想要给网站投稿如何做seo长尾关键词排名
机器人已经在我们中间存在了二三十年。如今,机器人在我们的文化中比以往任何时候都更加根深蒂固。大多数机器人机器用于各种装配线,或在世界各地的矿山或工业设施中执行密集的物理操作。
还有一些家用机器人,工程师正在对机器人进行编程,以清洁您的房屋或执行其他家政职责。截至目前,机器人编程能够生产出执行相对简单的日常任务的机器人。对自己的机器人进行编程存在特定的挑战,因为家庭或办公室使用的完全可操作的机器人需要六个自由度(6DoF)才能在现实世界的三维空间中操作。
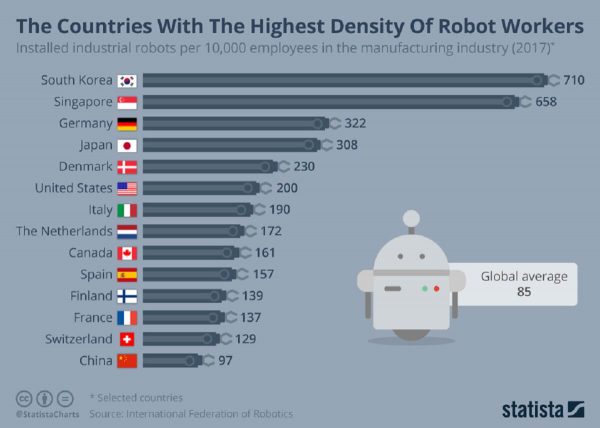
摄影:Statista(斯塔蒂斯塔)
话虽如此,您学习机器人编程的旅程应该从 6DoF 开始。这包括向前和向后移动、向上和向下移动、向左和向右转动的机器人功能。它还应该能够围绕三个垂直轴旋转,称为俯仰、偏航和滚动。
学习如何对能够执行所有这些动作并仅依靠来自有限数量传感器的信息进行操作的机器人进行编程并不容易。我们的机器人初学者指南将为您提供在对第一个机器人进行编程时应该开始的基础知识。
机器人简介:如何对机器人进行编程
让我们从我们的机器人教程开始,声明您对机器人作为智能机器的理解是错误的。首先,机器人很可能只是一个在现实世界中没有物理存在的软件。Java机器人编程用于制造在不同硬件(如计算机,平板电脑和智能手机)上运行的外汇交易机器人。这些外汇交易机器人都没有物理身体;这些只是编程为根据设定规则交易货币的算法。

Pixabay上的照片
我们也有自主机器人和只需要有限或不需要自主权即可操作的机器人。当您拥有一台自动机器和另一台在工业环境中执行有限数量的重复操作时,机器人编码是不同的。一个很好的例子是在装配线上焊接汽车部件的机器人。
机器人编程的问题取决于你需要设计什么。自主机器人可能需要某些机器学习功能或某种程度的人工智能,因此与编程为执行选定数量的功能的机器人相比,您可能必须使用不同的编程语言。
机器人编程的编码语言
关于如何对机器人进行编程以及哪种编程语言是机器人编程的最佳语言,争论仍在继续。实际上,这始终取决于您的最终目标,如果您知道自己想要什么以及如何实现它,任何语言都可以满足要求。
人们普遍认为,机器人编程应该主要依赖于C/C++和Python等语言。C 和 C++ 是机器人初学者开始使用的语言,但如果你想成为一名优秀的机器人计算机科学家,你不能只坚持这两种语言。

Pexels 上的照片
机器人编码还涉及机器人设备制造商的多种工业机器人语言。学习Pascal是一个很好的起点。该软件处理其中一些专有的机器人编程语言。但是您仍然需要详细学习它们中的每一个。
MATLAB 是您在研究如何对机器人进行编程时需要掌握的另一个工具。机器人编程涉及大量的数学和数据分析。如果要让机器人按预期工作,您需要适当的方法来处理数据并从硬件和软件传感器获得可靠的结果。
一旦你掌握了使用C / C++,Python,Java或机器人中使用的其他语言进行编程的一些知识,就该对你的第一个机器人进行编程了。我们建议从软件机器人开始,因为编写执行与物理设备控制无关的功能的程序代码要容易得多。
初学者机器人编程
图像识别和最近的自然语言处理是机器人科学家必须解决的核心问题之一,以便设计模仿人类行为的机器人。因此,让我们从一个简单的算法开始我们的机器人编程教程,通过引入一个使用连接的摄像头识别人脸的机器人来保护您的家庭或办公室。
你如何编程这样的软件机器人?只需执行以下步骤:
- 在前门安装运动传感器并将其连接到摄像头。
- 指示运动传感器在有人在门口时激活摄像头。
- 相机拍摄人脸图像作为输入。
- 扫描图像以查找一组特定的功能。
- 将这些功能与已知人脸库进行比较。
- 如果找到匹配项,请指示打开门。
- 如果没有匹配项,请继续执行另一种操作。
您将使用哪种编程语言对软件进行编程以执行这组命令并不重要。一旦触发条件到位(即有人激活您前门的运动传感器),您的第一个机器人编程算法将一遍又一遍地执行上述步骤。

Pixabay上的照片
这是一个使用可编程硬件的简单机器人。在这种情况下,硬件包括一个运动传感器、一个摄像头和一台计算机,该计算机将保存已知人脸所在的数据库。计算机特别需要执行解锁门的非常简单的动作。
您只能用 100 行代码编写此程序。但是,这只有在您拥有处理面部识别过程的现成软件模型时才有可能。事实上,编写面部识别编程代码的技能是使软件程序员成为高级编码人员的原因。
关于如何对机器人进行编程的进一步讨论
既然您已经认出了您的第一位访客并让他们进来,您可以决定放置一个机械臂,将访客的外套放在衣柜中。
幻灯片共享上的照片
您需要的是控制涉及传感器和机械臂的动态系统。手臂应该做的是识别外套到位,得到它,然后把它放在某个地方。你是怎么做到的?您的机械臂编程将涉及以下步骤:
- 控制信号的应用。
- 结果测量。
- 生成新的控制信号,使您的手臂更接近我们的目标。
如果您希望机器人获得外套并将其存储给您的客人,该过程涉及大量的数学和源源不断的可靠数据流。它是关于实时处理传感器数据,然后应用基本的逻辑运算符“if”和“then”来控制你的机械臂。如果我们进一步简化它,您可以执行诸如“如果太左,则向右移动”和“如果太低,则向上移动”之类的编程。这就是机器人编码的工作方式。
关于如何对机器人进行编程的最终想法
机器人技术发展非常迅速。跟上可编程机器领域的最新发展需要的努力,而不仅仅是熟悉一种或另一种适合编程机器人的语言。
如果你真的想掌握如何对机器人进行编程,你需要在硬件和软件层面了解机器人的要求和能力。值得庆幸的是,许多平台为初学者提供了机器人编程。这是通过消除与了解硬件如何运行相关的许多困难来完成的。它也可以通过在零和一级别对系统进行编程来完成。
对于初学者来说,机器人技术基本上需要的是拥有可编程的硬件或预编程的软件模块。之后,您可以编程以执行某些操作。在任何情况下,您都需要学习一种或多种编程语言,例如C / C++,Python,LISP或Java,以使最简单的软件/硬件机器人工作。当您进一步前进时,建议您熟悉 MATLAB 等工具。这可确保您完全指挥和控制您的机器人。