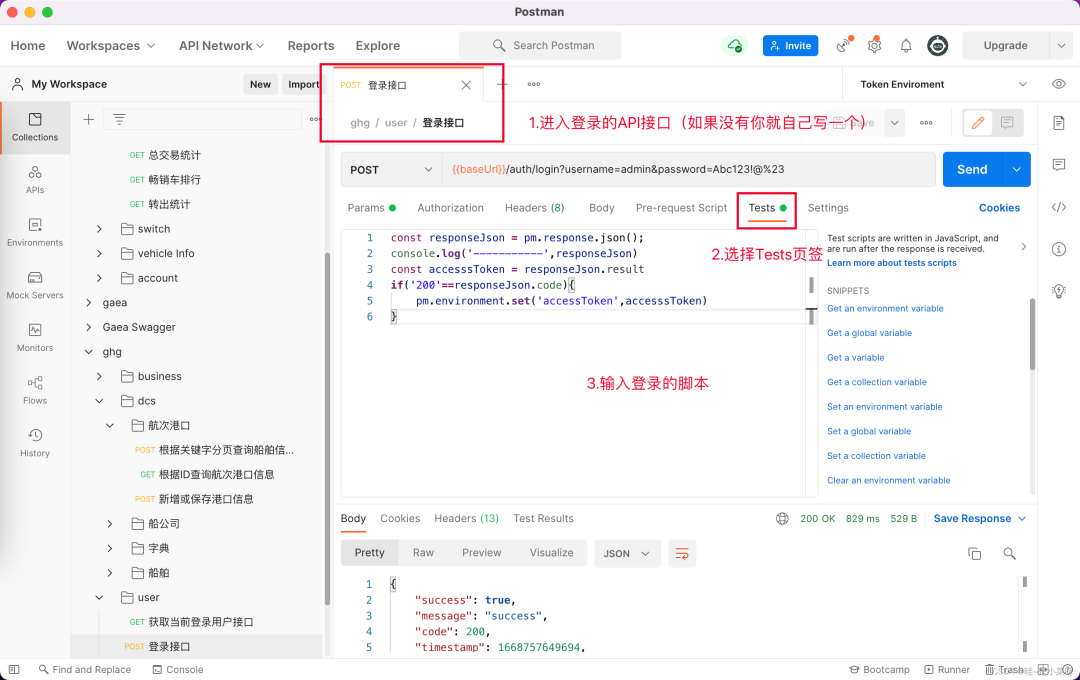
02、通过脚本设置Headers
Spring Security的在访问时会向请求头添加一个accessToken,可以使用脚本在集合批量添加,也可以对每一个Api手动添加Header,不过那样会很麻烦,所以我这边用脚本批量添加的方便方式。
登录请求设置环境变量
从登录结果获取accessToken,将accessToken设置到环境变量中
脚本如下
const responseJson = pm.response.json();console.log('-----------',responseJson)const accesssToken = responseJson.resultif('200'==responseJson.code){pm.environment.set('accessToken',accesssToken)}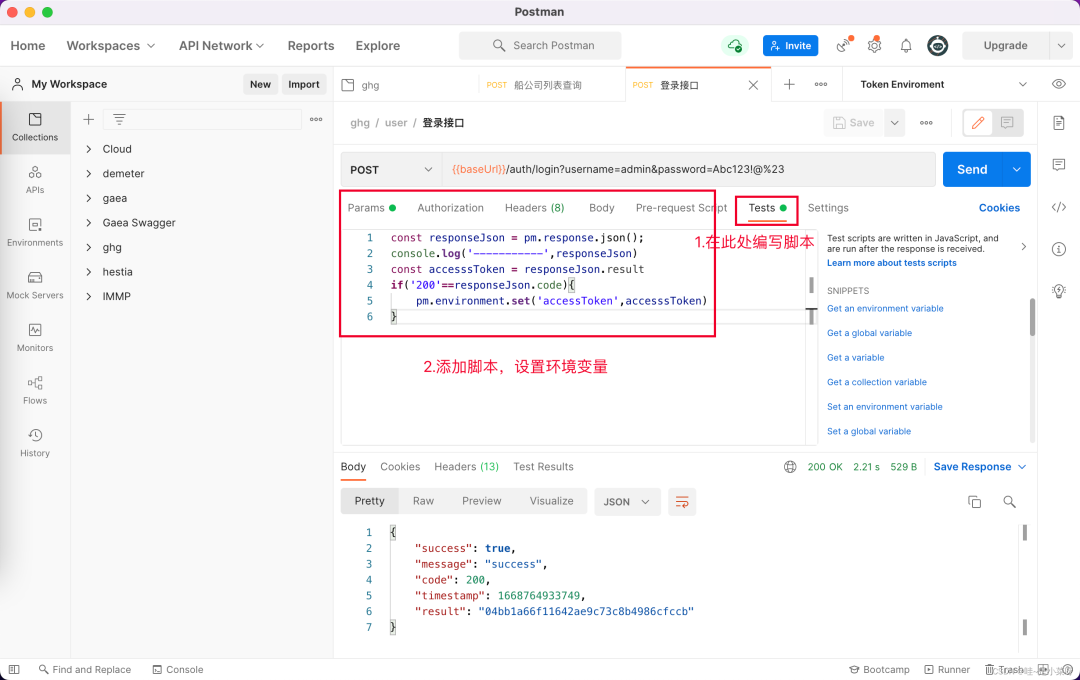
设置集合的发送请求脚本
点选集合->进入Pre-request Scrip(请求前脚本)页签->编写脚本
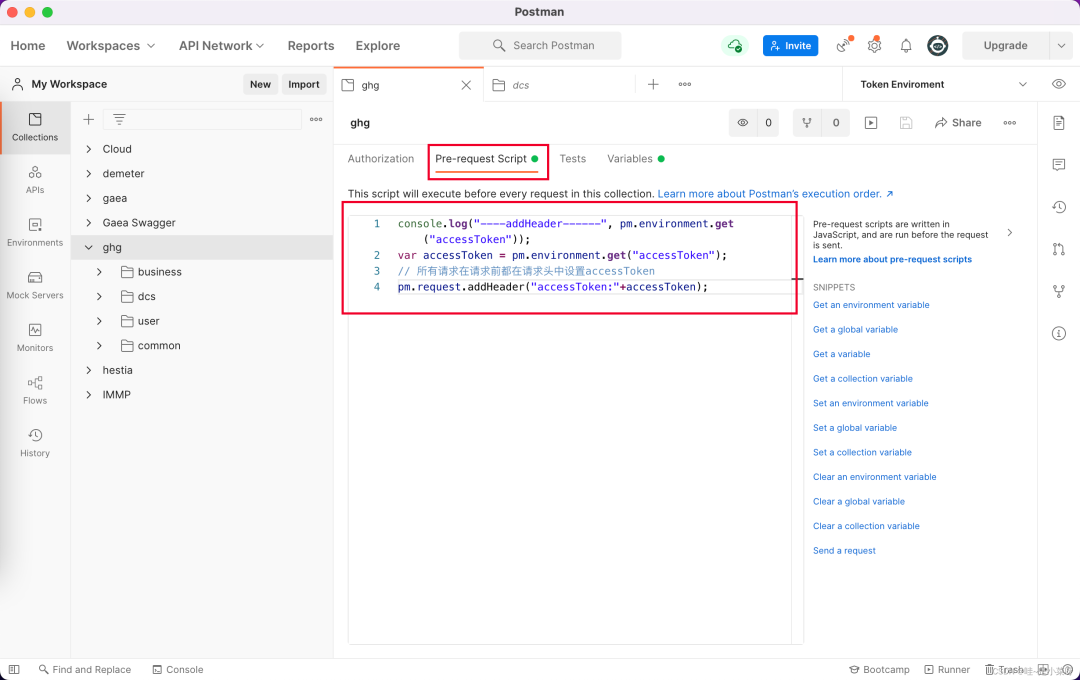
脚本如下
console.log("----addHeader------", pm.environment.get("accessToken"));var accessToken = pm.environment.get("accessToken");// 所有请求在请求前都在请求头中设置accessTokenpm.request.addHeader("accessToken:"+accessToken);这样设置后,所有的请求都会携带登录的accessToken了。
登录接口抹除accessToken
因为我们项目的过滤器没有设置解析accessToken的脏数据,所以一旦有老的token,就会报错超时,所以登录接口在访问时一定要抹除accessToken,登录接口的Pre-request设置脚本如下:
// 移除登录接口的accessToken, 防止过期的token被过滤器解析,影响登录接口pm.request.headers.remove("accessToken")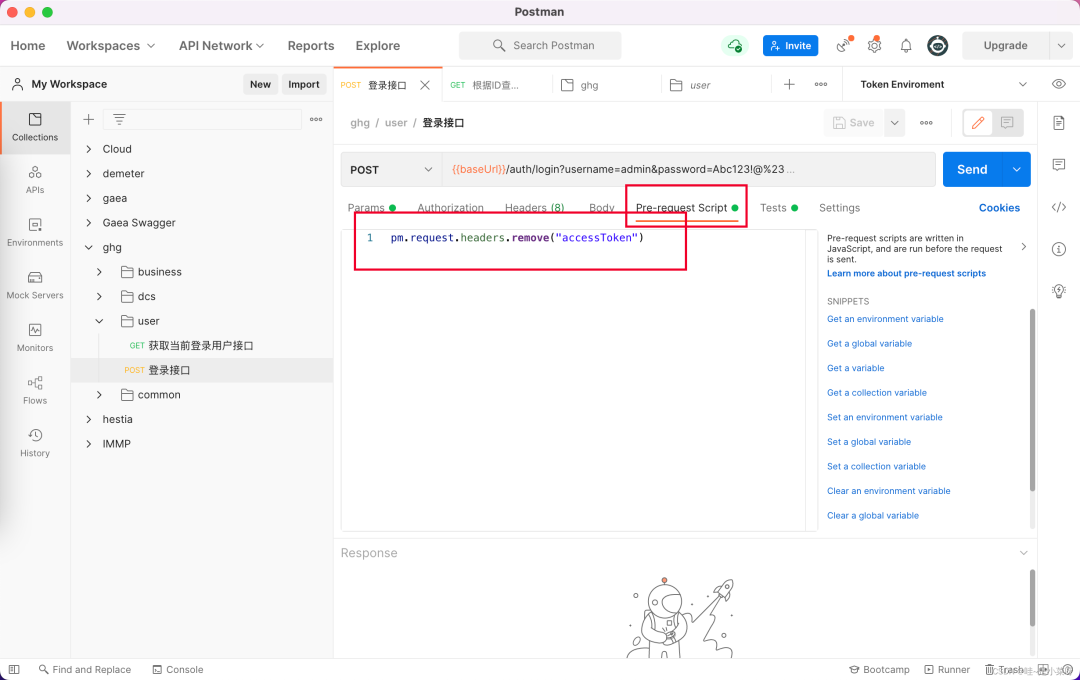
最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走!
软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。