jsp做的网站站 图标是tomcat的 怎么换如何推广自己的业务
数据供应者与消费者之间往往存在一种矛盾:供应者做了大量的数据治理工作、提供了大量的数据,但数据消费者却仍然不满意,他们始终认为在使用数据之前存在两个重大困难。
1)找数难
企业的数据分散存储在上千个数据库、上百万张物理表中,已纳入架构、经过质量、安全有效管理的数据资产也会超过上万个,并且还在持续增长中。例如,用户需要从发货数据里对设备保修和维保进行区分,以便为判断哪类设备已过保(无法继续服务)提供准确依据,但生成和关联的交易系统有几十个,用户不知道应该从哪里获取这类数据,也不清楚获取的数据是否正确。
2)读不懂
企业往往会面对数据库物理层和业务层脱离的现状,数据的最终消费用户无法直接读懂物理层数据,无法确认数据是否能满足需求,只能寻求IT人员支持,经过大量转换和人工校验,才最终确认可消费的数据,而熟悉物理层结构的IT人员,并不是数据的最终消费者。例如,当需要盘点研发内部要货情况的时候,就需要从供应链系统获取研发内部的要货数据,但业务用户不了解该系统复杂的数据存储结构(涉及超过40个表、1000余个字段),也不清楚每个字段名称下所包含的业务的含义和规则。
企业在经营和运营过程中产生了大量数据,但只有让用户“找得到”“读得懂”,能够准确地搜索、便捷地订阅这些数据,数据才能真正发挥价值。
数据地图(DMAP)是华为公司面向数据的最终消费用户针对数据“找得到”“读得懂”的需求而设计的,基于元数据应用,以数据搜索为核心,通过可视化方式,综合反映有关数据的来源、数量、质量、分布、标准、流向、关联关系,让用户高效率地找到数据,读懂数据,支撑数据消费。
数据地图作为数据治理成果的集散地,需要提供多种数据,满足多类用户、多样场景的数据消费需求,所以华为公司结合实际业务制定了如图所示的数据地图框架。
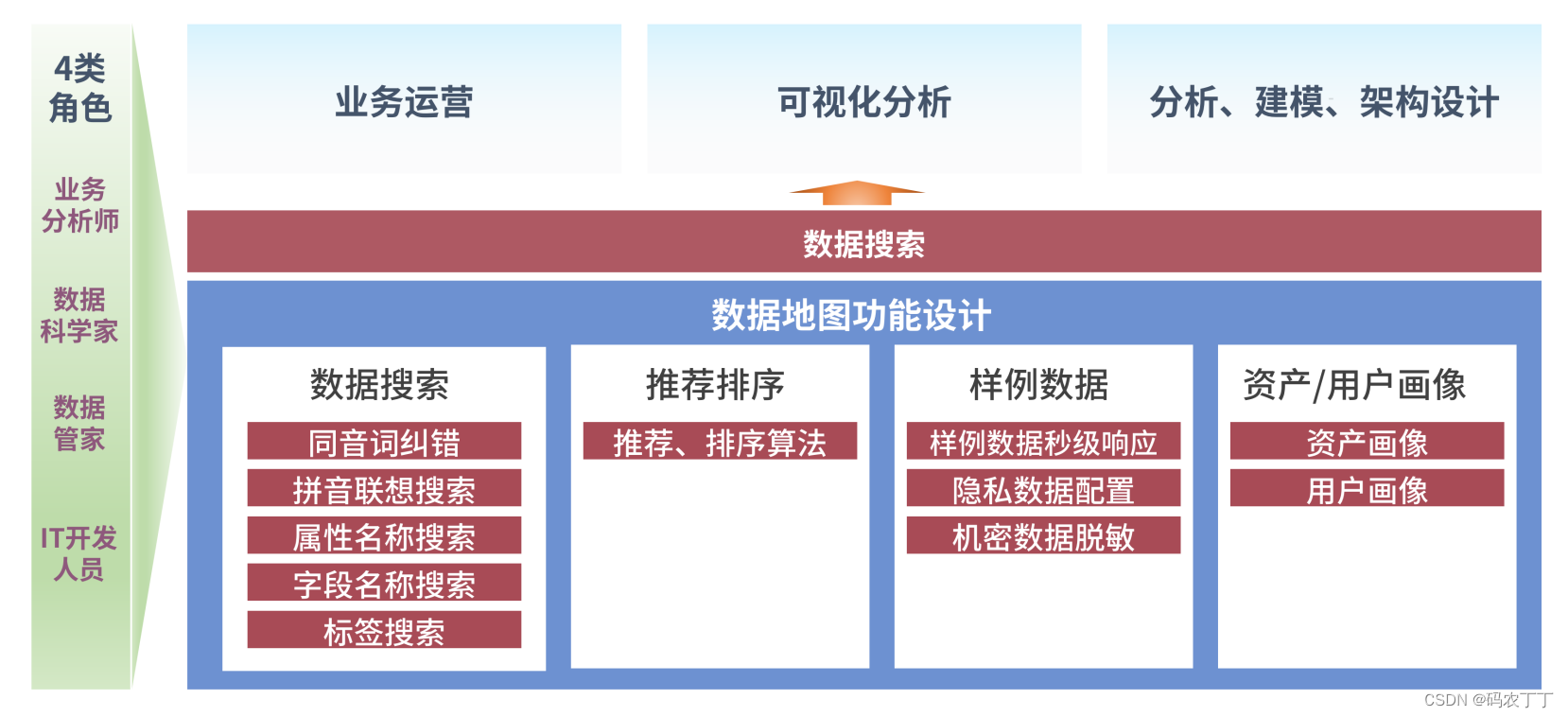
数据地图为四类关键用户群体提供服务。
1)业务分析师
业务分析师是企业最大的数据消费群体,具有良好的业务背景,有些数据分析师本身就是业务人员,了解业务需求实质,理解业务含义,与利益相关者有良好的沟通。通过对数据的识别,借助数据分析工具,生成可供阅读的图表或者仪表板,使用分析结果识别问题,支撑决策。对数据可信度、业务含义、数据定位有强烈诉求。
2)数据科学家
数据科学家是指能采用科学方法、运用数据挖掘工具对复杂异构的数字、符号、文字、网址、音频或视频等信息进行数字化重现与认识,并能进行新的数据洞察的工程师或专家。对业务含义、数据关系有强烈诉求。
3)数据管家
公司数据管理体系的专业人员,负责协助数据Owner对数据信息架构进行管理,包括定义信息架构中的责任主体、密级/分类,为数据安全管理提供重要输入。通过信息架构设计,统一业务语言,明确管理责任,设定数据质量标准,拉通跨领域信息流,支撑运营和决策。对数据质量、信息架构、数据关系有强烈诉求。
4)IT开发人员
主要为企业的数据仓库开发人员,通过对物理表进行定位、识别和ETL,创建满足业务分析师或者应用平台所需要的模型或维表。对数据定位、数据关系有强烈诉求。