酒泉网站建设怎么提交网址让百度收录
目录
七、生产烧录固件(jflash擦/写/读外挂flash)
7.1 flash母片读写
7.2 jflash擦/写/读外挂flash
九、从0开始卷出一个新项目之瑞萨RZN2L 七、生产烧录固件(jflash擦写读外挂flash)
七、生产烧录固件(jflash擦/写/读外挂flash)
7.1 flash母片读写
略
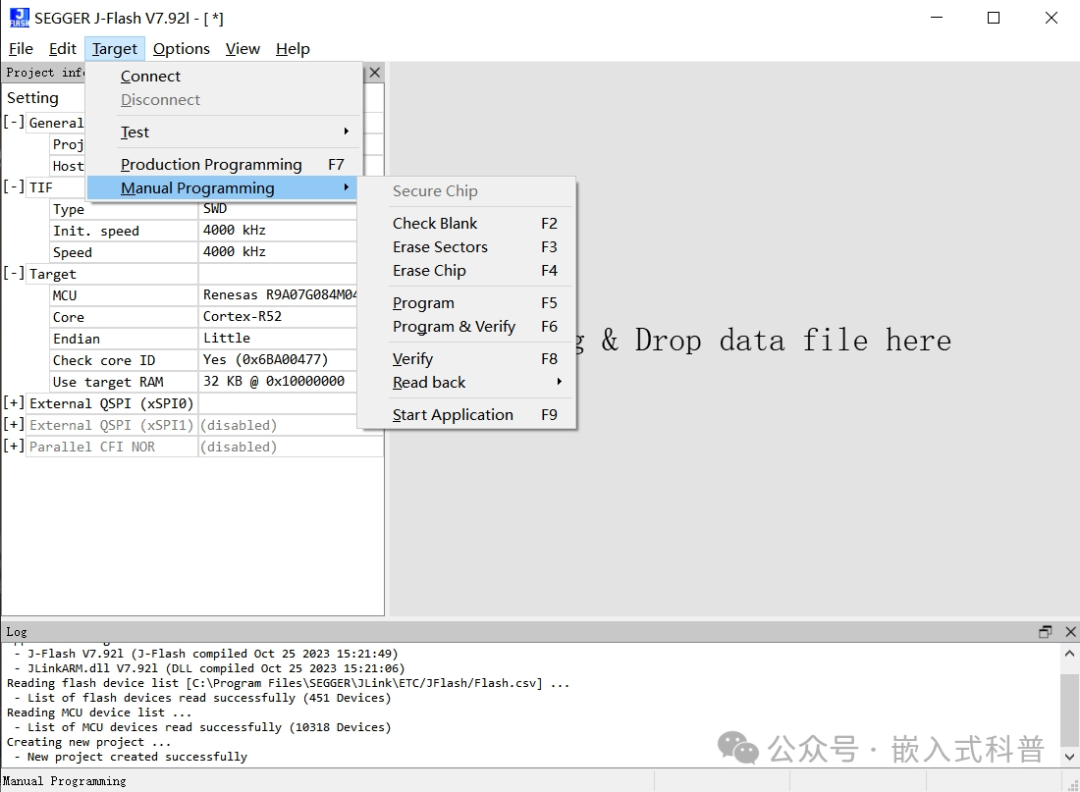
7.2 jflash擦/写/读外挂flash
-
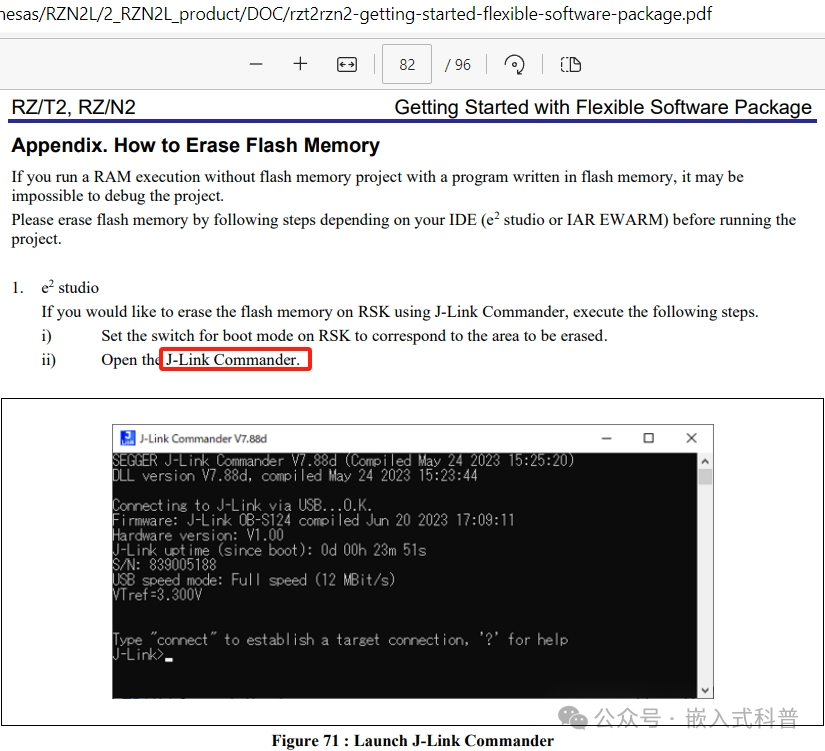
rzt2rzn2-getting-started-flexible-software-package.pdf只指导使用J-Link Commander擦除flash,并没有提到写/读。
-
Device Setup Guide for Flash boot讲解了芯片引导的原理,个人感觉无需这么复杂。
-
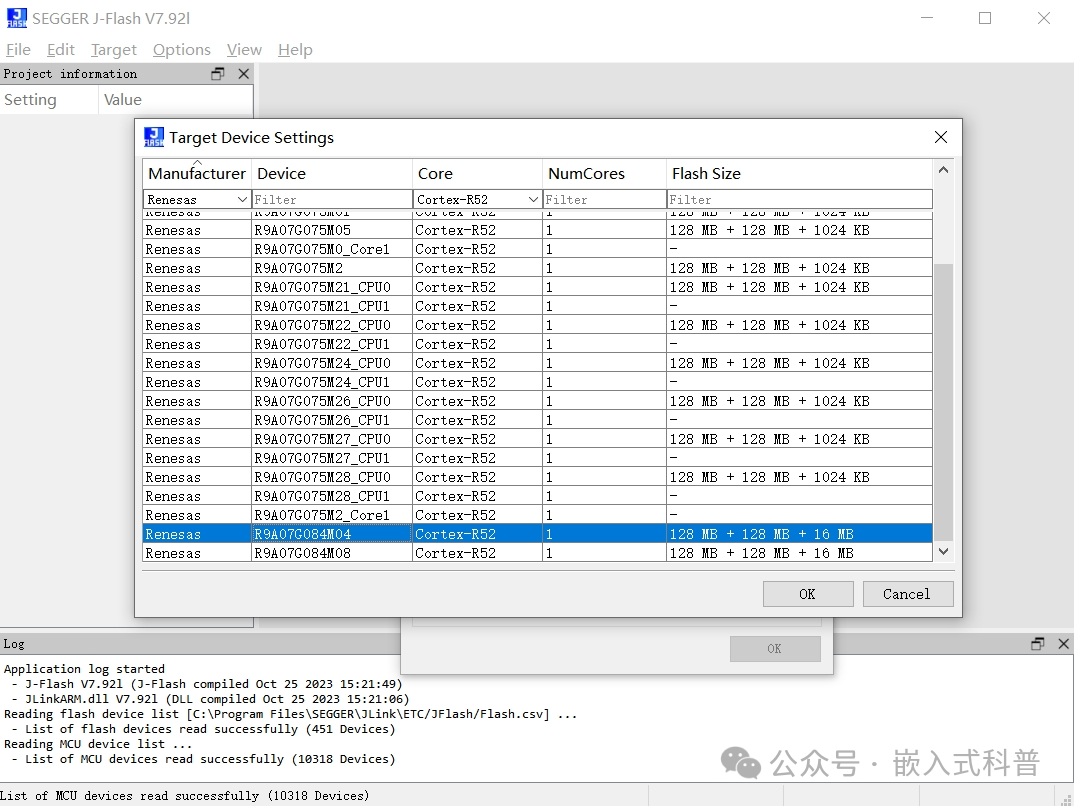
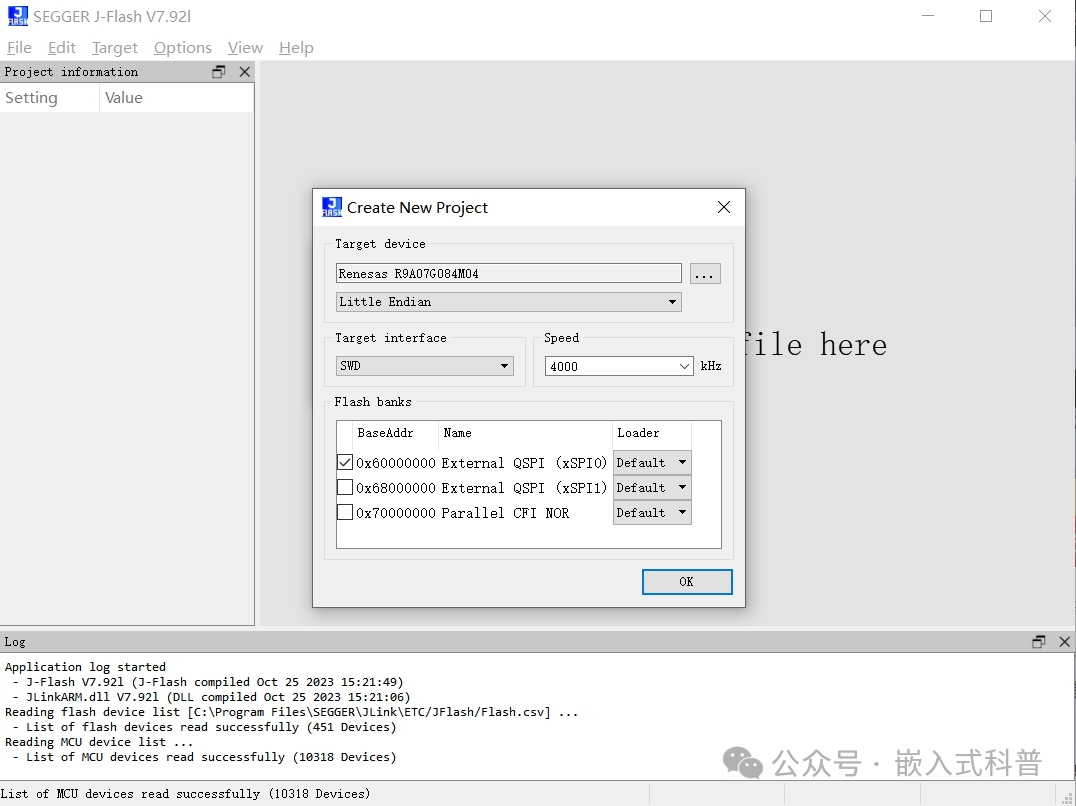
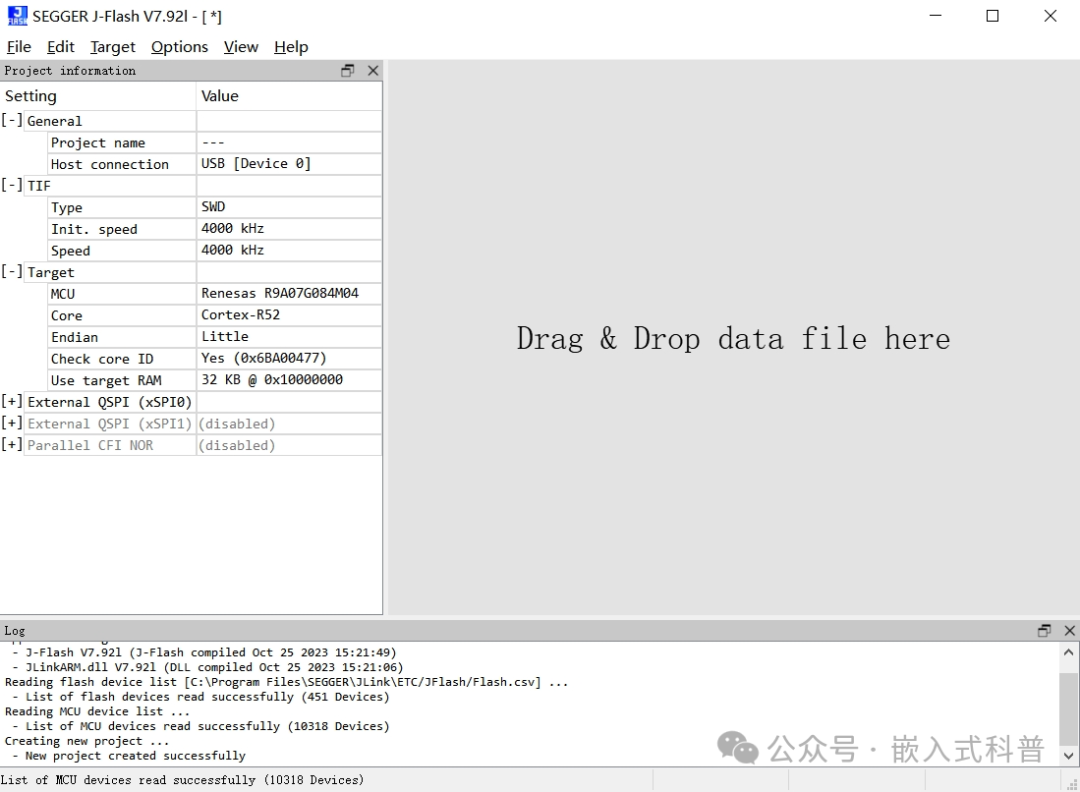
直接使用segger J-Flash擦/写/读外挂flash
-
J-Flash高本部需要激活,J-Flash Lite免费但不好用