wordpress禁止查看源码seo排名技术教程
现象:

网上说的解决方法都是什么到github个人中心setting里面的action设置里面去找。
可这玩意根本就没有!
正确解决办法:
在你的仓库页面,注意是仓库页面的setting里面:
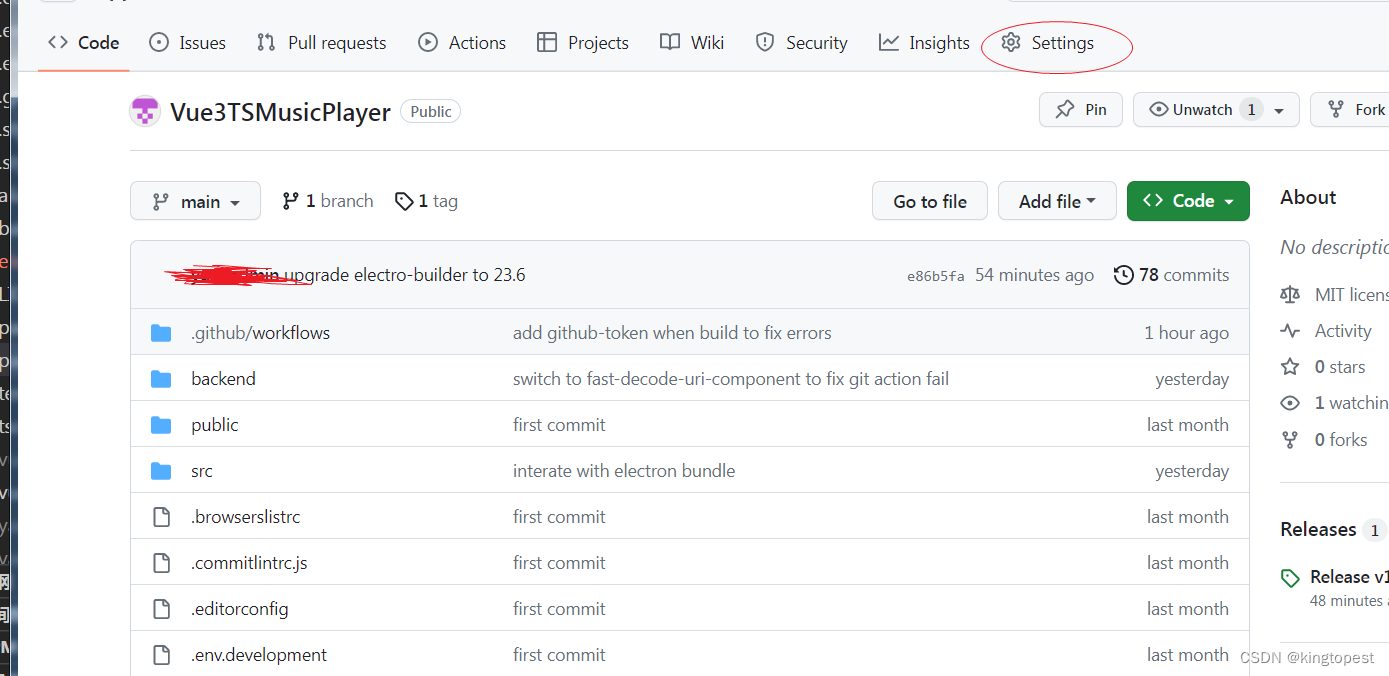
Actions=> General=>Workflow permisssion=> Read and Write permissions

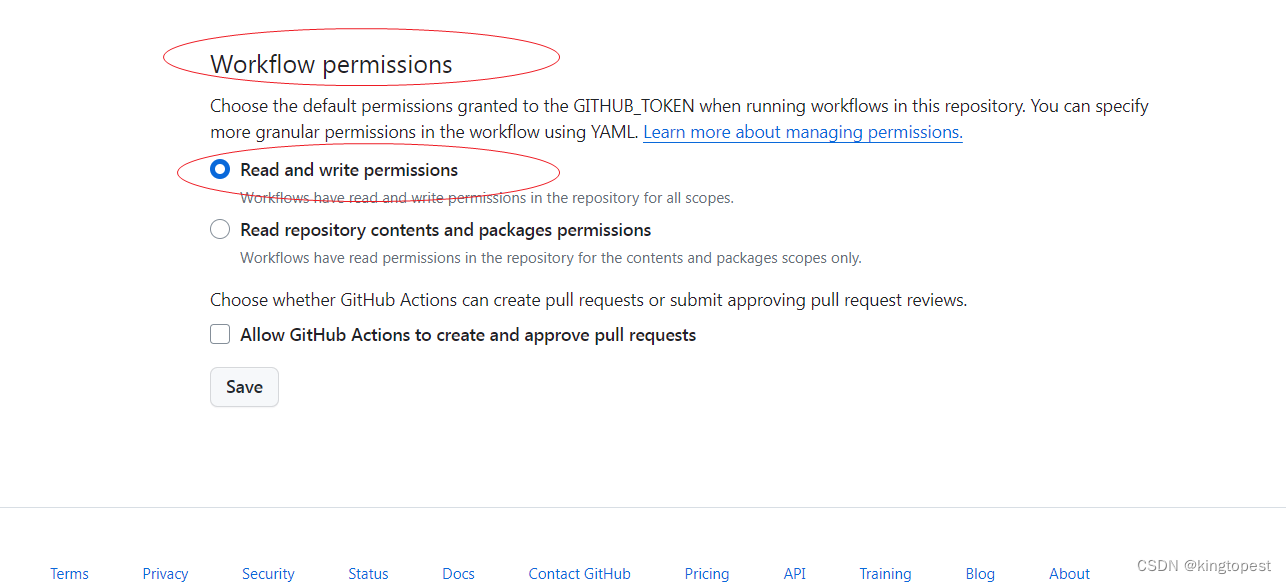
现象:
网上说的解决方法都是什么到github个人中心setting里面的action设置里面去找。
可这玩意根本就没有!
正确解决办法:
在你的仓库页面,注意是仓库页面的setting里面:
Actions=> General=>Workflow permisssion=> Read and Write permissions