网站建设优化石家庄电商运营方案
目录
激活python虚拟环境,更新pip
通过pip 安装tensorflow
确定python版本:
编辑安装tensorflow:
编辑 为什么使用pip安装tensorflow?
激活python虚拟环境,更新pip
命令为python -m pip install --upgrade pip

通过pip 安装tensorflow
确定python版本:
在tensorflow官网(使用 pip 安装 TensorFlow (google.cn))中,我们注意到系统要求,容易让我们忽略的是python版本的要求,目前最新版本的python为3.12.0,在download-windows中找到可以下载安装的3.8或者3.9版本。
可以通过python --version 来检查本地python版本。


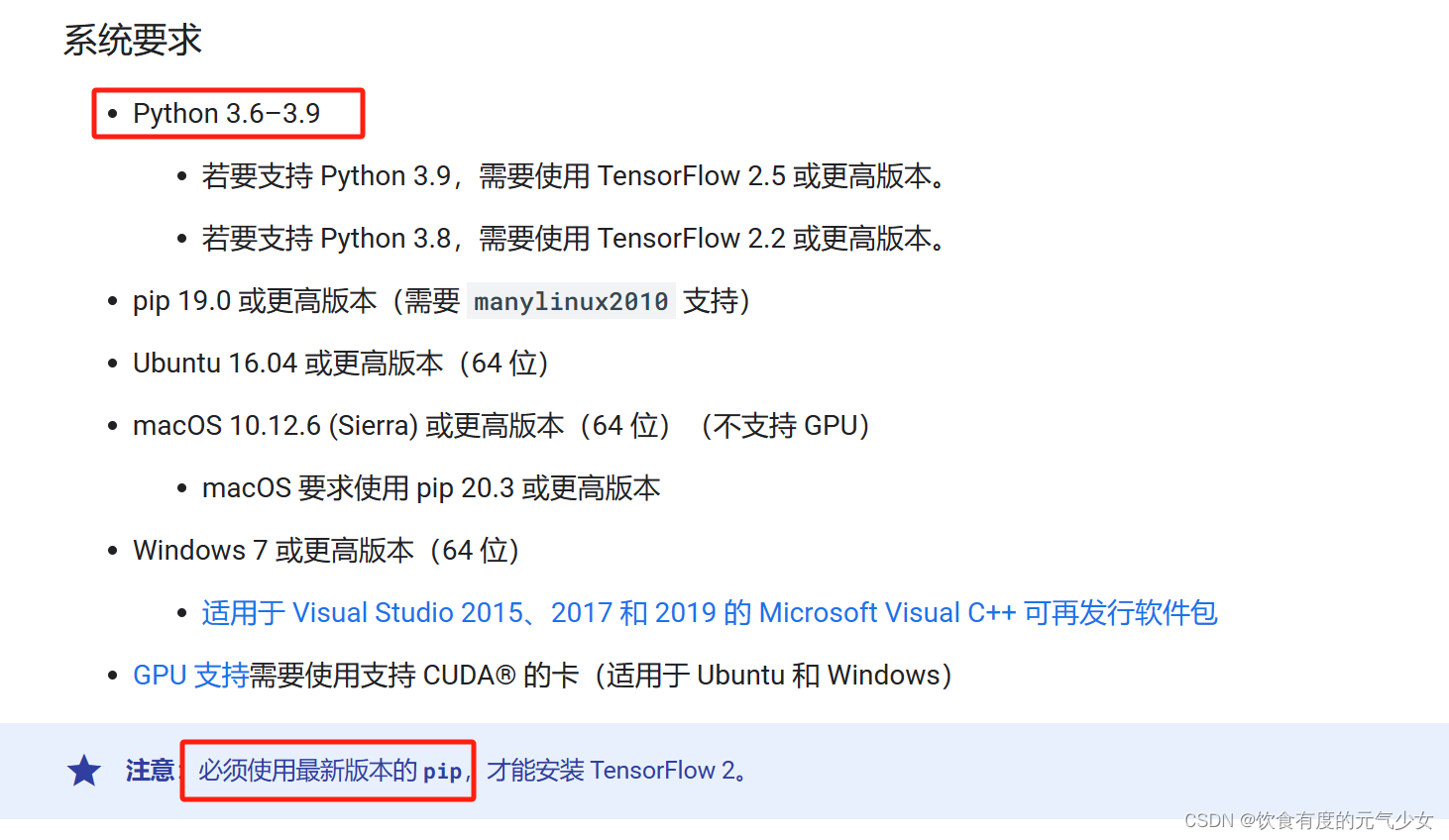 如果安装高版本的python,在安装tensorflow时,会出现报错:
如果安装高版本的python,在安装tensorflow时,会出现报错:
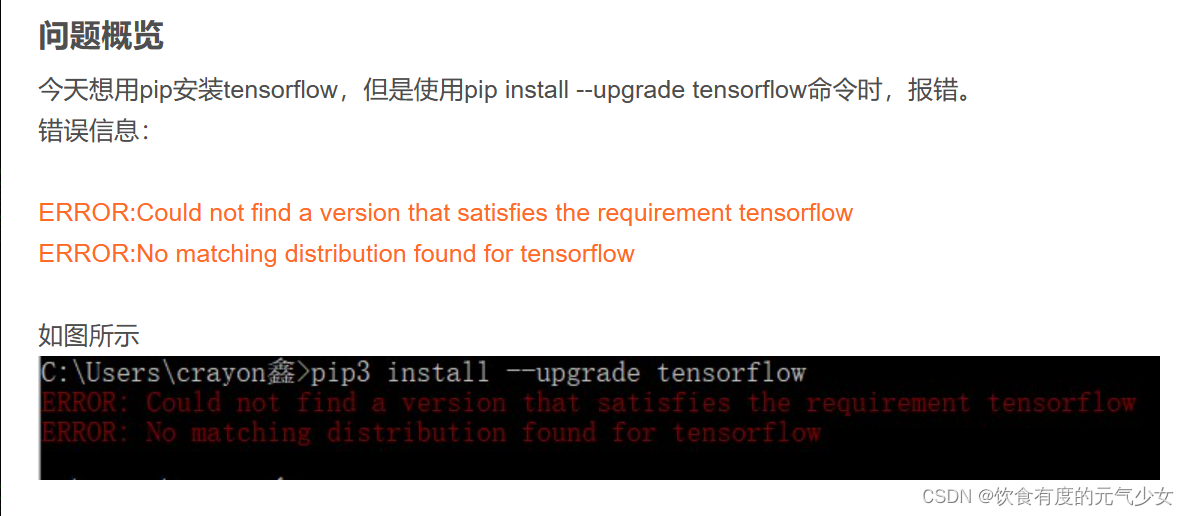 安装tensorflow:
安装tensorflow:
命令 pip install --upgrade tensorflow
 为什么使用pip安装tensorflow?
为什么使用pip安装tensorflow?
之前想要通过R+Python结合使用,在本地计算机使用miniconda安装python,通过命令行安装tensorflow是成功的。但是当通过r语言在服务器上安装tensorflow时,总是安装失败,即使安装成功了,也不能用。
在本地计算机通过r语言安装tensorflow(只限于自己的笔记本电脑,如果是服务器,大概率会失败的。)
#Install Python install.packages("reticulate") library("reticulate") reticulate::install_miniconda() #Install miniconda reticulate::repl_python() #Install pythonreticulate::py_available() #Check if Python is installed successfully# install Python module in R # If you encounter an error, press Ctrl + Shift + F10 to restart R and continue. install.packages("tensorflow") library("tensorflow") install_tensorflow() library("reticulate") reticulate::import("tensorflow")
之前查过原因,有一个原因说是,组装机器系统不完整,tensorflow没有办法安装。
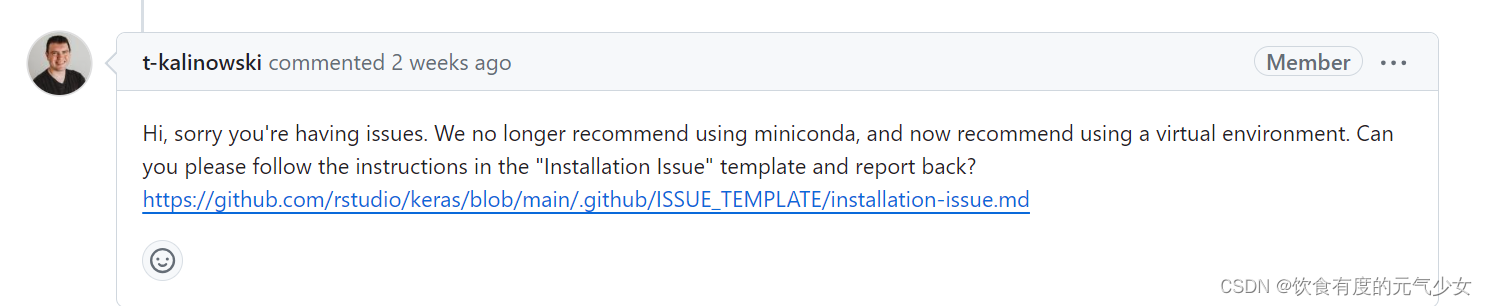
昨天又查到tensorflow作者说,针对安装不成功这个问题,他们不再推荐使用miniconda安装python,继而安装tensorflow,而是推荐在虚拟环境中安装tensorflow。
tensorflow安装不成功提示(trouble installing Tensorflow · Issue #1380 · rstudio/keras · GitHub):

在同一个页面中,tensorflow作者说,推荐使用虚拟环境中安装tensorflow.
参考:
【备忘录】pip安装TensorFlow出错原因及解决办法_error: no matching distribution found for tensorfl-CSDN博客