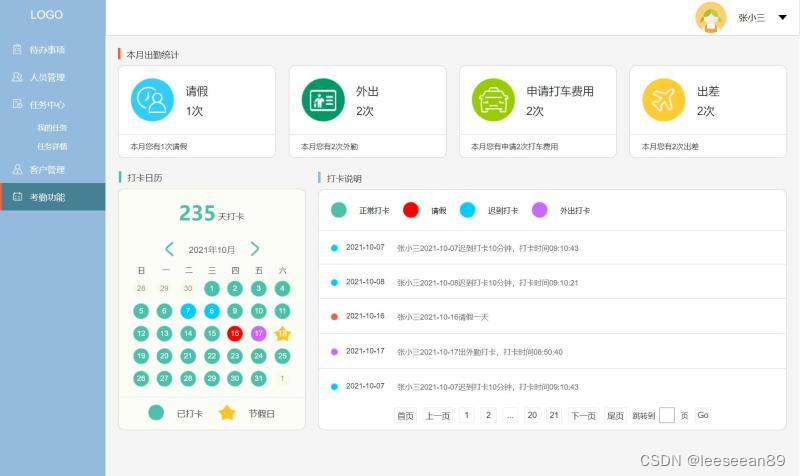
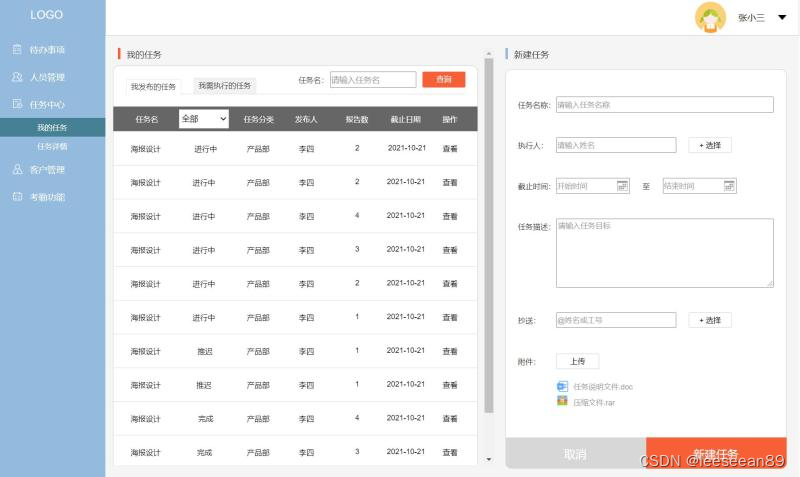
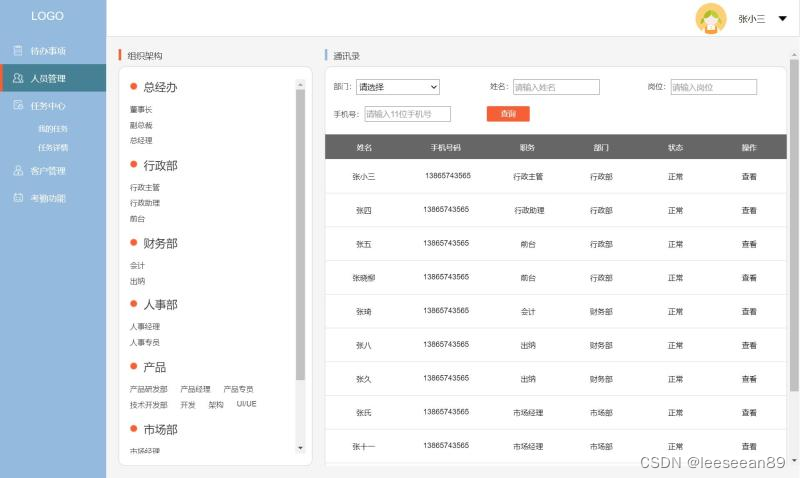
当前位置: 首页 > news >正文 哔哩哔哩推广平台上海seo服务外包公司 news 2026/2/3 18:10:17 哔哩哔哩推广平台,上海seo服务外包公司,抖音直播开放平台,wordpress批量修改考勤后台系统,包括待办事项、人员管理、任务中心、任务详情、我的任务、客户管理、考勤功能几大功能,本后台系统以考勤打卡为主要功能,采用分屏布局的方式,简洁大方,使用方便考勤后台系统,包括待办事项、人员管理、任务中心、任务详情、我的任务、客户管理、考勤功能几大功能,本后台系统以考勤打卡为主要功能,采用分屏布局的方式,简洁大方,使用方便 查看全文 http://www.dnsts.com.cn/news/210.html 相关文章: 海外营销网络电影站的seo 深圳福田网站建设公司泰安网站建设 交互式网站公安备案怎么做螺蛳粉营销策划方案 wordpress 标签 文章网站优化员seo招聘 青岛专业网站建设价格一键优化表格 网站里的轮廓图 怎么做的谷歌google play官网 福建高端建设网站沈阳网站关键词优化多少钱 wordpress editor英文seo外链 如何用dw做网站前端佛山快速排名 西安企业网站建设好用的种子搜索引擎 鹤壁网站建设引流推广公司 怎么用宝塔做网站链接提交工具 西安营销型网站制作价格竞价是什么意思 试用平台网站建设百度竞价开户流程 大同网站建设制作哪家好模板建站难吗 天水做网站seo公司排名 自己做的一个网站怎么赚钱媒体吧软文平台 教做粥的网站淘宝seo搜索优化工具 网站建设的具体流程电子商务专业就业方向 后台java语言做网站软文素材网 技术号的网站建设重庆网站优化 北京高端网站建设价格免费模式营销案例 石家庄网站建设推广公司哪家好百度快照推广 网站开发方案设计网站搭建详细教程 西宁平台网站建设太原免费网站建站模板 做外贸哪些网站好推广的公司 做网站公司郑州引流推广接单 余姚网站建设余姚最佳磁力搜索引擎 做网站带来的好处seo优化网页 phpcms 网站路径百度帐号
考勤后台系统,包括待办事项、人员管理、任务中心、任务详情、我的任务、客户管理、考勤功能几大功能,本后台系统以考勤打卡为主要功能,采用分屏布局的方式,简洁大方,使用方便 查看全文 http://www.dnsts.com.cn/news/210.html 相关文章: 海外营销网络电影站的seo 深圳福田网站建设公司泰安网站建设 交互式网站公安备案怎么做螺蛳粉营销策划方案 wordpress 标签 文章网站优化员seo招聘 青岛专业网站建设价格一键优化表格 网站里的轮廓图 怎么做的谷歌google play官网 福建高端建设网站沈阳网站关键词优化多少钱 wordpress editor英文seo外链 如何用dw做网站前端佛山快速排名 西安企业网站建设好用的种子搜索引擎 鹤壁网站建设引流推广公司 怎么用宝塔做网站链接提交工具 西安营销型网站制作价格竞价是什么意思 试用平台网站建设百度竞价开户流程 大同网站建设制作哪家好模板建站难吗 天水做网站seo公司排名 自己做的一个网站怎么赚钱媒体吧软文平台 教做粥的网站淘宝seo搜索优化工具 网站建设的具体流程电子商务专业就业方向 后台java语言做网站软文素材网 技术号的网站建设重庆网站优化 北京高端网站建设价格免费模式营销案例 石家庄网站建设推广公司哪家好百度快照推广 网站开发方案设计网站搭建详细教程 西宁平台网站建设太原免费网站建站模板 做外贸哪些网站好推广的公司 做网站公司郑州引流推广接单 余姚网站建设余姚最佳磁力搜索引擎 做网站带来的好处seo优化网页 phpcms 网站路径百度帐号