静安网站开发百度小说风云榜
前言
那么这篇文章其实是我在使用Qt的过程当中呢,我发现在Qt使用过程中,在我理解信号和槽这个概念后,在编写槽函数数的时候,发现了自身存在的问题,我的难点是在于当我在编写槽函数的时候,我知道这个槽函数是用来干什么的,但是不知道用什么类,什么函数,因为在qt中的类有很多,每个类下面又有很多函数,导致我不知道该用什么类下面的函数。那么这个问题是通过阅读技术文档来帮助我快速找到这个类和函数,下面我将介绍一下方法。
一、需要知道部件的概念
在Qt编程当中,有很多个类,每个类前面都用到了Q作为标志,例如QPushButton这是一个按钮部件,同时也是一个类,按钮用到很多地方,当然,这个类当中有很成员函数,那么像这样的有很多,比如标签(QLabel),文本编辑器(QTextEdit),行编辑器(QLineEdit),对话框(QDialog),复选框(QChackBox)...等等,总之有很多,大家可以通过这个链接去看看All C++ Classes | Qt 6.7
那么在诸如这么多类当中怎么才能找到我需要的哪个呢,那么我们看下面这张图
我们点击帮助,选择索引

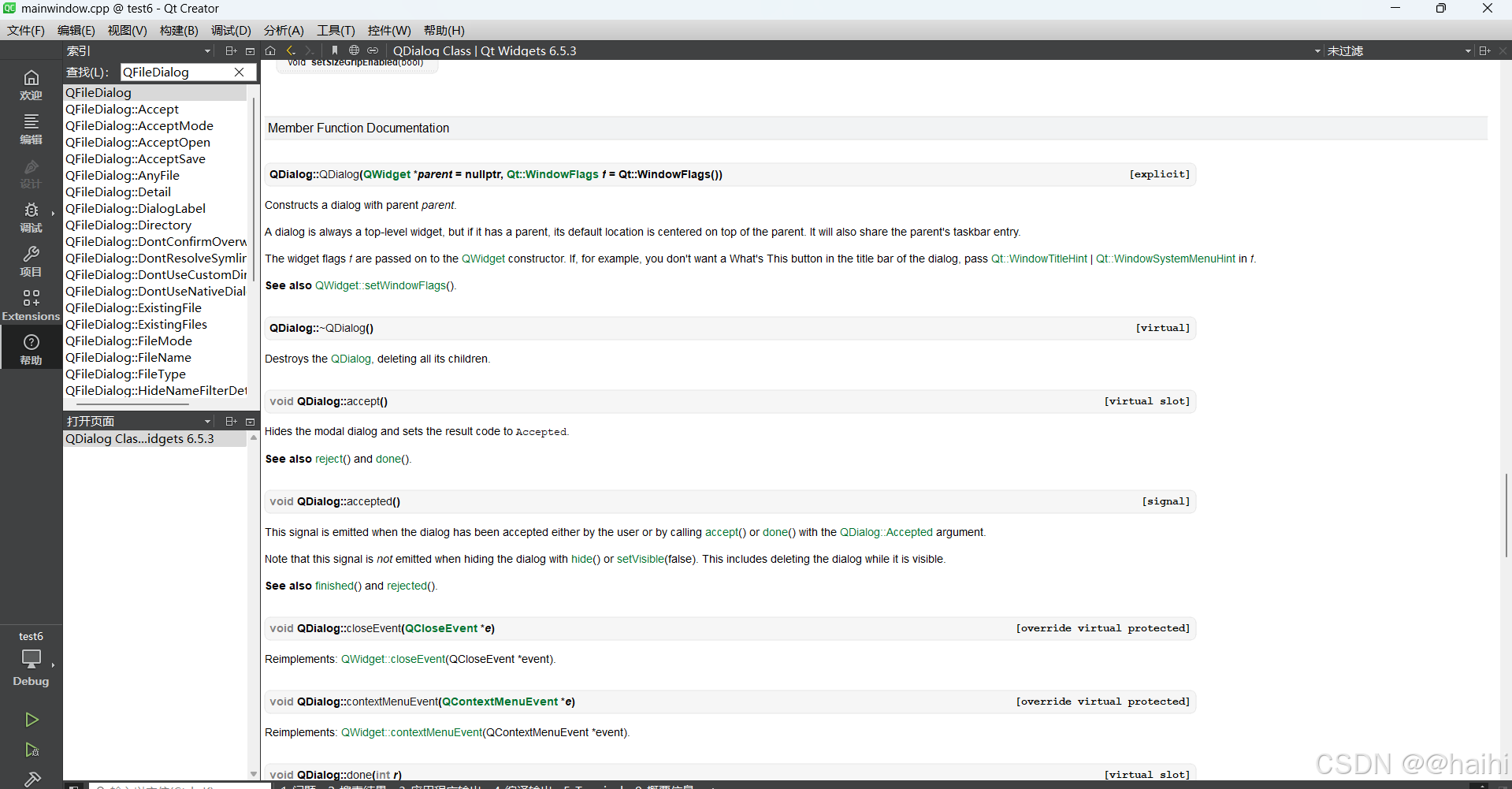
然后输入QFileDialog,
我们看看这个查找的类有什么特点,首先看file是文件的意思,Dialog是对话框,那么这个类其实就是一个文件对话框,那么在Qt的类当中,我们就根据这样的特点来找到需要什么部件就找相应的部件就可以了,像这种文本编辑器(QTextEdit),行编辑器(QLineEdit)也是同样的text是文本的意思,edit是编辑,组合一起不就是文本编辑器吗,一般对于新手而言,掌握基础的部件其实就可以了,要是按照这种方法记不住,应该就是英语基础太差,那么就只能死记硬背了。
那么下面我们怎么知道我们需要用到什么函数呢,那么这个问题对于刚开始接触Qt还有英语不好的同学来说,可能是一个无比巨大的问题,我能写照着别人的代码敲一次,但是过后又忘记了该用什么函数?这个问题其实我也有过同样的经历,这么多类,类下面又有这么多函数,肯定是记不住,背不完的,况且这么多类也不是一个人完成的,是一个世界级别的公司团队合作完成的,对于新手来说,我知道这个功能应该做什么,但是该用哪个函数来实现呢,其实最简单的方法就是查手册,用到哪个类就去查手册,不认识就去翻译。
二、基于任务划分使用常见的类
1. 界面控件操作
以下是常见的 Qt Widgets 类的详细列表,按照控件类型分类:
1. 基本控件(Buttons and Indicators)
- QPushButton:标准的按钮,用于响应用户点击事件。
- QRadioButton:单选按钮,允许用户从多个选项中选择一个。
- QCheckBox:复选框,允许用户选择或取消选择。
- QToolButton:工具按钮,类似于
QPushButton,但通常用于工具栏。- QCommandLinkButton:用于呈现命令的链接按钮,类似网页的超链接。
- QButtonGroup:按钮组,管理一组按钮的相互排斥关系(如单选按钮组)。
2. 输入控件(Input Widgets)
- QLineEdit:单行文本输入框。
- QTextEdit:多行文本编辑器,支持富文本和纯文本。
- QPlainTextEdit:多行纯文本编辑器,不支持富文本,但性能较
QTextEdit更好。- QComboBox:组合框,包含一个下拉菜单,允许用户从列表中选择一个选项。
- QSpinBox:用于显示和编辑整数的旋转框。
- QDoubleSpinBox:用于显示和编辑浮点数的旋转框。
- QSlider:滑块,用于选择数值范围内的某个值。
- QDial:旋钮,类似于滑块,但以圆形形式呈现。
- QDateEdit:日期选择编辑框,允许用户选择和编辑日期。
- QTimeEdit:时间选择编辑框,允许用户选择和编辑时间。
- QDateTimeEdit:日期和时间编辑框,结合日期和时间输入。
- QKeySequenceEdit:用于输入键盘快捷键的编辑框。
3. 显示控件(Display Widgets)
- QLabel:显示文本或图片的标签。
- QLCDNumber:用于显示数字的 LCD 风格显示器。
- QProgressBar:进度条,显示任务的进度。
- QStatusBar:状态栏,通常在主窗口底部用于显示状态信息。
- QFrame:框架,用于给界面添加视觉元素,比如边框和线条。
4. 容器控件(Container Widgets)
- QGroupBox:分组框,用于将多个控件分组。
- QTabWidget:选项卡控件,允许在多个选项卡之间切换内容。
- QStackedWidget:堆叠窗口部件,允许在多个窗口小部件之间切换(只显示一个)。
- QToolBox:工具箱控件,类似于选项卡,但垂直排列,每次显示一个工具面板。
- QScrollArea:滚动区域,允许包含超出可视范围的内容,并提供滚动条。
- QSplitter:分割器,允许用户通过拖动调整布局中控件的大小。
5. 列表和视图控件(Item Views and Models)
- QListWidget:用于显示列表项的控件,基于
QListView的便捷类。- QTreeWidget:用于显示树状结构的控件,基于
QTreeView的便捷类。- QTableWidget:用于显示二维表格数据的控件,基于
QTableView的便捷类。- QListView:列表视图,显示基于模型的数据。
- QTreeView:树视图,显示基于模型的分层数据。
- QTableView:表格视图,显示基于模型的二维数据。
- QColumnView:多列视图,显示分级数据,类似于文件管理器中的多列模式。
- QHeaderView:表格或树视图中的表头。
6. 菜单和工具栏(Menus and Toolbars)
- QMenuBar:菜单栏,通常用于主窗口,显示菜单项。
- QMenu:菜单,通常用于菜单栏或上下文菜单中,包含多个动作项。
- QToolBar:工具栏,通常放置在窗口顶部,用于放置常用的操作按钮。
- QAction:动作,用于在菜单或工具栏中执行命令。
7. 对话框控件(Dialogs)
- QDialog:基本对话框类,所有对话框都从此类派生。
- QMessageBox:消息框,用于显示信息或警告用户。
- QFileDialog:文件对话框,用于打开或保存文件。
- QColorDialog:颜色选择对话框,允许用户选择颜色。
- QFontDialog:字体选择对话框,允许用户选择字体。
- QInputDialog:输入对话框,允许用户输入简单的数据(如字符串或整数)。
8. 布局管理器(Layout Managers)
虽然布局管理器不是控件,但它们用于控制界面上控件的排列和大小调整。
- QHBoxLayout:水平布局,控件从左到右排列。
- QVBoxLayout:垂直布局,控件从上到下排列。
- QGridLayout:网格布局,控件按行和列排列。
- QFormLayout:表单布局,通常用于排列标签和输入控件对。
9. 特殊控件
- QCalendarWidget:日历控件,显示月份、日期等,允许用户选择日期。
- QDockWidget:可停靠的窗口部件,通常用于创建可浮动的工具窗口。
- QTextBrowser:超文本浏览器,支持显示 HTML 和富文本。
2. 窗口操作
2. 窗口操作(Window Management Classes)
- QMainWindow:主窗口类。
- QDialog:对话框类。
- QMessageBox:消息框类。
- QFileDialog:文件选择对话框。
- QColorDialog:颜色选择对话框。
- QFontDialog:字体选择对话框。
- QInputDialog:输入对话框。
- QWidget:所有窗口部件的基类。
- QDockWidget:可停靠的窗口部件。
- QStatusBar:状态栏,显示状态信息。
- QToolBar:工具栏,包含工具按钮。
- QMenuBar:菜单栏。
- QMenu:菜单,通常包含多个动作项。
- QAction:菜单或工具栏中的操作项。
3. 文件操作
- QFile:用于文件的读写操作。
- QTextStream:用于以文本模式读写文件。
- QDataStream:用于以二进制模式读写数据。
- QDir:用于操作目录(如创建、删除、遍历目录等)。
- QFileInfo:提供有关文件和目录的详细信息。
- QFileDialog:文件选择对话框。
4. 定时器
- QTimer:定时器类,用于创建和管理定时任务。
- QElapsedTimer:用于测量经过时间的定时器。
- QBasicTimer:轻量级的定时器,通常用于自定义事件循环的简单任务。
5. 网络操作
- QNetworkAccessManager:处理网络请求(如 HTTP GET/POST 请求)。
- QNetworkRequest:用于描述网络请求(URL、头信息等)。
- QNetworkReply:表示网络请求的响应。
- QTcpSocket:用于 TCP 客户端通信。
- QTcpServer:用于创建 TCP 服务器,接受客户端连接。
- QUdpSocket:用于 UDP 通信。
- QNetworkSession:管理网络会话。
- QHostInfo:提供主机名和 IP 地址的解析功能。
- QAbstractSocket:TCP 和 UDP 套接字的基类。
- QWebSocket:用于 WebSocket 通信。
- QWebSocketServer:用于创建 WebSocket 服务器。
- QSslSocket:支持 SSL/TLS 的套接字通信类。
那么这里有人就会有疑问,为什么对话框属于界面控件,又是窗口类
对话框的双重角色
-
作为窗口:
- 在 Qt 中,对话框实际上是一个独立的窗口,它会弹出并在屏幕上显示,就像普通的主窗口(
QMainWindow)一样。 - 对话框通常是模态(modal)的,意味着当它弹出时,用户必须处理完该对话框才能回到主窗口。
- 类如
QDialog、QMessageBox、QFileDialog等,都属于对话框类,提供窗口级别的用户交互功能(比如提示信息、文件选择等)。 - 这些对话框都是独立的窗口,与主窗口分开显示,有自己的窗口边框、标题栏、关闭按钮等。
- 在 Qt 中,对话框实际上是一个独立的窗口,它会弹出并在屏幕上显示,就像普通的主窗口(
-
作为界面控件:
- 虽然对话框本质上是一个窗口,但它也是一种控件(Widget),继承自
QWidget。这意味着它拥有与其他控件(如按钮、文本框等)相似的属性和行为。 - 你可以在对话框中放置其他控件(如按钮、标签、文本框),并通过布局管理器来组织这些控件。因此,从用户界面的角度来看,它又是一个用于容纳其他控件的“容器控件”。
- 比如在
QDialog中,你可以放置多个QPushButton、QLineEdit等控件,并通过布局管理器来管理这些控件的排列方式。
- 虽然对话框本质上是一个窗口,但它也是一种控件(Widget),继承自
这里其实是类的继承问题,QObject -> QWidget -> QDialog
以下类既可以看作是窗口,也可以看作是界面控件的一部分:
- QDialog:通用对话框。
- QMessageBox:用于显示消息提示框的对话框。
- QFileDialog:用于选择文件的对话框。
- QColorDialog:颜色选择对话框。
- QFontDialog:字体选择对话框。
- QInputDialog:简化的输入对话框
好的,现在我们已经基本找到了界面控件类,和一些相关操作的类了,当然,这些具体类下面常用的函数可以去查看文档,