长沙网站seo搜索量排名


大数据时代,多数的web或app产品都会使用第三方或自己开发相应的数据系统,进行用户行为数据或其它信息数据的收集,在这个过程中,埋点是比较重要的一环。
埋点收集的数据一般有以下作用:
-
驱动决策:ABtest、漏斗优化、用户增长、bug修复、精准营销、流失用户预警
-
驱动产品智能:智能推荐(千人千面)、场景化提示(私人助理)等
-
驱动安全:风险识别
01、埋点测试分类
埋点测试,首先要了解埋点的分类。埋点主要分为:前端埋点、后端埋点
-
前端埋点:
前端埋点可以理解为web端,app端等在前端触发相关规则时进行的埋点上报等,主要记录的是用户的操作行为,例如点击了哪个按钮,进入了哪个页面等等。
-
后端埋点:
主要是服务端埋点,可以理解为当用户进行相关操作触发相关接口请求或相关业务的时候,进行的埋点上报。
那么两者有什么区别呢?
在实际过程中,有些埋点是不用特意区分前后端的,用户的一个埋点事件在前端埋点或后端埋点都可以实现,但是需要注意的是,在实际埋点上报、数据收集等过程中会有数据丢失的情况,从这个角度来看的话,其实后端埋点要比前端埋点更有优势,前端埋点会因为一些网络问题、适配问题等等容易出现上报异常造成数据丢失且丢失后排查困难,因为前端相关的是没有记录相关操作的,只负责上报,上报成功与否没有记录。
而如果是后端埋点,无论是自己的数据系统还是第三方数据系统都是可以通过自己系统本身相关的数据库查询或记录日志等操作进行埋点数据的校验排查,所以针对一些比较重要的埋点,还是建议以后端埋点为主,必要时通过记录日志或记入数据库等方式对相关数据进行二次记录以便进行数据核实。
02、埋点测试过程
埋点测试的过程有两个比较重要的环节,埋点上报和埋点落库
-
埋点上报:
无论是前端埋点还是后端埋点,有没有正常按照相关规则进行上报,相关的事件名、属性值都是否完整正确上报,这个是需要关注的
-
埋点落库:
埋点上报完的数据是需要存储到数据库当中再进行相关的数据统计、分析、归类等等,除了检查埋点上报,还要看最终数据是否正常落库,相关数据字段是否正常。
03、埋点自动化测试设计
了解了埋点测试的分类和过程,再思考如何针对埋点进行自动化测试。首先埋点自动化测试与其它自动化测试的方案设计在目的层面应该是一致的,是为了更好的进行埋点回归测试,扩大埋点回归的覆盖率,特别是针对一些核心的埋点数据
例如一些埋点数据是转化相关数据,而转化数据直接跟核心业务相关,有些核心业务还会根据转化数据进行营销、销售、业绩等相关统计,埋点数据不准直接影响到这些东西。
那么如何进行埋点自动化测试设计呢?
可以进行分层设计
1. 用户应用层框架-移动端Appium,web端selenium,主要是模拟用户正常的业务操作
2. 数据mock、上报数据收集-通过构造测试数据给到用户应用层使用,并且通过代理抓包收集上报数据,进行上报数据校验(jsonschema校验)
3. 服务端上报及落库查询-通过链接数据数据库或使用相关API,查询测试上报数据是否落库。
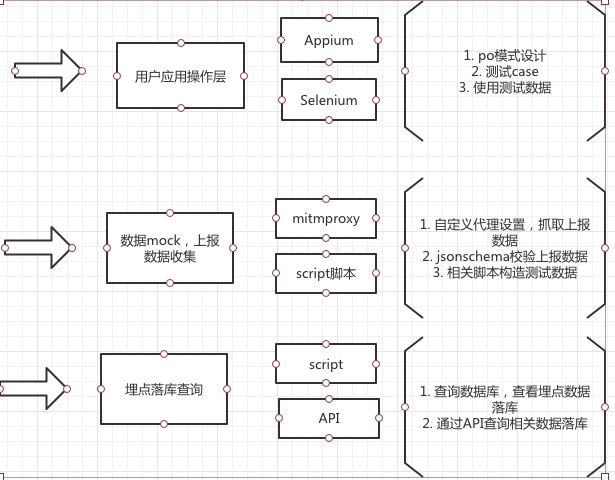
另外,还需要结合Jenkins进行持续集成,每天或每次发版前对所有埋点进行回归测试
今天的分享就到此结束了,如果文章对你有帮助,记得点赞,收藏,加关注。会不定期分享一些干货哦......
最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:
这些资料,对于想做【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!凡事要趁早,特别是技术行业,一定要提升技术功底。希望对大家有所帮助……加入我的学习交流群一起学习交流讨论把!!!!
