无锡哪个网站好深圳seo外包
1. 简介
自动化测试大概可以分三个层次:
1. 手工测试用例转换成自动化测试脚本的过程
2. 能设计自动化测试框架,至少能够维护自动化测试框架。
3. 流程自动化方案设计,例如,一键打包,自动开始测试,自动发送测试报告,自动运维部署上线等。
通过前边文章的基础和练习讲解,学习到这个时间节点,应该是完整介绍了手工测试用例装换成自动化测试脚本这一个初级水平,学到这里,你已经具备了能够编写自动化测试脚本的能力。
在开始介绍设计简单的自动化测试框架之前,在这个节点,插入一个新章节,主要是介绍一些设计框架的前提技能和基本Python编写代码的能力。这些能力包括但不限于以下内容:
1. 主流Python开发IDE工具的基本使用,例如Pycharm
2. Python中模块,类和对象的具体代码讲解。
3. Selenium 常见方法的二次封装。
4. 自定义方法的封装和方法的调用-浏览器引擎类。
5. Python读写配置文件介绍
6. Python如何获取系统时间和时间的格式化处理。
7. Python中常见字符串切割处理。
8. Python自定义一个日志生成方法封装。
9. Selenium中一个截图方法的封装。
10. Python中继承的使用。
通过介绍以上进阶技能学习后,我们才可以,或者有能力去思考和动手去设计一个简单的自动化测试框架。
2. pycharm安装
在Python开发过程中,比较流行,很优秀的一款IDE工具-PyCharm,这里关于它的介绍就一句话,它就相当于Java开发中的Eclipse软件一样。有些人说,Eclipse上可以通过安装插件扩展来支持Python的代码编写,虽然可以这样,但是我强烈建议,你本来就是
学习,为啥不选择一个符合大众的选择工具呢,不管你用没有用户Eclipse,在这里,你将要用PyCharm进行自动化测试框架的开发。
安装很简单,直接下载安装
3. pycharm简单使用
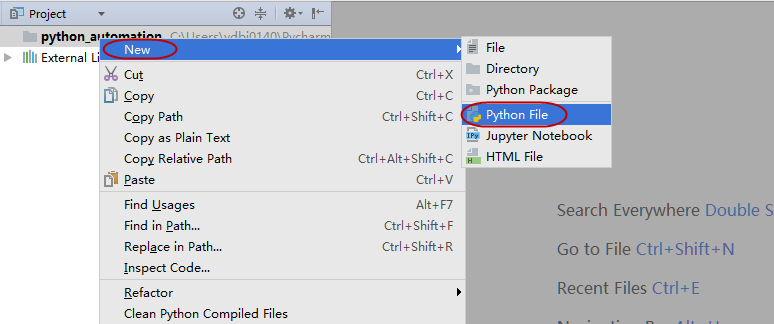
3.1 创建一个包,或者文件夹,或者python文件
如何创建一个包,或者文件夹,或者python文件,请看下图:
3.2 设置工作面板中的字体
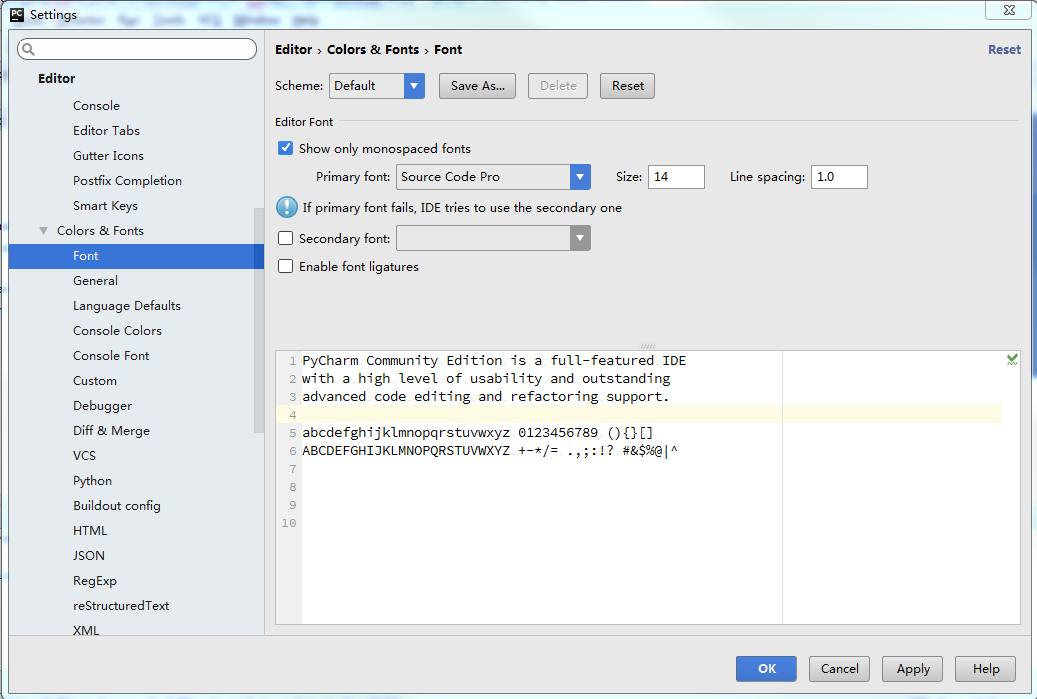
如何设置工作面板中的字体:
点击File-Settings,调出设置面板:
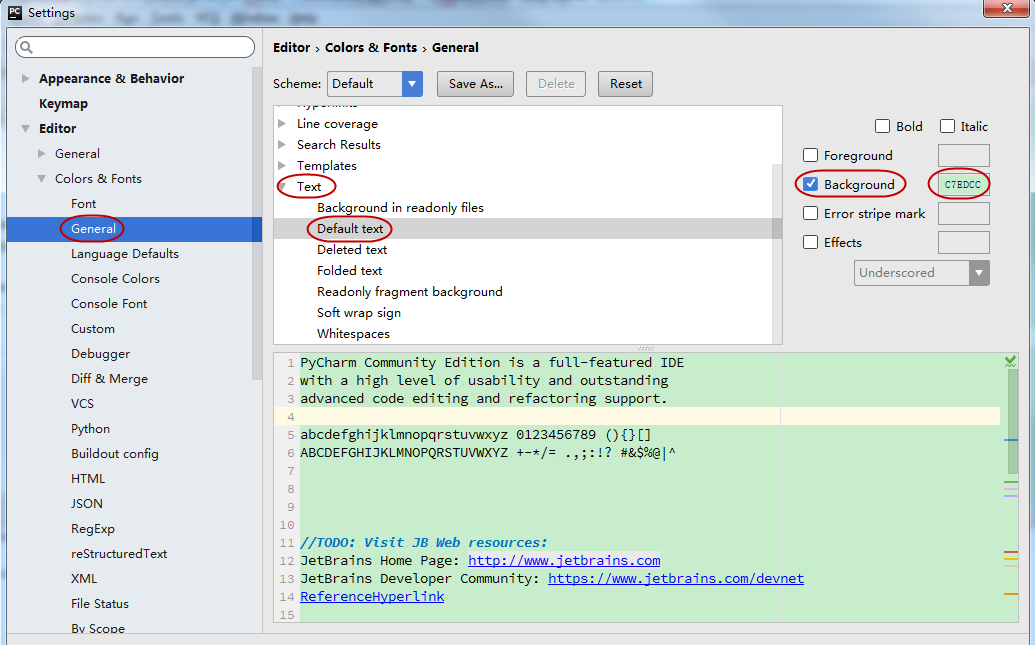
3.3 设置代码面板中背景颜色
如何设置代码面板中背景颜色成绿豆色,据说绿豆色养眼,护眼,绿豆色用RGB表示:C7EDCC
3.4 多行注释快捷键
在PyCharm如何多行注释: 选中多行代码,ctrl+/
3.5 运行代码
在PyCharm如何运行代码:点击菜单栏绿色三角 或者,在代码面板,右键,选中Run xxx
4. Python中类/函数/模块的简单介绍和方法调用
前边小章节介绍了PyCharm的基本使用,接下来我们的脚本代码都在这个PyCharm这个编辑器里写。好处有很多,项目文件结构层次清晰,写代码的时候会自动化提示和补全。这里,我们在昨天创建的项目下,新建一个包,然后在包下面新建一个demo.py文
件。抄写以下代码到你的环境里,尝试运行下,看看有没有问题。
关于Python中类和函数及方法的调用,我们写在这个demo.py文件,具体代码如下:
4.1 代码实现:
4.2 参考代码:
# coding=utf-8class ClassA(object):string1 = "这是一个字符串。"def instancefunc(self):print ('这是一个实例方法。')print (self)@classmethoddef classfunc(cls):print ('这是一个类方法。')print (cls)@staticmethoddef staticfun():print ('这是一个静态方法。')test = ClassA() # 初始化一个ClasssA的对象,test是类ClassA的实例对象
test.instancefunc() # 对象调用实例方法test.staticfun() # 对象调用静态方法test.classfunc() # 对象调用类方法print (test.string1) # 对象调用类变量ClassA.instancefunc(test) # 类调用实例方法,需要带参数,这里的test是一个对象参数
ClassA.instancefunc(ClassA) # 类调用实例方法,需要带参数,这里的ClassA是一个类参数
ClassA.staticfun() # 类调用静态方法
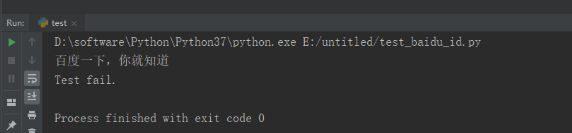
ClassA.classfunc() # 类调用类方法4.3 运行结果:
运行代码后,控制台打印如下图的结果
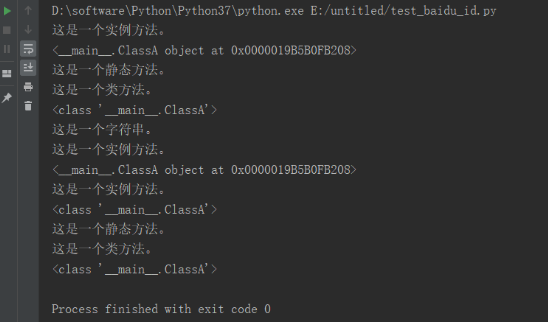
备注:
先运行下代码是否会报错,然后尝试自己去理解下。主要有以下几点内容
1. 类的定义,class开头的就表示这是一个类,小括号里面的,表示这个类的父类,涉及到继承,默认object是所有类的父类。python中定义类,小括号内主要有三种:1. 具体一个父类,2. object 3. 空白
2. 函数或方法的定义, def开头就表示定义一个函数,方法包括,实例方法,类方法,静态方法,注意看类方法和静态方法定义的时候上面有一个@标记。
3. 对象调用方法和类调用方法的使用。
这篇讲的东西,确实比较难理解。如果学过java的人,可能会好理解类和对象,以及面向对象的概念。Python同时支持面向过程变成和面向对象编程,所有python中也有类和对象等概念。一般来说,概念的东西比较绕,如果你Python基础没有看到这部分,那就回去学习关于这块的介绍。如果有看过了,还是不理解,我只能告诉你,继续学下去,你现在哪怕死记住这些概念和他们的基本使用。等到后面,框架设计部分,你会慢慢体会到这些基本概念的实际用法,你跟着写了代码后,会有助于你自己
的理解和提高。
最后,来说下python中的模块,在python中,你新建一个demo.py文件,那么一个.py文件可以说是一个模块,一个模块中,可以定义多个class,模块中也可以直接定义函数。和java一样,访问不同包下的类和方法之前,需要导入相关路径下的包。例如from
selenium import webdriver 这个导入语句,我们知道webdriver这个接口是在selenium的模块下。
本小章节的学习目的,就是会用函数或者类来编写我们之前写过的脚本。那么接下来就来体验一下吧。
5. 趁热打铁
这里以下用百度搜索举例,模仿上面用类调用实例的方法来写这个脚本,注意这里self指的是当前BaiduSearch这个类本身:
5.1 代码实现:
5.2 参考代码:
# coding=utf-8import time
from selenium import webdriverclass BaiduSearch(object):driver = webdriver.Chrome()driver.maximize_window()driver.implicitly_wait(10)def open_baidu(self):self.driver.get("https://www.baidu.com")time.sleep(1)def test_search(self):self.driver.find_element_by_id('kw').send_keys("selenium")time.sleep(1)print (self.driver.title)try:assert 'selenium' in self.driver.titleprint ('Test pass.')except Exception as e:print ('Test fail.')self.driver.quit()baidu = BaiduSearch()
baidu.open_baidu()
baidu.test_search()5.3 运行结果:
运行代码后,控制台打印如下图的结果