做网站带来的好处seo优化网页
前言(无重点,安装往后看)
由于在很多人的安利下,说很好用,作者今天花费了4个小时用血的教训总结出来的安装教程,我在安装过程中遇到的最大的问题就是
1. curl: (7) Failed to connect to raw.githubusercontent.com port 443: Connection refused的这个报错
2. hosts文件无法被修改
好在经过不断的尝试和努力,终于解决了这个问题,大家只要跟着我走,保证你会安装成功
但是由于作者能力有限,不对这两款软件进行讲解,仅仅展示安装过程,大家一步一步来,肯定能成功!
1. iTerm2的安装
我们进入这个链接Features - iTerm2 - macOS Terminal Replacement
下面就是网页界面,然后我们点击箭头指向的地方:
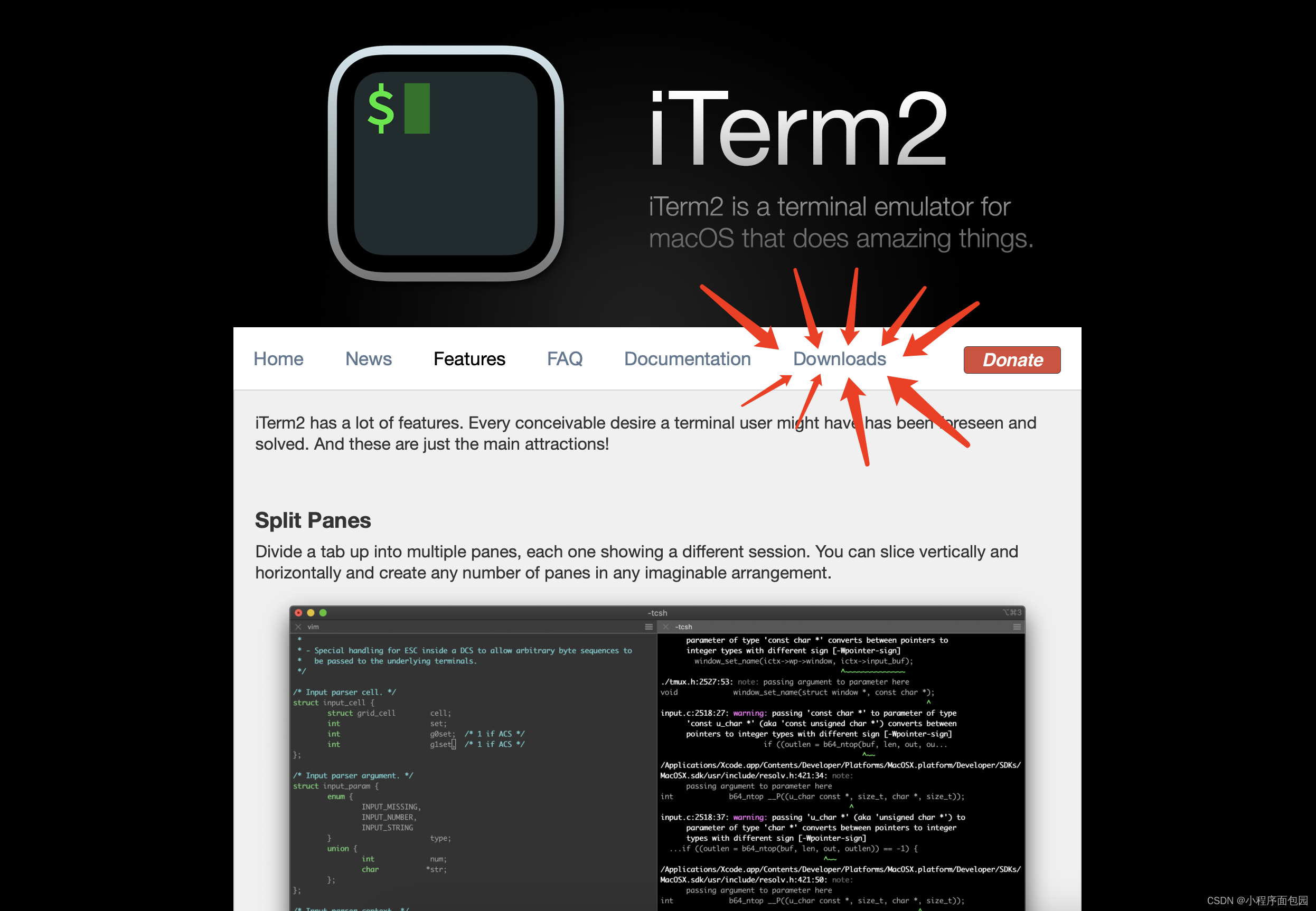
然后下载红色框里面的版本就可以了,反正就是下载最新版本就行。

下载成功后打开就行,因为我们在安装oh-my-zsh之前需要先安装wget命令,所以我们就进行第二步,wget 的安装。
2. wget命令的安装
我们现在是已经安装好了iterm2的,所以现在开始打开这个终端,在终端输入以下代码
先安装home-brew
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"之后进行#wget 安装
brew install wget安装成功之后,再进行我们的oh-my-zsh的安装
3. Oh My Zsh 的安装
我们还是先进入这个网址:Oh My Zsh - a delightful & open source framework for Zsh
点进链接之后来到这个界面,并且点击红色箭头指向的部分:

之后会自动跳转到下图这个地方,这里有两个命令行输入到方法:
1.第 一种是在你安装curl之后,在终端上输入红色1下面的命令安装oh-my-zsh
2. 第二种就是在安装wget之后,在终端上输入红色2下面的命令安装oh-my-zsh
作者在安装这两个测试了一下,最后只有wget让我成功安装好了oh-my-zsh,所以作者在上面只介绍了wget的安装。

我们在安装完wget之后,在终端输入这个代码,也就是上面图片中红色的2
sh -c "$(wget https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh -O -)"当我们出现这个界面的时候,就说明安装成功了
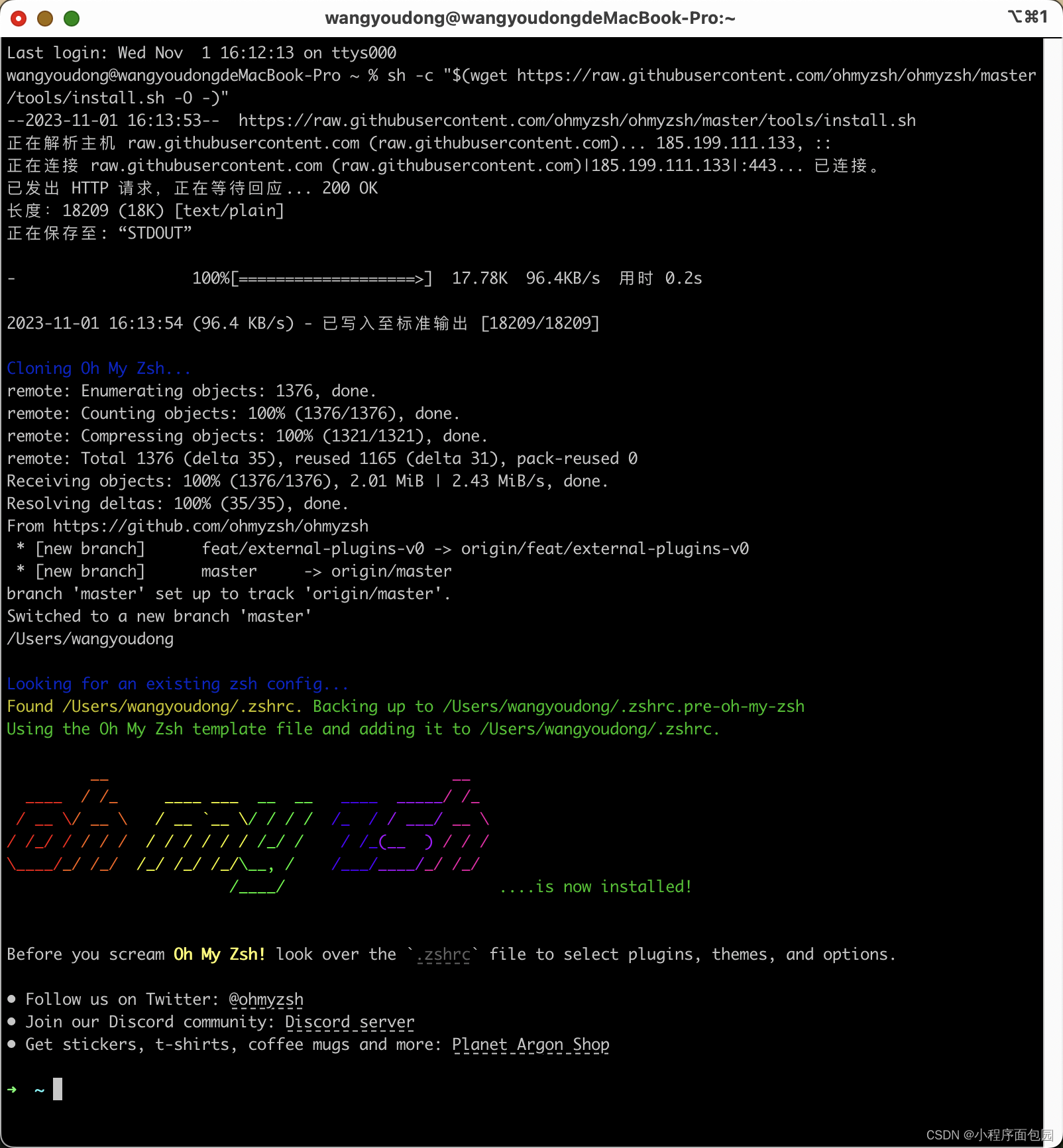
但是我们大部分人都会出现一个错误:
curl: (7) Failed to connect to raw.githubusercontent.com port 443: Connection refused
那下面我们就开始说明解决办法。
3. curl: (7) Failed to connect to raw.githubusercontent.com port 443: Connection refused 的解决办法
作者在多方查询相关资料,也是寻找到了最快的解决办法,让我们一起往下看。
3.1 准备工作1 :打开hosts文件
在桌面上使用shift+command+G,打开前往文件夹,并且输入/pricate进入这个文件夹

找到之后打开红色箭头指向的文件夹,进入

找到hosts文件

3.2 准备工作2 :修改hosts文件 第一步: 找ip地址
我们在找到之后要进行对hosts文件的修改,红色部分是原来没有的,是修改之后的。

我们先打开一个网址ip查询 查ip 网站ip查询 同ip网站查询 iP反查域名 iP查域名 同ip域名
查询一下这个的ip地址:raw.githubusercontent.com
我们选择蓝色框里的任意一个就行,复制出来并且加上这句话
185.199.111.133 raw.githubusercontent.com(要加到hosts文件里)
(在这里多说一嘴,对于同种错误,都可以查找对应的ip来解决)

再将这句话加到hosts文件的末尾就可以了(若没有权限,请看最后的解决办法)

加入之后我们保存,再重新启动iterm2,重新输入下面代码就OK了。
到这里就安装成功oh-my-zsh了。
sh -c "$(wget https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh -O -)"4. hosts不让修改,无权限的解决方法
我们回到这个界面

右键点击etc,找到显示简介,看最下面的共享与权限
我们首先ba 红色圆圈的小锁头打开,再更改wheel和everyone的权限,变成读与写

之后再找到hosts文件,进行同样的操作,这样hosts文件就可以修改了!
至此,安装过程结束,感谢大家,有问题欢迎在评论区提问,作者会尽我所能帮助大家,如果有什么不对的地方,欢迎大家指导!